吴恩达深度学习:2.11向量化
Posted bigdata-stone
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吴恩达深度学习:2.11向量化相关的知识,希望对你有一定的参考价值。
1.什么是向量化?
在logistic 回归中,你需要计算z=w^Tx+b,w是列向量 ,x也是列向量,w和x都是R内的nx维向量
在python中的一个非向量实现:
for i in range(n-x):
z+=w[i]*x[i]
z+=b
这种形式的计算很慢,对比下向量化的实现会直接计算W^TX,在numpy中,z=np.dot(w,x)是在计算W^TX后面直接加上b,计算的速度非常快
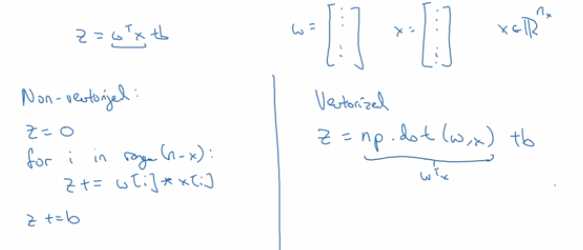
(1)创建一个向量a
import numpy as np a=np.array([1,2,3,4]) print(‘a=‘,a)
a= [1 2 3 4]
(2)比较向量化版本和非向量化版本时间消耗的值:
import time #创建一个一百万维度的随机数组 a=np.random.rand(1000000) b=np.random.rand(1000000) tic = time.time() c= np.dot(a,b) toc=time.time() print(‘vectorized version‘,str(1000*(toc-tic))+‘ms‘) c=0 tic = time.time() for i in range(1000000): c+=a[i]*b[i] toc = time.time() print(‘for loop=‘,str(1000*(toc-tic))+‘ms‘)
以上是关于吴恩达深度学习:2.11向量化的主要内容,如果未能解决你的问题,请参考以下文章