面向对象
Posted midworld
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面向对象相关的知识,希望对你有一定的参考价值。
1. 三大编程范式
- 面向过程
- 函数式编程
- 面向对象设计
2. 编程进化论
- 最开始无组织无结构,从简单控制流中按步骤写指令
- 从上述指令中提取重复的代码看或逻辑,组织到一起(定义了一个函数),实现代码重用,由无结构走向了结构化,变得更具逻辑性。
- 定义函数是独立函数外定义变量,然后作为参数传递给函数,意味着数据与动作是分离的。
- 吧数据和动作封装到一个结构(函数或类),就有了个对象系统(对象就是数据与函数的封装)。
3. 类和对象
列表:数据封装、函数:语句层面的封装、对象:数据、函数的封装
- 类:种类,将一类具有相同特性(抽象的)和动作的事物整合到一起就是类。
- 基于类而创建的一个具体的事物(具体存在),也是特征和动作整合到一起。
现实世界是先有对象再有类,程序中先定义类,后再有对象
面向对象设计 OOD(object oriented design):将一类具体事务的数据和动作整合到一起
面向对象编程 OOP(object-oriented programming):用定义类+实例/对象的方式去实现面向对象的设计
实例化:由类抽象对象的过程实例化
不是只有用 class 定义类才是面向对象,def 定义函数就是函数相关,跟面向对象没有关系:
面向对象设计:
def school(name,addr,type):
def init(name, addr, type):
sch = {
‘name‘: name,
‘addr‘: addr,
‘type‘: type,
‘kao_shi‘: kao_shi,
‘zhao_sheng‘: zhao_sheng,
}
return sch
def kao_shi(school):
print(‘%s 学校正在考试‘ %school[‘name‘])
def zhao_sheng(school):
print(‘%s %s 正在招生‘ %(school[‘type‘],school[‘name‘]))
return init(name,addr,type)
s1 = school(‘清华大学‘, ‘中关村北大街‘, ‘公立学校‘)
print(s1)
print(s1[‘name‘])
s1[‘kao_shi‘](s1){‘name‘: ‘清华大学‘, ‘addr‘: ‘中关村北大街‘, ‘type‘: ‘公立学校‘, ‘kao_shi‘: <function school.<locals>.kao_shi at 0x0000000005382D90>, ‘zhao_sheng‘: <function school.<locals>.zhao_sheng at 0x0000000005382BF8>}
清华大学
清华大学 学校正在考试面向对象编程:
class School:
def __init__(self, name, addr, types):
self.name = name
self.addr = addr
self.types = types
def kao_shi(self):
print(‘%s 正在考试‘ % self.name)
def zhao_sheng(self):
print(‘%s %s 正在招生‘ %(self.types, self.name))
s1 = School(‘清华大学‘, ‘中关村北大街‘, ‘公立学校‘)
s1.kao_shi()
print(s1.__dict__)清华大学 正在考试
{‘name‘: ‘清华大学‘, ‘addr‘: ‘中关村北大街‘, ‘types‘: ‘公立学校‘}总结:
Python 是一门面向对象的语言,但是它不强制要求必须使用面向对象去设计代码,它不像 Java 一样万物皆是类。
3.1 类
类声明
class 类名:
‘类体字符串‘
类体
def func():
‘函数文档字符串‘
函数体3.2 实例化
self
如果把对象比作一个房子,那么 self 就是门牌号,有了 self 就可以轻松找到自己的房子。
当一个对象的方法被调用时,对象会将 自身的引用作为第一个参数传给该方法,那么 Python 就知道需要操作哪个对象的方法了。
class Students:
def __init__(self, name, score):
self.name = name
self.score = score
def print_score(self):
print(‘%s 分数是:%s‘ % (self.name, self.score))
s1 = Students(‘rose‘, 98) # 相当于 s1 = Stuents.__init__(s1, ‘rose‘, 98)
s1.print_score()
rose 分数是:98构造方法
通常把 __init__() 方法称为构造方法,只有实例化一个对象,这个方法就会在对象被创建时自动调用。实例化传入的参数自动传入 __init__() 中,可以通过重写这个方法来自定义对象的初始化操作:
class Students:
def __init__(self, name):
self.name = name
def print_score(self):
print(‘名字 %s‘ % self.name)
s1 = Students(‘rose‘) # 自动调用 __init__(),参数自动传入 __init__() 中
s1.print_score()实例属性
对象只有数据属性,没有函数属性,用的时候找类要:
- 类的数据属性是所有对象共享的
- 类的函数属性是绑定给对象用的,在对象调用函数属性时,也能找到
# s1.__dict__ 查看对象属性
class Students:
color = ‘black‘
def __init__(self, name, score):
self.name = name
self.score = score
def print_score(self):
print(‘%s 分数是:%s‘ % (self.name, self.score))
s1 = Students(‘rose‘, 98)
print(s1.__dict__) # 查看对象属性字典,发现只有属性属性
print(id(Students.color)) # 对比发现类和对象的数据属性共享的
print(id(s1.color))
print(Students.print_score) # 发现类的函数属性与实例的函数属性不一样,内存地址不一样
print(s1.print_score){‘name‘: ‘rose‘, ‘score‘: 98}
82934784
82934784
<function Students.print_score at 0x0000000004F85620>
<bound method Students.print_score of <__main__.Students object at 0x0000000004F98BE0>>
# bound method :绑定方法(绑定了 类 Students 的 print_score 方法)可以看出对象只有数据属性没有函数属性,类的函数属性与实例的函数属性不一样,内存地址不一样。
3.3 类属性增删改查
类属性又称为静态变量,或静态数据,这些数据与它们所属的类对象绑定,不依赖任何实例。如果是 java 程序员,这种类型数据相当于在一个变量声明前加上 static 关键字
类名:大写、函数属性:动词+名词
数据属性
class Chinese:
country = ‘China‘ # 数据属性
def __init__(self, name):
self.name = name
def play_ball(self, ball):
