支付宝支撑2135亿成交额的数据库架构原理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了支付宝支撑2135亿成交额的数据库架构原理相关的知识,希望对你有一定的参考价值。
OceanBase的SQL优化器和分布式并行执行
摘要:本文主要介绍蚂蚁金服自主研发的通用关系型数据库OceanBase,OceanBase采用了分布式架构,其通过技术创新在普通PC服务器集群上实现了更好的可靠性、可用性和可扩展行。本文中,蚂蚁金服OceanBase团队资深技术专家潘毅(花名:柏泽)为大家介绍了OceanBase,并分享了SQL优化器,分布式事务的执行逻辑等内容,为大家全面展现OceanBase底层事务引擎的技术创新。
一、OceanBase简介
OceanBase是蚂蚁金服自主研发的通用关系型数据库,其采用了分布式架构,目前支撑了蚂蚁金服全部核心链路系统。
为什么要开发OceanBase
数据库作为基础软件,研发耗时较长且投入较大,那么,蚂蚁金服为什么不能采用现成的方案,如商业数据库或者开源数据库呢?曾经,阿里巴巴拥有亚洲最大的Oracle集群,但是随着互联网业务的发展,尤其是近十年的发展非常迅速,阿里每年的流量呈指数型上升,而且在某些特定日期流量会出现激增,这也是互联网行业与传统银行、电信等行业在数据库应用方面的不同。传统行业可以制定未来几年的规划,如客户规模、业务量等,这些在一定程度上都是可预测的。但是互联网行业则不同,互联网行业的流量变化非常快,一方面使用商用数据库很难进行迅速扩展来应对阿里巴巴飞速增长的规模;另一方面,传统数据库的可靠性、高可用性等都需要依靠极其昂贵的硬件来实现,成本将会非常高昂。同时,阿里巴巴在高峰和平峰流量差别巨大,因此通过硬件实现特殊日期的高流量支持会造成严重的资源浪费。综上所述,现有的商业数据库并不能很好的支持阿里巴巴的整个互联网产业。而采用开源数据库同样也会导致一系列的问题,以mysql为例,第一点,互联网产业的业务流量大,且并发高,需要每一个查询都要在极短的时间内执行,因此对于通用数据库而言,必须要掌握核心的代码才能保证稳定的业务需求。第二点,金融行业需要具备强大的分析、查询能力的数据库,而MySQL在分析查询方面的能力比较薄弱,无法满足业务需求。出于以上原因,蚂蚁金服需要开发一款数据库来满足自身的业务需求。
