Kafka实战分析
Posted swordfall
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka实战分析相关的知识,希望对你有一定的参考价值。
1. Kafka概要设计
kafka在设计之初就需要考虑以下4个方面的问题:
- 吞吐量/延时
- 消息持久化
- 负载均衡和故障转移
- 伸缩性
1.1 吞吐量/延时
对于任何一个消息引擎而言,吞吐量都是至关重要的性能指标。那么何为吞吐量呢?通常来说,吞吐量是某种处理能力的最大值。而对于Kafka而言,它的吞吐量就是每秒能够处理的消息数或者每秒能够处理的字节数。很显然,我们自然希望消息引擎的吞吐量越大越好。
消息引擎系统还有一个名为延时的性能指标。它衡量的是一段时间间隔,可能是发出某个操作与接收到操作响应(response)之间的时间,或者是在系统中导致某些物理变更的起始时刻与变更正式生效时刻之间的间隔。对于Kafka而言,延时可以表示客户端发起请求与服务器处理请求并发送响应给客户端之间的这一段时间。显而易见,延时间隔越短越好。
在实际使用场景中,这两个指标通常是一对矛盾体,即调优其中一个指标通常会使另一个指标变差。在采取一定延时的同时采用批处理的思想,即一小批一小批(micro-batch)地发送,则会大大提升吞吐量。
Kafka是如何做到高吞吐量、低延时的呢?首先,Kafka的写入操作是很快的,这主要得益于它对磁盘的使用方法的不同。虽然Kafka会持久化所有数据到磁盘,但本质上每次写入操作其实都只是把数据写入到操作系统的页缓存(page cache)中,然后由操作系统自行决定什么时候把页缓存中的数据写回磁盘上。这样的设计有3个主要优势。
- 操作系统页缓存是在内存中分配的,所以消息写入的速度非常快。
- Kafka不必直接与底层的文件系统打交道。所有繁琐的I/O操作都交由操作系统来处理。
- Kafka写入操作采用追加写入(append)的方式,避免了磁盘随机写操作。
请特别留意上面的第3点。对于普通的物理磁盘(非固态硬盘)而言,我们总是认为磁盘的读/写操作是很慢的。事实上普通SAS磁盘随机读/写的吞吐量的确是很慢的,但是磁盘的顺序读/写操作其实是非常快的,它的速度甚至可以匹敌内存的随机I/O速度,如图1.5所示。随机内存I/O的速度是36.7MB/s,而顺序磁盘I/O的速度甚至达到了52.2MB/s,丝毫不逊于内存的I/O操作性能。
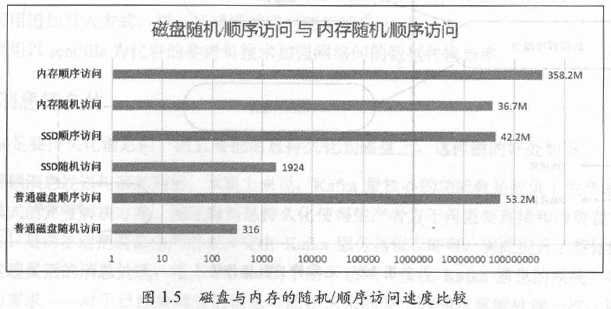
鉴于这一事实,Kafka在设计时采用了追加写入消息的方式,即只能在日志文件末尾追加写入新的消息,且不允许修改已写入的消息,因此它属于典型的磁盘顺序访问型操作,所以Kafka消息发送的吞吐量是很高的。在实际使用过程中可以很轻松地做到每秒写入几万甚至几十万条消息。
下面我们来看看Kafka的消费端是如何做到高吞吐量、低延时的。之前提到了Kafka是把消息写入操作系统的页缓存中的。那么同样地,Kafka在读取消息时会首先尝试从OS的页缓存中读取,如果命中便把消息经页缓存直接发送到网络的Socket上。这个过程就是利用Linux平台的sendfile系统调用做到的,而这种技术就是大名鼎鼎的零拷贝(Zero Copy)技术。
总结一下,Kafka就是依靠下列4点达到了高吞吐量、低延时的设计目标的。
- 大量使用操作系统页缓存,内存操作速度快且命中率高。