print(‘%s 正在打 %s‘ % (self.name))
p1 = Chinese(‘rose‘)
# 查看类属性
print(Chinese.country)
# 修改
Chinese.country = ‘CHINA‘
print(Chinese.country)
# 增加
Chinese.gender = ‘male‘
print(Chinese.__dict__)
# 删除
del Chinese.gender
print(Chinese.__dict__)China
CHINA
{‘__module__‘: ‘__main__‘, ‘country‘: ‘CHINA‘, ‘__init__‘: <function Chinese.__init__ at 0x0000000004F85D08>, ‘play_ball‘: <function Chinese.play_ball at 0x0000000004F85BF8>, ‘__dict__‘: <attribute ‘__dict__‘ of ‘Chinese‘ objects>, ‘__weakref__‘: <attribute ‘__weakref__‘ of ‘Chinese‘ objects>, ‘__doc__‘: None, ‘gender‘: ‘male‘}
{‘__module__‘: ‘__main__‘, ‘country‘: ‘CHINA‘, ‘__init__‘: <function Chinese.__init__ at 0x0000000004F85D08>, ‘play_ball‘: <function Chinese.play_ball at 0x0000000004F85BF8>, ‘__dict__‘: <attribute ‘__dict__‘ of ‘Chinese‘ objects>, ‘__weakref__‘: <attribute ‘__weakref__‘ of ‘Chinese‘ objects>, ‘__doc__‘: None}函数属性
# 增加一个 eat 方法
def eat(self, food):
print(‘%s 正在吃 %s‘ % (self.name, food))
Chinese.test = eat # test 指向 eat
p1.test(‘fish‘)
print(Chinese.__dict__)
# Chinese.play_ball = ball 修改属性rose 正在吃 fish
{‘__module__‘: ‘__main__‘, ‘country‘: ‘China‘, ‘__init__‘: <function Chinese.__init__ at 0x0000000004FA82F0>, ‘play_ball‘: <function Chinese.play_ball at 0x0000000004FA8268>, ‘__dict__‘: <attribute ‘__dict__‘ of ‘Chinese‘ objects>, ‘__weakref__‘: <attribute ‘__weakref__‘ of ‘Chinese‘ objects>, ‘__doc__‘: None, ‘test‘: <function eat at 0x0000000004F850D0>}3.4 实例属性的增删改查
class Students:
color = ‘black‘
def __init__(self, name, score):
self.name = name
self.score = score
def print_score(self):
print(‘%s 分数是:%s‘ % (self.name, self.score))
s1 = Students(‘rose‘, 98)
# 查看数据、函数属性
print(s1.__dict__)
print(s1.name)
print(s1.print_score) # <bound method Students.print_score of <__main__.Students object at 0x0000000004FDD198>> 可以看出实例的函数属性绑定的是 类的函数属性(<bound method Students.print_score)
# 增加
s1.age = 18
print(s1.__dict__)
# 修改
s1.age = 20
print(s1.__dict__)
#不要修改底层的属性字典,会造成 OOP 不稳定
# s1.__dict__[‘age‘]=‘30‘
# print(s1.__dict__)
# print(s1.sex)
# 删除
del s1.age
print(s1.__dict__){‘name‘: ‘rose‘, ‘score‘: 98}
rose
<bound method Students.print_score of <__main__.Students object at 0x0000000004FDD198>>
{‘name‘: ‘rose‘, ‘score‘: 98, ‘age‘: 18}
{‘name‘: ‘rose‘, ‘score‘: 98, ‘age‘: 20}
{‘name‘: ‘rose‘, ‘score‘: 98}属性作用域
在 class 类中定义的数据属性,属于类的属性。在 __init__() 中定义的是实例的数据属性。不管是类的还是实例的数据属性,都只能使用点(.)方式访问,其他方式访问皆为普通变量。
country = ‘中国》》》‘
class Chinese:
country = ‘中国‘
def __init__(self, name):
self.name = name
print(‘---->‘, country) # 这里访问的就是普通变量,没有选择类的属性 country = ‘中国‘,而是选择了普通变量 country = ‘中国》》》‘
def eat(self):
pass
p1 = Chinese(‘林雷‘)
# p1.country = ‘》》》中国‘ # 其实这里是增加实例的数据属性
# print(‘类的数据属性:‘, Chinese.country) 类的数据属性: 中国
# print(‘实例的数据属性:‘, p1.country) 实例的数据属性: 》》》中国
print(Chinese.country)
print(p1.country)
----> 中国》》》
中国
中国总结
- 类的数据属性是所有对象都可以共享的,函数属性绑定给对象使用
- 实例(对象)只有数据属性,没有函数属性,调用函数属性是对类的函数属性的引用
3.5 静态属性
我们知道类既有数据属性也有函数属性,而实例只有数据属性。在使用实例调用类的函数属性时,总要带上函数后面的括号才能运行,不然调用的是函数的内存地址:
class Room:
def __init__(self, name, owner, width, heigh, length):
self.name = name
self.owner = owner
self.width = width
self.heigh = heigh
self.length = length
def calc_area(self):
print(‘%s 住的%s,总面积:%s‘ % (self.owner, self.name, self.width * self.length))
r1 = Room(‘卧室‘, ‘rose‘, 10, 3.5, 16)
r1.calc_area # <bound method Room.calc_area of <__main__.Room object at 0x0000000004FC9EB8>>问题:那么有什么方法可以向调用数据属性一样调用函数属性呢?