二、OceanBase架构
该部分将从集群拓扑、分区&分布式协议、存储引擎三个部分介绍OceanBase的架构设计。
1. 集群拓扑
多副本:一般部署为三个子集群,每个子集群由多台机器组成,数据存储在不同的集群中。
全对等节点:每个节点的功能对等,各自管理不同的数据分区。
不依赖共享存储:共享存储的价格较为昂贵,故采用本机存储的方式。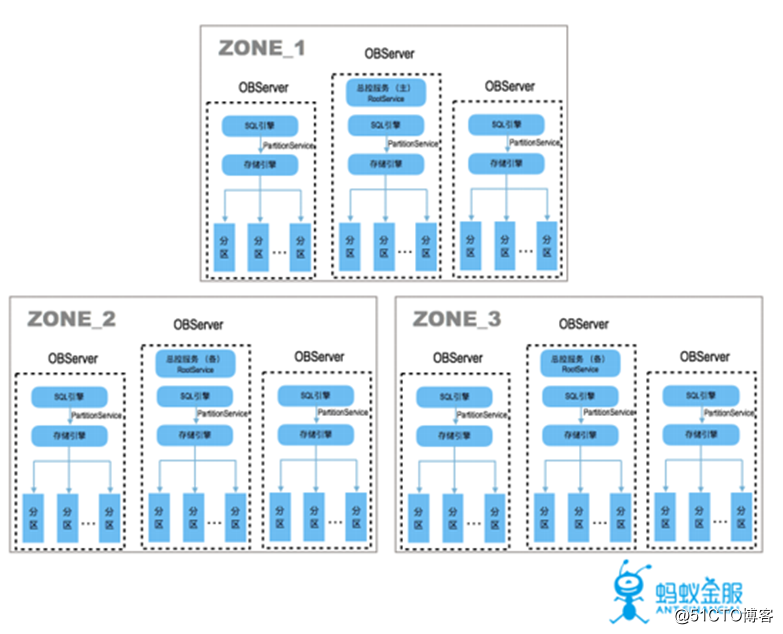
2.分区&分布式协议
数据分区:支持数据分区,每一个数据以分区为单位作为管理组,各分区独立选主,写日志。
高可用&强一致:通过PAXOS协议保证数据(日志)同步到多数机器,发生故障时自动切主。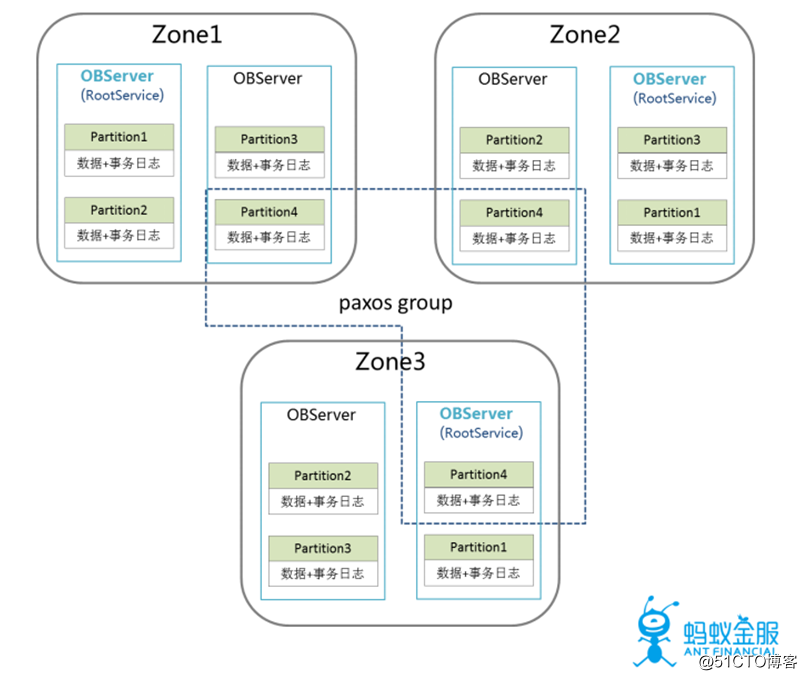
3. 存储引擎
OceanBase采用的存储引擎是经典的LSM-Tree架构,数据主要分为两个部分,分别是是存储于硬盘的基线数据(SSTable)以及存储于内存的增量数据(MenTable)。在该存储引擎中,所有数据的增删改操作都会在内存中进行,并形成增量数据,每隔一段时间将增量数据和基线数据进行合并,来避免对于SSD的随机写。因为对于数据库的操作为全内存操作,所以DML操作的效果非常好,但如果某一段时间的数据修改操作非常多,数据量过大,导致内存溢出,在这种情况下OceanBase提供了相应的解决方案,即转储操作,转储会将数据移动至硬盘上,但不会进行数据的合并操作,在后续合并时,会同时对增量数据,基线数据和转储数据一起进行合并。可以看出这个架构会面临一个很大的挑战,即在进行增删改的操作后,再进行查询操作,可能需要对基线数据和增量数据进行融合,因此在该架构下,读操作可能会受到一定的时间惩罚,这也是SQL优化器需要进行考虑的问题。事实上如果优化器不是基于自身架构和业务需求来进行开发的,可能不会获得良好的效果,这也是为什么要自研数据库的另一个理由。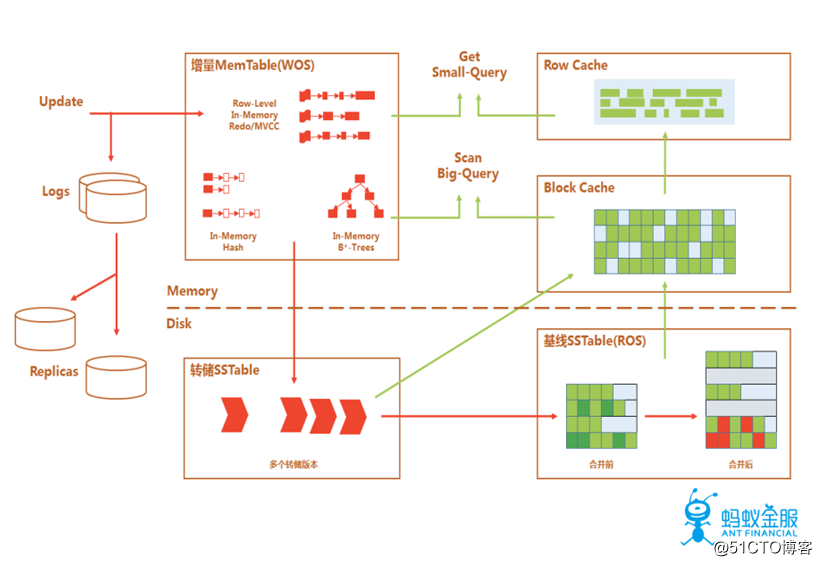
三、SQL优化器
