24分钟让AI跑起飞车类游戏
Posted wetest
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了24分钟让AI跑起飞车类游戏相关的知识,希望对你有一定的参考价值。
WeTest 导读
本文主要介绍如何让AI在24分钟内学会玩飞车类游戏。我们使用Distributed PPO训练AI,在短时间内可以取得不错的训练效果。
本方法的特点:
1. 纯游戏图像作为输入
2. 不使用游戏内部接口
3. 可靠的强化学习方法
4. 简单易行的并行训练
1. PPO简介
PPO(Proximal Policy Optimization)是OpenAI在2016年NIPS上提出的一个基于Actor-Critic框架的强化学习方法。该方法主要的创新点是在更新Actor时借鉴了TRPO,确保在每次优化策略时,在一个可信任的范围内进行,从而保证策略可以单调改进。在2017年,DeepMind提出了Distributed PPO,将PPO进行类似于A3C的分布式部署,提高了训练速度。之后,OpenAI又优化了PPO中的代理损失函数,提高了PPO的训练效果。
本文不介绍PPO的算法细节,想学习的同学可以参考以下三篇论文:
【1】Schulman J, Levine S, Abbeel P, et al. Trust region policy optimization[C]//International Conference on Machine Learning. 2015: 1889-1897.
【2】Heess N, Sriram S, Lemmon J, et al. Emergence of locomotion behaviours in rich environments[J]. arXiv preprint arXiv:1707.02286, 2017.
【3】Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms[J]. arXiv preprint arXiv:1707.06347, 2017.
2. 图像识别
2.1 游戏状态识别
游戏状态识别是识别每一局游戏关卡的开始状态和结束状态。在飞车类游戏中,开始状态和结束状态的标志如图1所示。因为红色框中的标志位置都固定,因此我们使用模板匹配的方法来识别这些游戏状态。

图1 游戏状态标志
从开始状态到结束状态之间的图像是游戏关卡内的图像,此时进行强化学习的训练过程。当识别到结束状态后,暂停训练过程。结束状态之后的图像都是UI图像,我们使用UI自动化的方案,识别不同的UI,点击相应的按钮再次进入游戏关卡,开始下一轮的训练过程,如图2所示。

图2 游戏流程
2.3 游戏图像识别
我们对游戏关卡中的图像识别了速度的数值,作为强化学习中计算激励(Reward)的依据,如图3所示。速度识别包括三个步骤:
第一步,图像分割,将每一位数字从识别区域中分割出来。
第二步,数字识别,用卷积神经网络或者模板匹配识别每一位图像中的数字类别。
第三步,数字拼接,根据图像分割的位置,将识别的数字拼接起来。
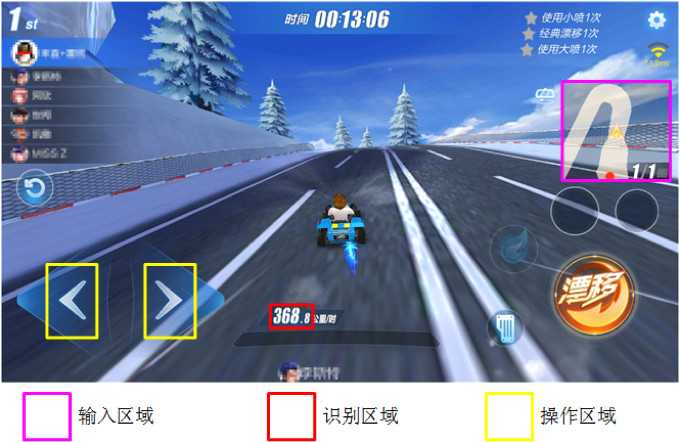
图3 图像各个区域示意图
3. AI设计
3.1 网络结构
我们使用的网络结构如图4所示。输入为游戏图像中小地图的图像,Actor输出当前时刻需要执行的动作,Critic输出当前时刻运行状态的评价。AlexNet使用从输入层到全连接层之前的结构,包含5个卷积层和3个池化层。Actor和Critic都有两个全连接层,神经元数量分别为1024和512。Actor输出层使用softmax激活函数,有三个神经元,输出动作策略。Critic输出层不使用激活函数,只有一个神经元,输出评价数值。
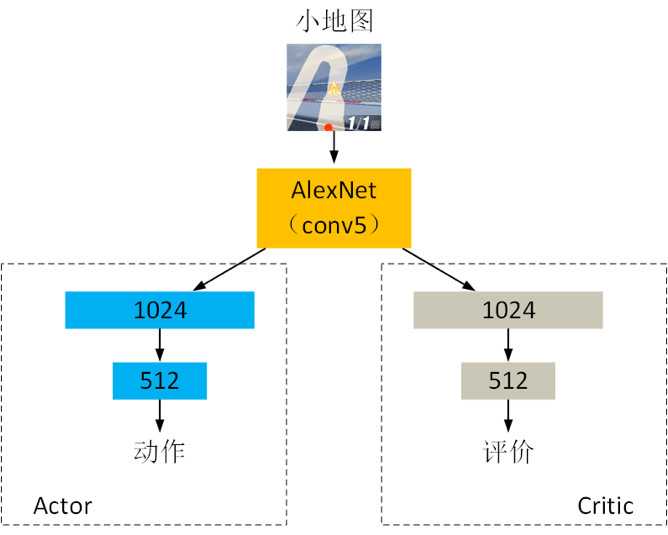
图4 网络结构示意图
3.2 输入处理
我们将小地图图像的尺寸变为121X121,输入到AlexNet网络后,在第三个池化层可以获得2304维的特征向量(576*2*2=2304)。将这个特征向量作为Actor和Critic的输入。我们使用在ImageNet上训练后的AlexNet提取图像特征,并且在强化学习的过程中没有更新AlexNet的网络参数。
3.3 动作设计
我们目前在设计飞车类游戏动作时,使用离散的动作,包括三种动作:左转、右转和NO Action。每种动作的持续时间为80ms,即模拟触屏的点击时间为80ms。这样的动作设计方式比较简单,便于AI快速地训练出效果。如果将动作修改为连续的动作,就可以将漂移添加到动作中,让AI学习左转、右转、漂移和NO Action的执行时刻和执行时长。
3.4 激励计算
如果将游戏的胜负作为激励来训练AI,势必会花费相当长的时间。在本文中,我们根据游戏图像中的速度数值,计算当前时刻的激励。假定当前时刻的速度为Vp,前一时刻的速度为Vq,那么激励R按照以下方式计算:
If Vp ≥ Vq , R = 0.25X(Vp - Vq)
If Vp < Vq , R = -0.25X(Vq - Vp)
If Vp > 250 , R = R + 5.0
If Vp < 50 , R = R - 5.0
这样的激励计算方式可以使AI减少撞墙的概率,并且鼓励AI寻找加速点。
4. 训练环境
4.1 硬件
我们搭建了一个简单的分布式强化学习环境,可以提高采样效率和训练速度,硬件部署方式如图5所示。
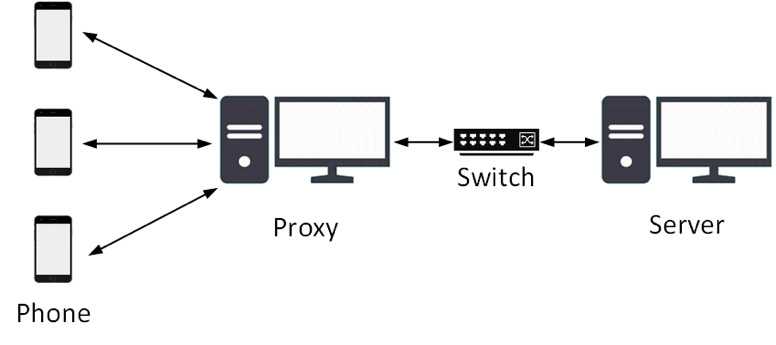
图5 硬件部署方式
主要包含以下硬件:
1)3部相同分辨率的手机,用于生成数据和执行动作。
2)2台带有显卡的电脑,一台电脑Proxy用于收集数据、图像识别以及特征提取,另一台电脑Server用于训练AI。