类中提供了 @property 关键字,它的作用是在调用函数属性时,可以像调用数据属性一样并允许该函数,类似于函数中的装饰器。
class Room:
def __init__(self, name, owner, width, heigh, length):
self.name = name
self.owner = owner
self.width = width
self.heigh = heigh
self.length = length
@property
def calc_area(self):
print(‘%s 住的%s,总面积:%s‘ % (self.owner, self.name, self.width * self.length))
# return self.width * self.length
r1 = Room(‘卧室‘, ‘rose‘, 10, 3.5, 16)
# r1.calc_area()
r1.calc_area # 省略括号只需在需要被装饰的函数上面,加上 @property 即可。需要注意的是:被装饰的函数不能有除 self 参数以外的参数
3.6 类方法
如果不进行实例化,直接用类名调用类的函数属性,会报缺少位置参数:
class Room:
def __init__(self, name, owner, width, heigh, length):
self.name = name
self.owner = owner
self.width = width
self.heigh = heigh
self.length = length
@property
def calc_area(self):
print(‘%s 住的%s,总面积:%s‘ % (self.owner, self.name, self.width * self.length))
def open_door(self):
print(‘打开%s的门‘ % self.name)
Room.open_door()---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-60-9b6abeb723cc> in <module>()
13 print(‘打开%s的门‘ % self.name)
14
---> 15 Room.open()
TypeError: open_door() missing 1 required positional argument: ‘self‘传入 self 做参数,也会报 name ‘self‘ is not defined。这样因为 self 是特殊意义的,是实例本身,只有在实例化时才有效。为了解决这种问题,我们引入了 @classmethod ,:
class Room:
size = ‘small‘
def __init__(self, name, owner, width, heigh, length):
self.name = name
self.owner = owner
self.width = width
self.heigh = heigh
self.length = length
@property
def calc_area(self):
print(‘%s 住的%s,总面积:%s‘ % (self.owner, self.name, self.width * self.length))
@classmethod
def open_door(cls, color):
print(cls) # cls 相当于 类本身,在定义类方法时自动补全
print(‘请打开那扇 %s 的 %s门‘ % (color, cls.size))
Room.open_door(‘red‘)
---------------------------------------------------
<class ‘__main__.Room‘>
请打开那扇 red 的 small门可以看出一旦类的某个函数属性被定义为类方法时,可以直接使用类名调用类的函数属性,而不用担心参数的问题。在定义类方法时,Python 会自动补全一个名叫 cls 的参数,可以看出它就是类本身,在调用类函数属性时不需要手动传入,本身会自动传入,与 self 类似。
3.7 静态方法
如果有想在类中定义一个函数,要求该函数的参数与类、实例都无关(没有绑定),我们可以使用静态方法 @staticmethod:
class Room:
size = ‘small‘
def __init__(self, name, owner, width, heigh, length):
self.name = name
self.owner = owner
self.width = width
self.heigh = heigh
self.length = length
@staticmethod
def close_door(position, color):
print(‘请关闭 %s 的 %s 小门‘ % (position, color))
r1 = Room(‘卧室‘, ‘rose‘, 10, 20, 30)
Room.close_door(‘厨房‘, ‘black‘)
r1.close_door(‘厕所‘, ‘white‘)被定义为静态方法的函数属性,名义上归类管理,但不能使用类变量和实例变量,只是类的工具包。
3.8 总结
- 静态属性:可以使用类、实例的数据属性,不能累调用(绑定实例)
- 类方法:不能使用实例的数据属性,可以用类、实例调用(与类绑定)
- 静态方法:不能使用类、实例的数据属性,可以用类、实例调用(与类、实例都不绑定)
- 常规函数:不能使用类、实例的数据属性,不能用实例调用(与类、实例都不绑定)
class Room:
size = ‘small‘
def __init__(self, name, owner, width, heigh, length):
self.name = name
self.owner = owner
self.width = width
