事务消息组件的套路
Posted ctgulong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了事务消息组件的套路相关的知识,希望对你有一定的参考价值。
事务消息组件的套路
本文总结一些互联网产品的服务端关于处理事务消息的套路
套路1:最终一致性消息模型
该方案关键是要有个消息表。另外,一般会有个队列,而且我们一般都会假设这个MQ不丢消息。
基本思路如下
- 消息生产方
需要额外建一个消息表,并记录消息发送状态。消息表和业务数据要在一个事务里提交(有时实现时为了简单,可以只是增加一个字段。新增字段会跟业务强耦合)
- 消息消费方
需要处理这个消息,并完成自己的业务逻辑。
如果本地事务处理成功,那发送给生产方一个confirm消息,表明已经处理成功了。
如果处理失败,可以发送给生产方一个失败消息,或者记录本地表。以后重试。
生产方定时扫描本地消息表,把还没处理完成的消息重新发送一遍。如果有其他的对账补账逻辑,这一步也可以省略。
整体流程如下图所示:
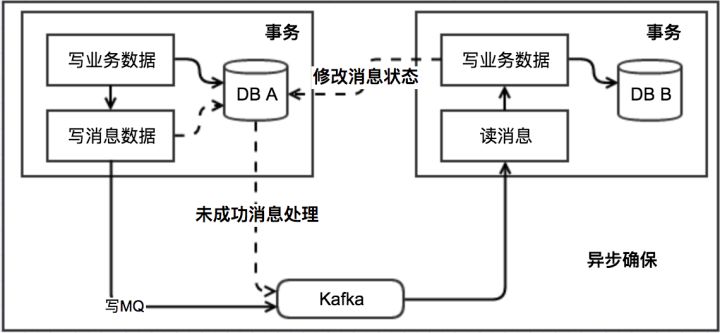
对一致性要求不高的或者有其他兜底方案的场景(比如较为频繁的对账补账机制),我们就不需要关心消息的confirm等情况,只要扔给消息,就认为OK,一般也是可取的。
但是这个方案存在一个小问题
如果发送消息失败,发送方并不知道是消息中间件真的没有收到消息呢,还是消息已经收到了只是返回response的时候失败了
如果是已经收到消息了,而发送端认为没有收到,执行update db的回滚操作。则会导致发送方事务回滚,接受方却把后续逻辑做掉了
把网络调用放在DB事务里面,可能会因为网络的延时,导致DB长事务,存在风险
套路2:事务消息模型
国内常用方案
事务消息与上面提到的最终一致性模型一致,只不过是把记录消息发送状态这一步在中间件内部做掉了,从而无需业务方针对每个业务自己手动实现。
具体的实现如下图所示。
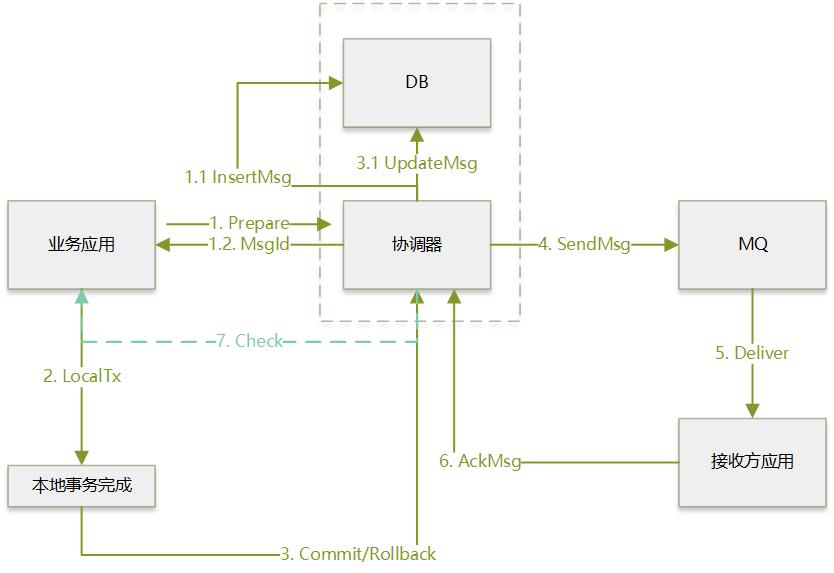
现在的步骤如下:
业务应用把要发送的消息给协调器
1.1 协调器在他自己的DB中记录下这条消息
1.2 协调器返回对应的msgid
- 业务应用自行本地事务更新DB
业务系统如果本地事务执行成功,告诉协调器这条消息Commit,如果本地事务执行失败,则rollback
3.1 协调器更新自己的数据库,标记消息已经Commit/Rollback
- 协调器对于成功submit的消息,开始往MQ进行投递,等待ack,如果一段时间没有收到ack,会继续投递该消息
- MQ将消息投递给接收方,接收方执行事务更新DB
- 接收方应用给协调器做ack,告诉这条消息消费成功.如果长时间没有收到ACK,协调器重投到MQ,这里需要接受方做幂等实现