SQL优化的目标是最小化SQL的执行时间(计划生成+计划执行),该部分主要会从OLTP(Online Transaction Processing)和OLAP(Online Analytical Processing)两个方面进行SQL优化的介绍。对于数据量巨大的查询来说,计划执行往往占据大部分的时间,但是对于很多数据量较小的查询,更多的要考虑计划生成的优化方案。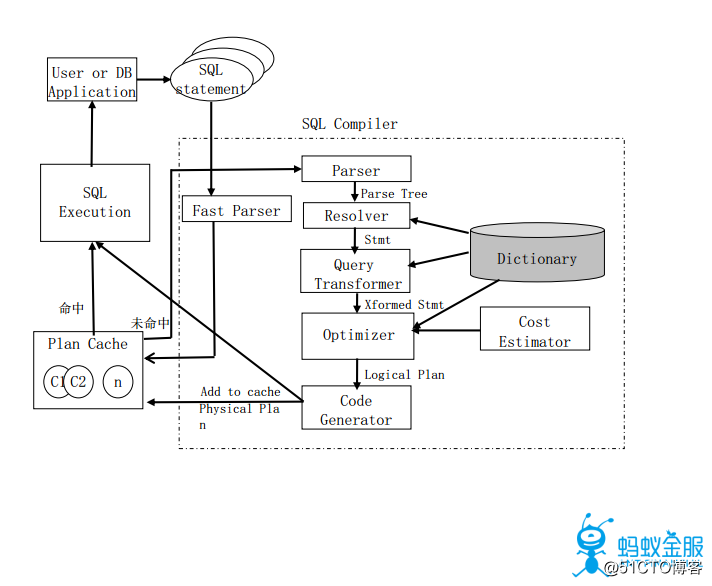
1.基于LSM-Tree结构的代价优化器
OceanBase优化器是基于经典的System R模式,主要进行两个阶段的优化。第一阶段是生成基于所有关系都是本地的最优计划,主要考虑的是CPU和IO的代价;第二阶段是并行执行优化,考虑的是CPU,IO,Network和Overhead的代价。同时,代价模型也需要考虑LSM-Tree结构的特点,比如进行MemTable和SSTable的数据融合,不同表的代价可能不同,因此代价需要采用动态采样计算;系统为分布式share nothing系统;索引回表操作会有额外的代价开销,使用的是逻辑的rowkey而不是物理的rowid,因此回表的时间消耗会增加等,这些都是优化器需要考虑的因素。
2.优化器的基本能力
优化器主要包括两种类型,分别是逻辑优化器和物理优化器,逻辑优化器主要做查询改写等操作的优化,比如基于规则和基于代价的优化,物理优化器主要对连接顺序,连接算法,访问路径进行优化,同时会考虑到Meta Data,比如统计信息,表分区信息。当有了统计信息和代价模型后,就能估算出模型的执行代价,然后选择出代价最好的模型进行相应的操作。而计划管理模块,对于OLTP的意义更加重要,可以更好的对短查询进行优化。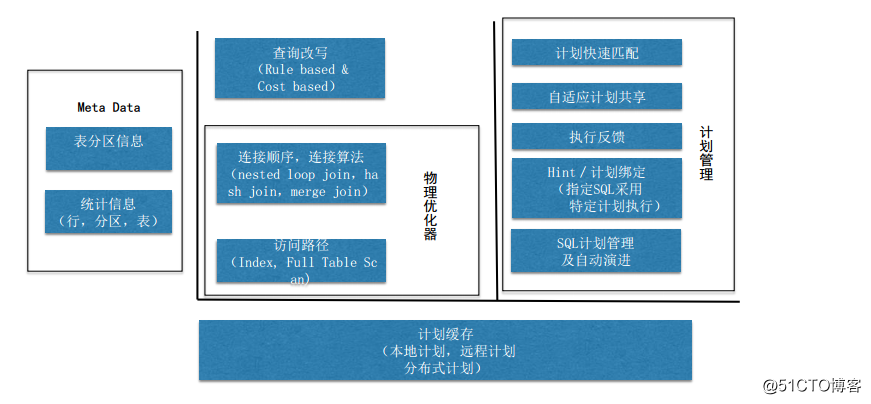
3.优化器的统计信息
OceanBase优化器实现了非常完备的统计信息,包括表(avg rowlen, # of rows),列(column NDV, null value, histogram, min/max),分区/行级的统计信息。为了防止引入额外的开销,统计只会在数据进行大版本合并的时候进行。存储引擎对于某些谓词可以提供较精准的数据量Cardinality估计,比如通过谓词可以推算出扫描索引的开始和结束区间,在SStable中每个block都有metadata统计行数,在MemTable中可以统计关于insert,delete,update操作的metadata。在OceanBase中,如果数据在合并过程中进行了修改,会导致数据不够精准,此时将采用动态采样的方式来解决该问题。