self.heigh = heigh
self.length = length
@property
def calc_area(self):
print(‘%s 住的%s,总面积:%s‘ % (self.owner, self.name, self.width * self.length))
@classmethod
def open_door(cls, color):
#print(cls)
print(‘请打开那扇 %s 的 %s门‘ % (color, cls.size))
@staticmethod
def close_door(position, color):
print(‘请关闭 %s 的 %s 小门‘ % (position, color))
def test(a, b):
print(a, ‘-->‘, ‘b‘)
r1 = Room(‘卧室‘, ‘rose‘, 10, 20, 30)
# 静态属性
Room.calc_area # 不能调用
r1.calc_area # rose 住的卧室,总面积:300
# 类方法
Room.open_door(‘white‘) # 请打开那扇 white 的 small门
r1.open_door(‘white‘) # 请打开那扇 white 的 small门
# 静态方法
Room.close_door(‘卧室‘, ‘black‘) # 请关闭 卧室 的 black 小门
r1.close_door(‘卧室‘, ‘black‘) # 请关闭 卧室 的 black 小门
# 常规函数
Room.test(1, 2) # 1 --> b
r1.test(1, 2) # 不能调用4. 组合
组合就是把一个类实例化传入另一个类中使用。类与类之间相互关联,并且小的类组成大的类,这个时候可以用组合。
class Turtle:
def __init__(self, x):
self.x = x
class Fish:
def __init__(self, x):
self.x = x
class Pool:
def __init__(self, x, y):
self.tutle = Turtle(x)
self.fish = Fish(y)
def print_num(self):
print(‘水池里总共有%s只乌龟,%s条鱼‘ % (self.tutle.x, self.fish.x))
p1 = Pool(2, 3)
p1.print_num()水池里总共有2只乌龟,3条鱼选课系统:
class School:
def __init__(self, name, addr):
self.name = name
self.addr = addr
def zhao_sheng(self):
print(‘%s正在招生‘ % self.name)
class Course:
def __init__(self, name, price, period, school):
self.name = name
self.price = price
self.period = period
self.school = school
class Teacher:
def __init__(self, name, gender, age):
self.name = name
self.gender = gender
self.age = age
s1 = School(‘oldboy‘, ‘北京‘)
s2 = School(‘oldboy‘, ‘南京‘)
s3 = School(‘oldboy‘, ‘东京‘)
t1 = Teacher(‘林老师‘, ‘男‘, ‘45‘)
t2 = Teacher(‘李老师‘, ‘女‘, ‘28‘)
t3 = Teacher(‘孙老师‘, ‘女‘, ‘32‘)
c1 = Course(‘linux‘, ‘10000‘, ‘1‘, s1)
print(c1.__dict__)
msg = """
1 老男孩 北京校区
2 老男孩 南京校区
3 老男孩 东京校区
4 林老师
5 李老师
6 孙老师
"""
while True:
print(msg)
menu = {
‘1‘: s1,
‘2‘: s2,
‘3‘: s3,
‘4‘: t1,
‘5‘: t2,
‘6‘: t3
}
choice = input(‘请选择校区:‘)
choice_teacher = input(‘请选择老师:‘)
teacher_obj = menu[choice_teacher]
school_obj = menu[choice]
name = input(‘课程名:‘)
price = input(‘课程费用:‘)
period = input(‘课程周期:‘)
new_course = Course(name, price, period, school_obj) # school_obj = s1
print(‘课程【%s】属于【%s】学校‘ % (new_course.name, new_course.school.name))
# new_courese.school = s1 s1.name = name = oldboy
new_teacher = Course(name, price, period, teacher_obj)
print(‘%s由%s教‘ % (new_teacher.name, new_teacher.school.name))5. 面向对象三大特性
继承、多肽、封装
5.1 继承
类的继承与现实生活中的父、子继承关系一样。被继承的类称为父类、基类或超类,继承者称为子类。Python 继承分为:单继承和多继承(继承多个类)。
class Parent1:
pass
class Parent2:
pass
class Sub1(Parent1):
pass
class Sub2(parent1, Parent2):
passclass Dad:
"""父类"""
money = 100000
def __init__(self, name):
print(‘爸爸‘)
self.name = name