如果协调器没有收到Commit/rollback,则会询问业务应用消息的状态,是要Commit还是Rollback
对于网易内部的TMC来说,1、3、7三步都是由dubbo实现的(7走的Dubbo的泛化调用)。
阿里的Rocketmq则是做在了产品内部,不依赖外部实现。
对比而言,方案2的最大不一样就是把“扫描消息表”这个事情,不需要业务方做,消息中间件帮着做了。
至于消息表,其实还是没有省掉。因为消息中间件要询问发送方,事物是否执行成功,还是需要一个“变相的本地消息表”或者说业务自己的业务表有对应的信息,记录事物执行状态。
KAFKA的事务消息实现方案
Kafka的transaction最开始是给kafka steaming实现exactly once语义设计的,后面又有一些扩展。
Kafka的实现方案(不考虑kafka streaming的情况下,kafka streaming对消费者有处理)对比上面是没有回查步骤的,同时消费者也需要业务代码来保证幂等。
流程图如下:
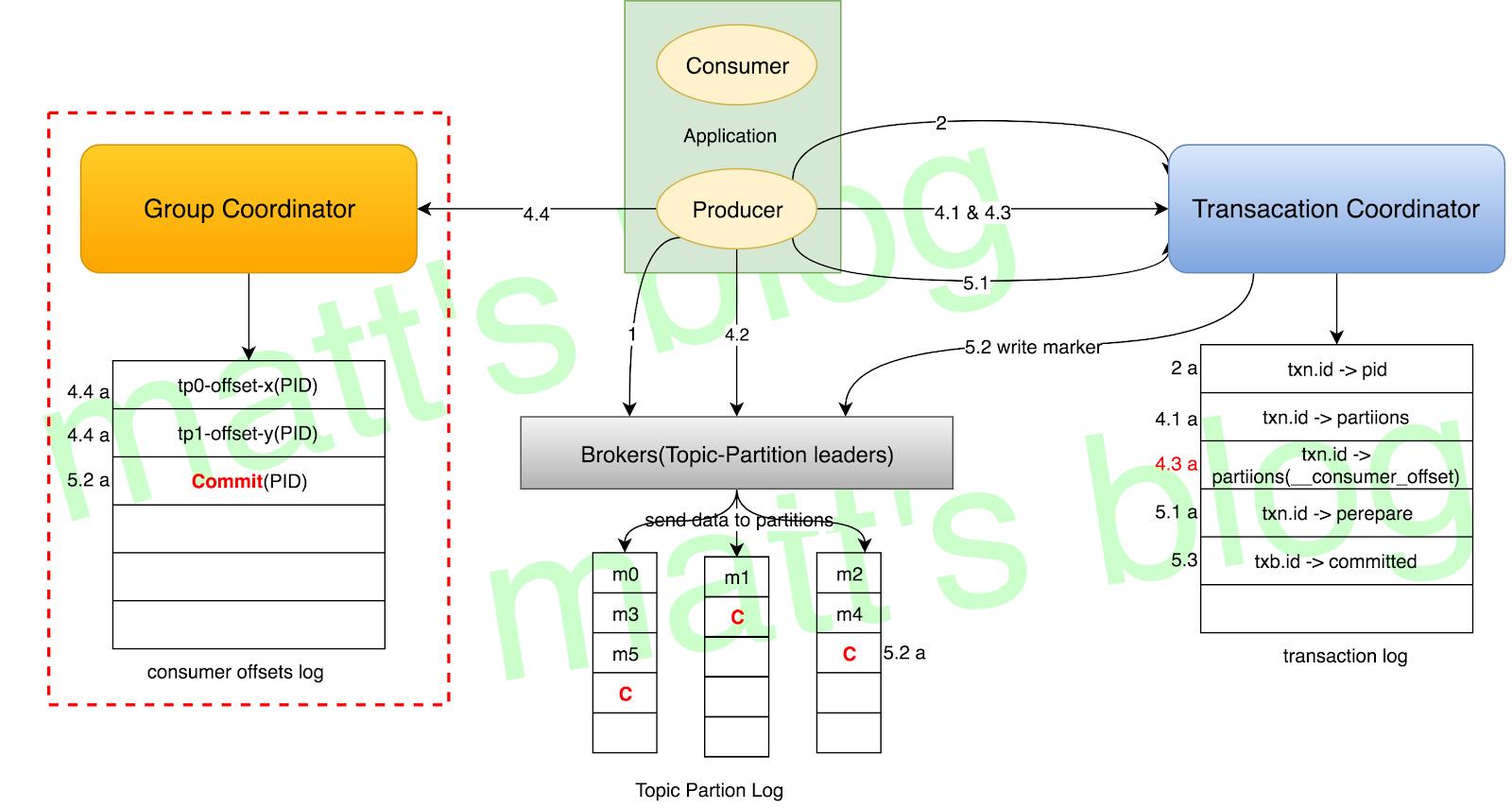
上图来自matt的博客
KAFKA的事务消息具体实现比较复杂,简单来说分为如下几个步骤:
- 生产者像事务协调器注册自己的TransactionalID,这个ID需要保证每台生产者是唯一的。这时如果对应的TransactionalID的机器有没有结束的transaction,会直接被终止。
- beginTransaction是本地做的,对于服务端没有交互
- 向协调器注册要发消息的partition(要解决跨Topic,跨Partition的事务,对应上图4.1a,协调器开始写ongoing的txLog到Transaction_Log的内部topic中)
- 正常发送消息到对应的partition去
- 调用commit/abord到协调器,协调器开始[两阶段提交]
- 协调器写prepare消息到Transaction_Log,这时就算提交了。然后再会给发送到的partition后面补一个不可见的commit消息(主要是用来处理read committed),然后会在写一个commited到到Transaction_Log。到这里就算一个事务结束。
由于这个方案没有引入一个唯一的消息ID(非kafka streaming 模式),且没有回查机制,对于方案1中的最后两个问题也是没有解决。
Kafka自己的kafka streaming则是需要把消费源头的offset作为transaction的一部分(会写到到Transaction_Log里)提交给协调器来实现幂等。而对接一般的外部业务系统,则没有对应机制可以做这件事。
下面是相关的资料:
matt33的博客(中文)写的很详细,推荐一看
以上是关于事务消息组件的套路的主要内容,如果未能解决你的问题,请参考以下文章