4.访问路径
因为OLTP的SQL查询计划比较简单,一般来说往往是单表,单索引的查询,所以访问路径对于OLTP非常重要。因此进行SQL查询时要进行相应的选择,例如主键扫描还是索引扫描,采用单列索引还是多列索引。选择的标准主要基于规则模型和代价模型,规则模型包括决定性规则(如主键全覆盖则采用主键扫描进行查询)和剪枝规则(运用skyline剪枝规则,多个维度比较,选择更好的索引)。之后再通过代价模型的比较选出最优模型进行查询。模型主要考虑的因素包括:扫描范围,是否回表,过滤条件,Interesting order等。
5.计划缓存
计划缓存是指在一个计划生成之后,后续如果出现同一个查询或者相似的查询,可以使用现有的计划而无需重新生成计划,计划缓存通过高效的词法解析器匹配输入的查询语句,使用参数化查询优化进行匹配。下面为一个计划查询的例子。
可以看到,在计划缓存中对于查询语句会进行参数的模糊匹配,但对于特定含义的参数会加入限定条件,比如order by 3中的参数3代表是第三列,该参数的修改可能会导致计划缓存的不适用,因此存储计划缓存时加入了限定条件@3 = 3。
6.自适应共享计划
对于一个查询语句只要参数相似就一定能进行计划缓存的匹配吗?答案是否定的,举一个例子,在一个查询语句中对于salesman因为数据量较大,会采用全表扫描的方式进行查询,而对于president,因为数据量非常少,可能通过索引的方式进行查询的代价要比全表扫描的代价更好,因此对于这种情况,同样需要加入相应的限定条件。但重新生成的计划可能和原有计划相同,发生这种情况后,便会对于原有的限定条件进行修改,方便之后的查询语句进行计划匹配,以此来达到自适应计划共享。
7. Hint/Outline
在OceanBase中如果对于自动化生成的计划不满意,也可以通过创建Outline的方式来绑定自定义的计划,也就是通过Hint来制定计划的生成,Hint的类型十分丰富,包括:access path, join order, join method, parallel distribution等,下面是Outline绑定的两个例子。