def hit_son(self):
print(‘%s正在打儿子‘ % self.name)
class Son(Dad):
pass
print(Son.money) 100000
Son.hit_son() # hit_son() missing 1 required positional argument: ‘self‘
# hit_son() 有一个位置参数 self,使用类名调用,不能传入 self,只能用实例调用
print(Dad.__dict__)
print(Son.__dict__)
s1 = Son(‘tom‘) # 爸爸
print(s1.money) # 100000
s1.hit_son() # tom正在打儿子
print(s1.__dict__) # {‘name‘: ‘tom‘}子类继承父类的所有属性,调用父类的方法只能用实例调用。
class Son(Dad):
money = 9000
def __init__(self, name, age):
self.name = name
self.age = age
def hit_son(self):
print(‘来自子类‘)
s2 = Son(‘rose‘, 18)
print(s2.money)
print(Dad.money)
s2.hit_son()9000
100000
来自子类如果子类中定义与父类同名的方法或属性,不会覆盖父类对应的方法或属性,只是优先调用自己类本身的方法或属性。
5.1.1 什么时候用继承
- 当类之间有显著的不同,并且较小的类是较大类所需组件时,用组合比较好
- 如:一个机器人可以是一个类,它的手臂、腿和身体等也都可以是一个类,它们互不相关
- 当类之间有很多相同功能,提取这些共同的功能做成基类,用继承比较好
- 如:猫、狗都要吃喝拉撒,同时也有自己独特的声音,提取它们的共性作为基类
class Cat:
def 喵喵叫(self):
pass
def 吃(self):
pass
def 喝(self):
pass
class Dog:
def 汪汪叫(self):
pass
def 吃(self):
pass
def 喝(self):
pass狗和猫都属于动物,提取它们的共性,做成基类:
class Animal:
def 吃(self):
pass
def 喝(self):
pass
class Cat(Animal):
def 喵喵叫(self): # 派生
pass
class Dog(Animal):
def 汪汪叫(self): # 派生
pass喵喵叫、汪汪叫是派生而来的,吃喝拉撒是继承而来
派生(衍生):子类在继承父类的基础上衍生出新的属性,如:Cat 的喵喵叫、Dog 的汪汪叫。也可以是子类定义与父类重名的属性,子类也称为派生类。
5.1.2 继承的两种含义
- 继承基类的方法,并且做出自己的改变(派生)或拓展(代码重用)
- 这种方法应尽量少用,因为子类于基类出现强耦合,容易出现未知错误。
- 声明某个子类兼容于某基类,定义一个接口类,子类继承接口类,并且实现接口中定义的方法。—— 接口继承
5.1.3 接口继承与归一化
接口继承:
抽象:即提取类似部分
接口:基类的函数属性,只提供函数名,不实现具体功能
定义一个基类,在基类中利用装饰器 (@abc.abstractclassmethod)将自己的函数属性定义成接口函数,在子类中必须实现该接口函数,否则无法实例化。
接口继承实质上是要求 做出一个良好的抽象,这个抽象规定了一个兼容接口,使得外部调用者无需关心具体细节,可一视同仁的处理实现了特定接口的所有对象 —— 这在程序上,叫做归一化。
归一化使的高层的外部使用者可以不加区分的处理所有接口兼容的对象集合 —— 就好比 linux 的泛文件概念一样,所有东西都可以当文件处理,不必关心它是内存、硬盘、网络还是屏幕(对于底层设计者来说,也可以区分出 字符串设备 和 块设备,然后做出针对性的设计,细致到什么程度,视需求而定)。
import abc
class All_file(metaclass=abc.ABCMeta): # 基类
@abc.abstractmethod # 装饰器定义两个接口函数 read、write
def read(self): # 那么子类必须实现这两个函数,否无法实例化
pass
@abc.abstractmethod
def write(self):
pass
class Disk(All_file):
def read(self):
print(‘disk read‘)
def write(self):
print(‘disk write‘)
class Memory(All_file):
def read(self):
print(‘memory read‘)
d1 = Disk()
d1.read()
d1.write()
m1 = Memory()
m1.read()disk read
disk write
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-15-53d88a516ad1> in <module>()
23 d1.write()
24
---> 25 m1 = Memory()
26 m1.read()
TypeError: Can‘t instantiate abstract class Memory with abstract methods write可以看出 Disk 子类实现了基类的接口函数,可以正常实例化并调用函数属性。而 Memory 子类,没有实现 Write() ,实例化失败。
5.1.4 继承顺序
Python 可以继承多个类,c#、java 只能继承一个。如果继承多个,那么其寻找方式有两种:深度优先和广度优先。
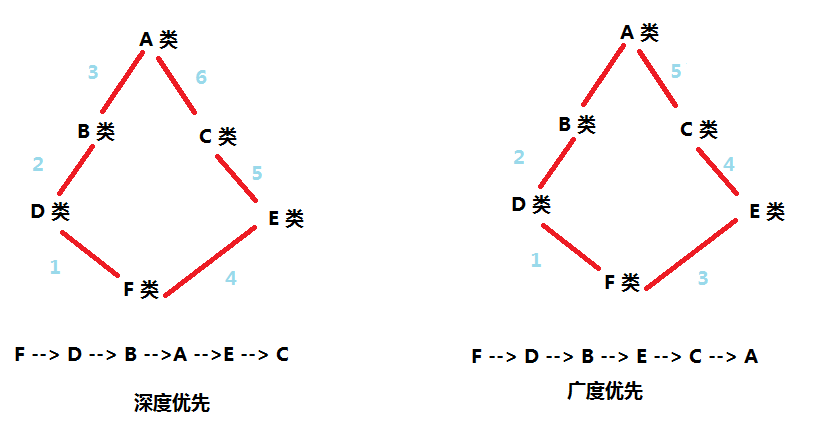
- 当类是经典类时,多继承按照深度优先查找
- 当类是新式类时(Python 3.x 都是新式类),多继承按照广度优先查找
问题:Python 是如何实现继承的?按照什么样的方式去查找的呢?