3)1个交换机,连接两台电脑,用于交换数据。
4.2 软件
Ubuntu 14.04 + TensorFlow 1.2 + Cuda 7.0
5. 分布式部署
我们使用的分布式部署方式如图6所示。
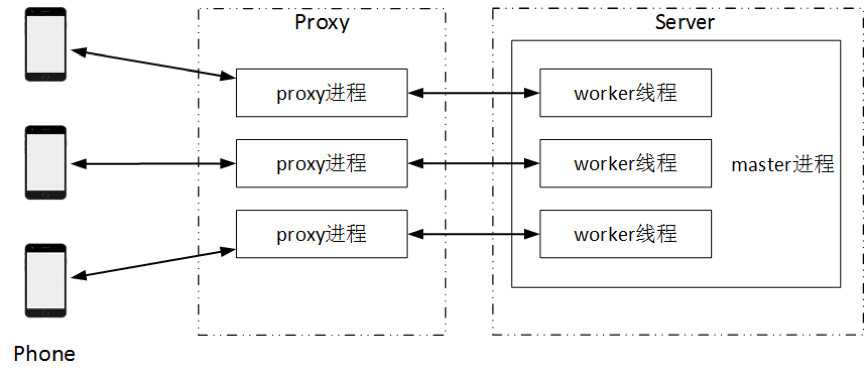
图6 分布式部署方式
在Proxy端设置三个proxy进程,分别与三部手机相连接。
在Server端设置一个master进程和三个worker线程。master进程和三个worker线程通过内存交换网络参数。master进程主要用于保存最新的网络参数。三个proxy进程分别和三个worker线程通过交换机传输数据。
proxy进程有6个功能:
1)从手机接收图像数据;
2)识别当前游戏状态;
3)识别速度计算激励;
4)利用AlexNet提取图像特征;
5)发送图像特征和激励到worker线程,等待worker线程返回动作;
6)发送动作到手机;
worker线程有5个功能:
1)从proxy进程接收图像特征和激励;
2)从master进程拷贝最新的网络参数;
3)将Actor输出的动作发送到proxy进程;
4)利用PPO更新网络参数;
5)将更新后的网络参数传输到master进程;
6. 实验
6.1 参数设置
PPO的训练参数很多,这里介绍几个重要参数的设置:
1)学习速率:Actor和Critic的学习率都设置为1e-5
2)优化器:Adam优化器
3)Batch Size: 20
4)采样帧率:10帧/秒
5)更新次数:15次
6)激励折扣率:0.9
6.2 AI效果
6.3 数据分析
表1和表2分别对比了不同并行数量和不同输入数据情况下AI跑完赛道和取得名次的训练数据。最快的训练过程是在并行数量为3和输入数据为小地图的情况下,利用PPO训练24分钟就可以让AI跑完赛道,训练7.5小时就可以让AI取得第一名(和内置AI比赛)。并且在减少一部手机采样的情况下,也可以达到相同的训练效果,只是训练过程耗时更长一点。另外,如果将输入数据从小地图换成全图,AI的训练难度会有一定程度的增加,不一定能达到相同的训练效果。
表1 AI跑完赛道的数据对比
|
输入数据 |
并行数量 |
训练时间 |
训练次数 |
训练局数 |
|
全图 |
2 |
100分钟 |
4200次 |
78局 |
|
小地图 |
2 |
40分钟 |
1700次 |
32局 |
|
全图 |
3 |
78分钟 |
3900次 |
72局 |
|
小地图 |
3 |
24分钟 |
1400次 |
25局 |
表2 AI取得名次的数据对比
|
输入数据 |
并行数量 |
训练时间 |
训练次数 |
训练局数 |
名次 |
|
小地图 |
2 |
9小时 |
19000次 |
354局 |
1 |
|
全图 |
3 |