8.SQL计划管理及演进
很多用户特别是企业级用户对于稳定性的要求非常高,因此OceanBase在进行系统升级,统计信息更新,硬件更新后会自动进行一个流量的演进,即同时运行新计划和老计划,当确定新计划相较于老计划无性能回退时,才会逐渐将老计划替换成新计划。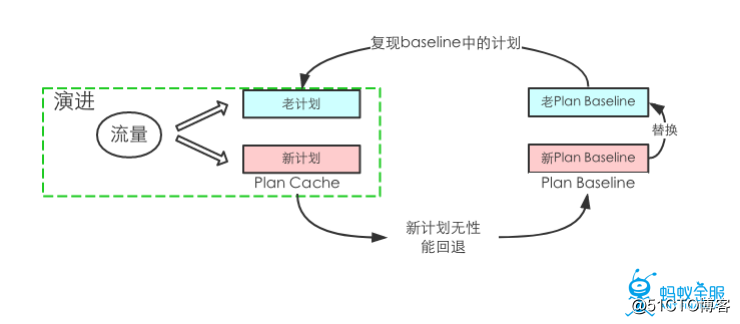
9.分区及分区裁剪
OceanBase支持多种分区类型,包括Range,Hash,Key,List。对于二级分区支持Range/Range, Range/Hash, Range/List, Hash/Hash, Hash/Range等。对于静态或动态分区裁剪支持inlist, 函数表达式,join filter等多种方式。
10.查询改写
查询改写主要包括基于规则的改写以及基于代价的改写,基于规则的改写主要包括视图合并,子查询展开,过滤条件下推, 连接条件下推,等价条件推导,外连接消除等。基于代价的改写主要包括OR-expansion,Window function等,查询改写对于OLAP的优化效果非常好。下图为基于代价模型的改写框架。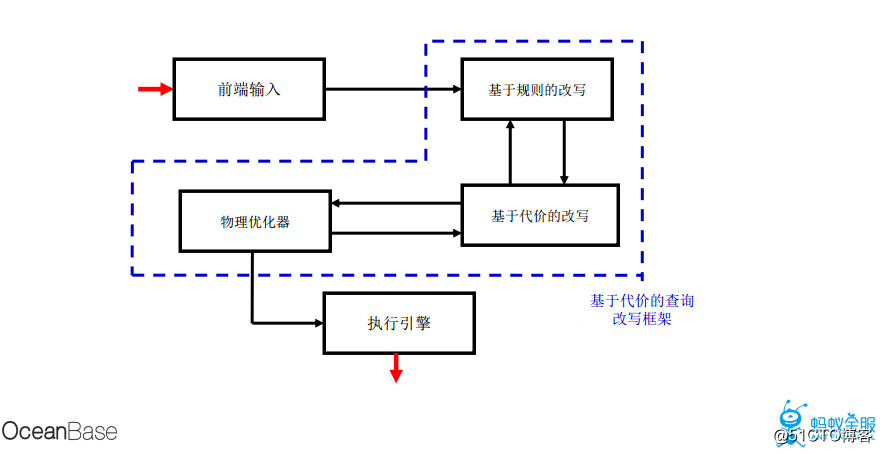
四、SQL执行引擎
优化器和执行引擎是相辅相成的,优化器所能优化的计划取决于执行引擎的执行计划。
1.并行执行
并行执行的概念就是分治,分治包括垂直分治(比如拆分计划为子计划单元)和水平分治(比如GI(Granule Iterator)获取扫描任务),并行执行主要用于OLAP场景中,解决查询RT时间的问题,这在很多在线分析的场景下是十分必要的。RT时间对于RDBMS查询是一个重要指标,传统的Map-Reduce的执行性能并不能满足OLAP的性能需求,因此如何找到高效的执行计划及数据流水线非常关键。在OceanBase中采用两级调度,自适应的子计划调度框架,各节点独立的任务切分等方案来进行并行执行。对于数据重分布,OceanBase支持大多数常见的数据分布,包括Hash, Broadcast/Replicate,,Round Robin,Merge Sort等。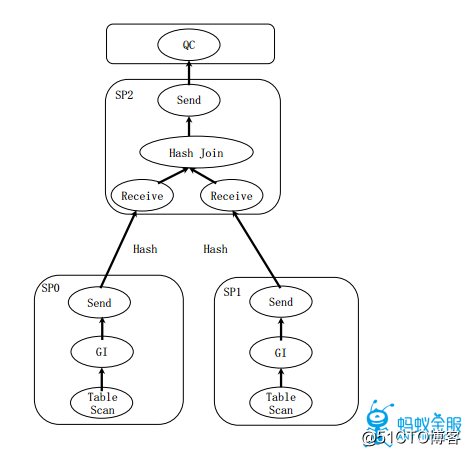