对于定义的每一个类,Python 会计算出一个方法解析顺序(MRO)元组,它是一个简单的所有基类的线性顺序元组,即一旦实现了继承。就已经计算好查找顺序,并存储在元组中。查看方式:
Class.__mro__ # F.__mro__为了实现继承,Python 会在 MRO 元组上从左到右开始查找基类,直至找到第一个匹配这个属性的类位置。
而这个 MRO 元组的构造是通过一个 C3 线性化算法来实现的。实际上就是合并所有父类的 MRO 元组并遵循如下三条准则:
- 子类会优先父类被检查:即子类与父类有同样的方法时,优先检查子类
- 多个父类会根据它们在列表中的顺序被检查:
F(D, E)D 要优先 E - 如果对下一个类存在两个合法的选择,选择第一个父类
class A(object):
def test(self):
print(‘A‘)
class B(A):
def test(self):
print(‘B‘)
class C(A):
def test(self):
print(‘C‘)
class D(B):
def test(self):
print(‘E‘)
class E(C):
def test(self):
print(‘E‘)
class F(D, E):
def test(self):
print(‘F‘)
f1 = F()
f1.test()
print(F.__mro__) # F --> D --> B --> E --> C --> A --> object F
(<class ‘__main__.F‘>, <class ‘__main__.D‘>, <class ‘__main__.B‘>, <class ‘__main__.E‘>, <class ‘__main__.C‘>, <class ‘__main__.A‘>, <class ‘object‘>)在 Python 2.x 中有新式类和经典类之分,新式类与 Python3.x 的查找顺序一样。而经典类的查找顺序为:F --> D --> B --> A --> E --> C 。
5.1.5 子类中调用父类的方法
如果想在子类中调用父类的方法(函数属性),就需要重写父类方法,否则会报错:
class Vehicle:
"""交通工具"""
Country = ‘China‘
def __init__(self, name, speed, load, power):
"""名字、速度、负载、能量"""
self.name = name
self.speed = speed
self.load = load
self.power = power
def run(self):
print(‘%s今天开通~‘ % self.name)
class Subway(Vehicle):
"""地铁"""
def __init__(self, line):
"""名字、速度、负载、能量、几号线"""
self.line = line
def test():
pass
line1 = Subway(1)
line1.run() # AttributeError: ‘Subway‘ object has no attribute ‘name‘子类 Subway 中调用父类 Vehicle 的 run 方法,报 AttributeError: ‘Subway‘ object has no attribute ‘name‘。显然调用没有成功。
那么我们可以重写父类的方法:
class Subway(Vehicle):
"""地铁"""
def __init__(self, name, speed, load, power, line): # 调用父类的属性
"""名字、速度、负载、能量、几号线"""
self.name = name
self.speed = speed
self.load = load
self.power = power
self.line = line
def run(self):
print(‘%s今天开通~‘ % self.name)
print(‘%s%s号线开通啦~‘ % (self.name, self.line))
line1 = Subway(‘长沙地铁‘, ‘200km/h‘, 1000, ‘electric‘, 1)
line1.run() # 调用与父类同名的方法
------------------------------
长沙地铁今天开通~
长沙地铁1号线开通啦~当子类中与父类方法同名时,优先调用子类本身的。但是如果也想实现父类中的功能,就需要在子类相应的方法中重写,若有几十上百行代码,重写就显得有点麻烦。
Python 给我们提供了两种解决方法:
- 调用未绑定的父类方法
- 使用 super 函数
调用未绑定的父类方法
只需在子类中需要调用父类的方法中,加上这样一行代码即可:
类名.__init__(self, x, y...) # 调用父类中的变量
类名.test(self) # 调用父类方法具体示例如下:
class Subway(Vehicle):
"""地铁"""
def __init__(self, name, speed, load, power, line):
"""名字、速度、负载、能量、几号线"""
Vehicle.__init__(self, name, speed, load, power) # 调用几个变量就添加几个
self.line = line
def run(self):
Vehicle.run(self)
print(‘%s%s号线开通啦~‘ % (self.name, self.line))
line1 = Subway(‘长沙地铁‘, ‘200km/h‘, 1000, ‘electric‘, 1)
line1.run()
----------------------------------------
长沙地铁今天开通~
长沙地铁1号线开通啦~5.1.6 super 函数
在子类中调用父类方法,使用上面的方法,有个缺点:一旦父类名字变化,后面调用逻辑就需要大量更改被继承的方法。Python 还提供了另一种方法:super()函数。
它可以自动找到父类的方法,并且自动传入 self 参数。无需关心父类的名字,不需要去大量修改被继承的方法:
super().meth([args])
class Subway(Vehicle):
"""地铁"""
def __init__(self, name, speed, load, power, line):
"""名字、速度、负载、能量、几号线"""
super().__init__(name, speed, load, power)
self.line = line
def run(self):
super.run()
print(‘%s%s号线开通啦~‘ % (self.name, self.line))
line1 = Subway(‘长沙地铁‘, ‘200km/h‘, 1000, ‘electric‘, 1)
line1.run()
----------------------------------------
长沙地铁今天开通~
长沙地铁1号线开通啦~5.2 多肽
由不同的类实例化得到的对象,调用同一个方法,执行的逻辑不同。对象如何通过他们共同的属性和动作来操作及访问,而不考虑他们具体的类。
#_*_coding:utf-8_*_
__author__ = ‘Hubery_Jun‘
class H2O:
def __init__(self, name, temperature):
self.name = name
self.temperature = temperature