60小时 |
98000次 |
1800局 |
4-6 |
|
小地图 |
3 |
7.5小时 |
17800次 |
343局 |
1 |
如7展示了利用PPO训练AI过程中激励的趋势图,曲线上每一个点表示一局累计的总激励。训练开始时,AI经常撞墙,总激励为负值。随着训练次数的增加,总激励快速增长,AI撞墙的几率很快降低。当训练到1400多次时,总激励值超过400,此时AI刚好可以跑完赛道。之后的训练过程,总激励的趋势是缓慢增长,AI开始寻找更好的动作策略。
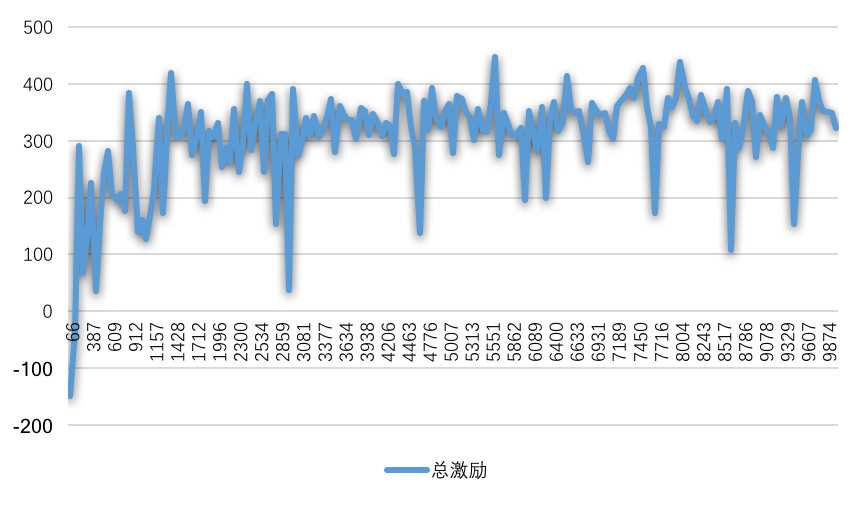
图7 AI训练过程中激励的趋势图
7. 总结
本文介绍了如何使用Distributed PPO在24分钟内让AI玩飞车类游戏。当前的方法有一定训练效果,但是也存在很多不足。
目前,我们想到以下几个改进点,以后会逐一验证:
1)将AlexNet替换为其他卷积神经网络,如VGG、Inception-V3等等,提高特征提取的表达能力。
2)提高并行数量,添加更多手机和电脑,提高采样速度和计算速度。
3)增加Batch Size,使用较长的时间序列数据训练AI。
4)将离散动作替换为连续动作,增加漂移的学习。
5)多个关卡同时训练,提高AI的泛化能力。
参考文献:
【1】Schulman J, Levine S, Abbeel P, et al. Trust region policy optimization[C]//International Conference on Machine Learning. 2015: 1889-1897.
【2】Heess N, Sriram S, Lemmon J, et al. Emergence of locomotion behaviours in rich environments[J]. arXiv preprint arXiv:1707.02286, 2017.
【3】Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms[J]. arXiv preprint arXiv:1707.06347, 2017.
【4】https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/6-4-DPPO/
“深度兼容测试”现已对外,腾讯专家为您定制自动化测试脚本,覆盖应用核心场景,对上百款主流机型进行适配兼容测试,提供详细测试报告,并且首度使用AI能力助力测试。
点击http://wetest.qq.com/cloud/deepcompatibilitytesting#/ 即可体验。
如果使用当中有任何疑问,欢迎联系腾讯WeTest企业QQ:2852350015
以上是关于24分钟让AI跑起飞车类游戏的主要内容,如果未能解决你的问题,请参考以下文章