2.两级调度
在OceanBase中通过下面所述的方式形成两级调度。即将查询涉及到的各个机器上分别创建一个执行节点(SQC),来让主控节点(QC)控制SQC,其中QC为机器级的控制,SQC为线程级的控制。QC进行全局调度,依据总并行度分配各节点各子计划并行度, SQC进行本机调度,其中各节点独立决定水平并行粒度及执行。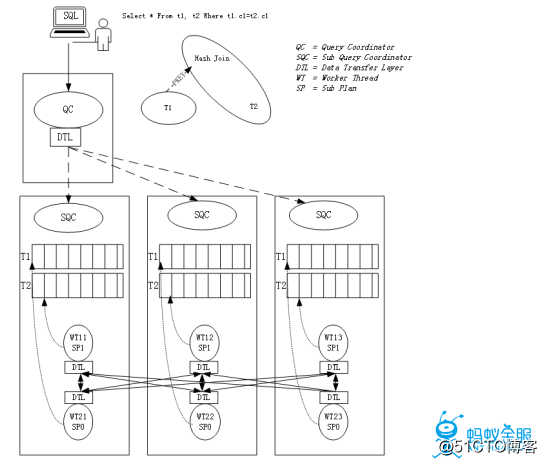
3.计划动态调度
计划动态调度是指根据用户指定或系统资源自适应决定在允许的资源使用范围内,减少中间结果缓存,构建2组或以上计划子树的执行流水线(垂直并行),这种方式可以有效的避免物化,减少物化算子对并行执行所造成的不良影响。该功能正在开发测试中。
4.并行执行计划
OceanBase中拥有所有主要算子的并行执行方法,包括nested-loop join, merge join, hash join,aggregation, distinct, group by,window function, count, limit等,同时支持丰富的重分布方法和多种候选计划,例如partition-wise join, partial partitionwise join,broadcast, hash, sort(for distributedorder by)等。
事实上,并行查询的优化技术在MPP架构下产生了新的问题,比如分区连接要求各表的分区从逻辑上和物理上都是一样的,这也是一个需要考虑和优化的方向。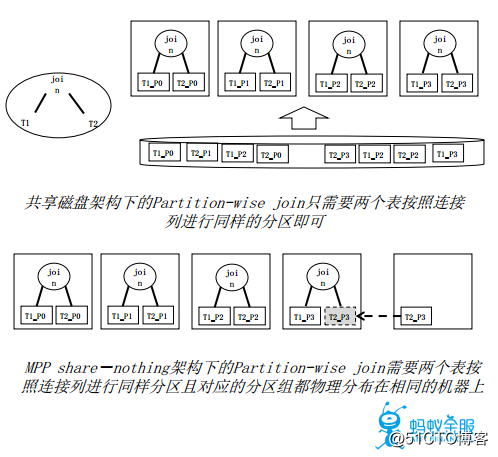
5.编译执行
传统执行方式如类型检查,多态(虚函数)对于内存操作很低效。OceanBase考虑采用LLVM 动态生成执行码,SQL表达式可以支持动态生成执行码,存储过程采用直接编译执行的方式,来进行性能提升。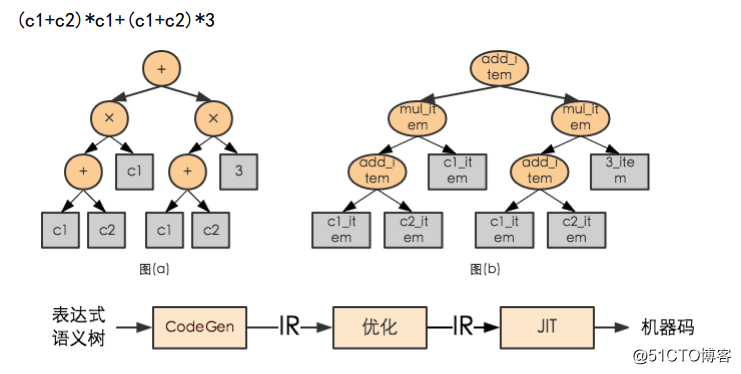
整理:杨德宇
以上是关于支付宝支撑2135亿成交额的数据库架构原理的主要内容,如果未能解决你的问题,请参考以下文章
独家揭秘阿里自研飞天操作系统洛神平台如何支撑起 2684 亿全球大促!| 问底中国 IT 技术演进