def turn_ice(self):
if self.temperature < 0:
print(‘[%s]水温太低,结冰了‘ % self.name)
elif self.temperature > 0 and self.temperature < 100:
print(‘[%s]液态化成水‘ % self.name)
elif self.temperature > 100:
print(‘[%s]温度太高变成水蒸气了‘ % self.name)
class Water(H2O):
pass
class Ice(H2O):
pass
class Steam(H2O):
pass
w1 = Water(‘水‘, 25)
i1 = Water(‘冰‘, -25)
s1 = Water(‘水蒸气‘, 3000)
# w1.turn_ice()
# i1.turn_ice()
# s1.turn_ice()
def func(obj):
obj.turn_ice()
func(w1)
func(i1)
func(s1)[水]液态化成水
[冰]水温太低,结冰了
[水蒸气]温度太高变成水蒸气了对象 w1、i1、s1 由不同的类实例而来,但是它们调用同一个方法 turn_ice()。我们可以定义一个函数 func,专门用来处理 turn_ice() 方法,不需要关心类内部逻辑,只需考虑对象的类型,这就是多肽。
5.3 封装
5.3.1 公有私有数据属性
一般面向对象编程语言都有公有私有数据属性,Java、C++ 使用 public 和 private 关键字来区分。而 Python 默认对象的属性和方法都是公开的(即公有的),可以直接通过点(.)来访问。
class Person:
name = ‘rose‘
def __init__(self, age, gender):
self.age = age
self.gender = gender
p1 = Person(18, ‘female‘)
print(p1.name)
----------------
rose为了实现类似私有变量的特性,Python 有一种约束,可以对要私有化的变量,在其前面加一条下划线(_)。但是从外部也可以访问,这是一种约束,约束看到这种变量就不去调用:
_name = ‘rose‘Python 内部采用一种叫 name mangling(名字改编) 的技术,只**需在变量名前加双下划线即可(__),那么这个变量就变成了私有变量**:
__name = ‘rose‘
print(p1.__name) # AttributeError: ‘Person‘ object has no attribute ‘_name‘其实 Python 目前的私有机制是伪私有,在外部还是可以通过 _类名__变量名 的方式去访问私有变量:
print(p1._Person__rose())
print(Person.__dict__){‘__module__‘: ‘__main__‘, ‘_Person__name‘: ‘rose‘, ‘__init__‘: <function Person.__init__ at 0x00000000053D6598>, ‘__dict__‘: <attribute ‘__dict__‘ of ‘Person‘ objects>, ‘__weakref__‘: <attribute ‘__weakref__‘ of ‘Person‘ objects>, ‘__doc__‘: None}
rose可以发现在 Python 内部,将原有的变量名改变了名字:(__rose 变成了 _Person__name。
5.3.2 封装的三个层面
- 类本身就是对数据和函数的一种封装。
- 另一种封装类中定义私有属性,内部能访问,外部不能访问。
- 明确区分内外,内部的实现逻辑,外部无法知晓。并且为封装到内部的逻辑提供一个访问接口给外部使用(这才是真正的封装)
class Person:
name = ‘rose‘
def __init__(self, age, gender):
self.__age = age
self.__gender = gender
# 接口函数
def interface_func(self):
return self.__age, self.__gender
p1 = Person(18, ‘female‘)
print(p1.interface_func())
--------------------------
(18, ‘female‘)对于类中已经封装的方法,只能在内部访问,外部要想访问。我们可以定义一个接口函数,然后调用接口函数间接使用封装的方法。但是在实际开发中应谨慎使用接口函数,滥用接口函数就会导致类 千疮百孔。
5.4 总结
面向对象是一种更高级的结构化编程方式,其优点有两点:
- 通过封装,明确内外。外部调用无需知道内部逻辑。
- 通过继承和多肽在语言层面支持归一化设计
6. 反射
反射是指程序可以访问、检查和修改它本身状态或行为的一种能力(自省)。Python 内部实现自省的四个函数:hasattr()、getattr()、setattr()、delattr() 。
6.1.1 实现反射的四个函数
class Animal:
def __init__(self, name, color):
self.name = name
self.color = color
def eat(self):
print(‘【%s】正则吃东西‘ % self.name)
a1 = Animal(‘dog‘, ‘black‘)1. hasattr(object, name)
判断一个对象中是否有指定的属性,第一个参数为对象,第二个为属性名。
print(hasattr(a1, ‘name‘)) # True
print(hasattr(a1, ‘eat‘)) # True
print(hasattr(a1, ‘edfa‘)) # False2. getattr(object, name[,default])
返回对象的指定属性,若属性不存在且未指定默认值,抛出 AttributeError 异常。指定默认值返回默认值。
print(getattr(a1, ‘name‘)) # dog
print(getattr(a1, ‘eat‘)) # <bound method Animal.eat of <__main__.Animal object at 0x00000000025ACEF0>>
#print(getattr(a1, ‘edfa‘)) # AttributeError: ‘Animal‘ object has no attribute ‘edfa‘
print(getattr(a1, ‘edfa‘, ‘没有找到‘)) # 没有找到3. setattr(object, name, value)
设置对象中指定属性的值,如属性不存在则新增,存在则修改。
# a1.name = ‘cat‘ # 常规修改方法
setattr(a1, ‘name‘, ‘cat‘) # 修改
setattr(a1, ‘age‘, 1) # 新增4. delattr(object, name)
删除对象指定的属性,属性不存在抛出 AttributeError 异常。
# a1.name # 常规修改方法
delattr(a1, ‘name‘)6.1.2 反射的应用场景
反射的有两大好处:一是可以实现可插拔机制,二是动态导入模块(基于反射当前模块成员)
实现可插拔机制
比如说有两个程序员,分别负责开发两个模块ftp_client.py、user.py 。user.py 依赖 ftp_client.py。若哪天负责开发 ftp_client.py 的程序员突然去有事了,为了不影响整体进度,我们可以利用反射判断 ftp_client.py 是否实现了某个功能,即使没实现也不会报错:
# ftp_client.py
class FtpClient:
‘ftp 客户端,具体功能尚未实现‘
def __init__(self, addr):
print(‘正在连接服务器【%s】‘ % addr)
self.addr = addr利用 hasattr() 判断 FtpClient 类 中是否有 put 方法,若有则获取,否则继续实现其他功能逻辑:
# user.py
from ftp_client import FtpClient
f1 = FtpClient(‘8.8.8.8‘)
if hasattr(f1, ‘put‘):
func_put = getattr(f1, ‘put‘)
func_put()
else:
print(‘put 功能尚未实现‘)
print(‘其他功能逻辑‘)动态导入模块
若导入的模块是字符串形式,我们之前可以采用 __import__() 函数导入。
包 h 下有个 a1 模块,要想在另一个模块中调用 a1 中的 test() 函数:
r = __import__(‘h.a1‘)
r.a1.test()另一种方式是利用 importlib 模块,动态导入模块:
import importlib
r = importlib.import_module(‘h.a1‘)
r.test()6.1.3 __getattr__、__setarrr__、__delattr__
__getattr__
当获取不存在的属性时触发:
class Foo:
x = 1
def __init__(self, y):
self.y = y
def __getattr__(self, item):
print(‘属性【%s】不存在~‘ % item)
f1 = Foo(10)
print(f1.y) # 10
print(f1.s) # 属性【s】不存在~、None对象 f1 传给 self,y 或 s 传给 item。
__setattr__
设置属性时触发
def __setattr__(self, key, value):
print(‘正在设置属性~‘)
# self.key = value
# RecursionError: maximum recursion depth exceeded in comparison(超出最大递归深度)
self.__dict__[key] = value
f1 = Foo(10)
f1.m = 20
print(f1.__dict__)
# 正在设置属性~
# 正在设置属性~
# {‘y‘: 10, ‘m‘: 20}__delattr__
删除属性时触发
def __delattr__(self, item):
print(‘正在删除~‘)
f1 = Foo(10)
del f1.y
del f1.x
# 正在删除~
# 正在删除~7. 二次加工标准类型(包装)
Python 提供了很多内置的标准数据类型,以及内置方法。在很多场景下我们需要基于标准数据类型来定制我们自己的类型,新增或改写方法。我们可以用继承/派生来对标准类型进行二次加工:
需求:
基于 list 新增一个方法用于返回列表中间元素,修改 list 内置的 append 方法,要求只有当新增的元素是字符串时才能添加进去。
class List(list):
"""继承 list 所有的属性,也派生自己的,比如 append,mid"""
def append(self, str_obj):
"""派生自己的 append:类型检查"""
if isinstance(str_obj, str):
super().append(str_obj) # 调用父类的 append()方法,调用自己的会无限递归直至溢出
else:
print(‘必须是字符串类型‘)
def mid(self):
"""新增属性"""
middle = int(len(self)/2)
return ‘列表%s,中间元素是【%s】‘ % (self, self[middle])
# 新增属性
# List 继承 list,那么 List(‘hello‘)相当于 list(‘hello‘) ,self 为实例本身,那么 self = list(‘heelo‘)’)
l1 = List(‘hello‘) # 列表[‘h‘, ‘e‘, ‘l‘, ‘l‘, ‘o‘],中间元素是【l】
l1.mid()
# # 派生自己的 append
# l2 = List(‘hello‘)
# l2.append(‘2‘)
# print(l2) # [‘h‘, ‘e‘, ‘l‘, ‘l‘, ‘o‘, ‘2‘]
# l2.append(3) # 必须是字符串类型授权
授权是包装的另一特性,它与包装的区别在于:
- 包装: 通常是对已存在的类型进行定制,可新建、修改和删除原有类型的功能,其他则不变。(继承和派生)
- 授权: 对于已存在的功能授权给对象的默认属性,更新的功能交给类的某些方法来处理。 (组合)
授权的关键点在于覆盖 __getattr__
需求: 模拟 open 函数的read、write 方法,要求 read 方法交给类方法处理,write 方法授权给对象默认属性:
read 方法
class FileHandle:
"""模拟 open 函数"""
def __init__(self, file, mode=‘r‘, encoding=‘utf-8‘):
self.file = open(file, mode, encoding=encoding) # 文件句柄或文件对象 <_io.TextIOWrapper name=‘a.txt‘ mode=‘r+‘ encoding=‘utf-8‘>
def __getattr__(self, item):
# print(‘不存在‘)
print(self, item) # self:f1,item:‘read‘
return getattr(self.file, item) # 在文件对象中查找 字符串 read
f1 = FileHandle(‘a.txt‘, ‘r+‘)
print(f1.read()) # read = f1.read, print(read())
# f1.read 不存在则会触发 __getattr__
--------------
# aaaaa类 FileHandle 的构造函数中以组合的形式,将参数传给 open() 函数。获得文件句柄 self.file,利用文件句柄我们可以对文件进行读写操作。
类中不存在 read 方法,因此 f1.read 会触发 __getattr__() ,然后利用 getattr 获得 open 函数的 read 属性(或方法),最后返回。
write 方法
import time
def write(self, line):
t = time.strftime(‘%Y-%m-%d %X‘) # 获取当前字符串时间
time.sleep(0.1)
self.file.write(‘%s %s‘ % (line, t))
# 把 write 授权给 FileHandle
f1 = FileHandle(‘a.txt‘, ‘r+‘)
f1.write(‘第一行
‘)
f1.write(‘第二行
‘)
f1.write(‘第三行
‘)
f1.seek(0) # seek 不存在,触发 __getattr__
print(f1.read())以上是关于面向对象的主要内容,如果未能解决你的问题,请参考以下文章