- Kafka不直接参与物理I/O操作,而是交由最擅长此事的操作系统来完成。
- 采用追加写入方式,摒弃了缓慢的磁盘随机读/写操作。
- 使用以sendfile为代表的零拷贝技术加强网络间的数据传输效率。
1.2 消息持久化
Kafka是要持久化消息的,而且要把消息持久化到磁盘上。这样做的好处如下:
- 解耦消息发送与消息消费:本质上来说,Kafka最核心的功能就是提供了生产者-消费者模式的完整解决方案。通过使消息持久化使得生产者不再需要直接和消费者方耦合,它只是简单地把消息生产出来并交由Kafka服务器保存即可,因此提升了整体的吞吐量。
- 实现灵活的消息处理:很多的Kafka的下游子系统(接收Kafka消息的系统)都有这样的需求——对于已经处理过的消息可能在未来的某个时间点重新处理一次,即所谓的消息重演。
另外,Kafka实现持久化的设计也有新颖之处。普通的系统在实现持久化时可能会先尽量使用内存,当内存资源耗尽时,再一次性地把数据“刷盘”;而Kafka则反其道而行之,所有数据都会立即被写入文件系统的持久化日志中,之后Kafka服务器才会返回结果给客户端通知它们消息已被成功写入。这样做既实时保存了数据,又减少了Kafka程序对于内存的消耗,从而将节省出的内存留给页缓存使用,更进一步地提升了 整体性能。
1.3 负载均衡和故障转移
何为负载均衡?顾名思义就是让系统的负载根据一定的规则均衡地分配在所有参与工作的服务器上,从而最大限度地提升系统整体的运行效率。具体到Kafka来说,默认情况下Kafka的每台服务器都有均等的机会为Kafka的客户提供服务,可以把负载分散到所有集群中的机器上,避免出现“耗尽某台服务器”的情况发生。
Kafka实现负载均衡实际上是通过智能化的分区领导者选举(partition leader election)来实现的。Kafka默认提供了很智能的leader选举算法,可以在集群的所有机器上以均等机会分散各个partition的leader,从而整体上实现了负载均衡。
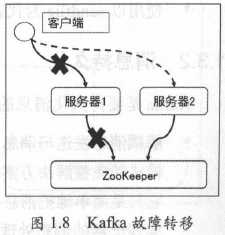
除了负载均衡,完备的分布式系统还需要支持故障转移。所谓故障转移,是指当服务器意外中止时,整个集群可以快速地检测到该失效(failure),并立即将该服务器上的应用或服务自动转移到其他服务器上。故障转移通常是以“心跳”或“会话”的机制来实现的,即只要主服务器与备份服务器之间的心跳无法维持或主服务器注册到服务器中心的会话超时过期了,那么就认为主服务器已无法正常运行,集群会自动启动某个备份服务器来替代主服务器的工作。
Kafka服务器支持故障转移的方式就是使用会话机制。每台Kafka服务器启动后会以会话的形式把自己注册到Zookeeper服务器上。一但该服务器运转出现问题,与Zookeeper的会话便不能维持从而超时失效,此时Kafka集群会选举出另一台服务器来完成代替这台服务器继续提供服务,如图1.8所示:
1.4 伸缩性
所谓伸缩性,表示向分布式系统中增加额外的计算资源(比如CPU、内存、存储或带宽)时吞吐量提升的能力。阻碍线性扩容的一个很常见的因素就是状态的保存。我们知道,不论是哪类分布式系统,集群中的每台服务器一定会维护很多内部状态。如果由服务器自己来保存这些状态信息,则必须要处理一致性的问题。相反,如果服务器是无状态的,状态的保存和管理交于专门的协调服务来做(比如Zookeeper),那么整个集群的服务器之间就无须繁重的状态共享,这极大地降低了维护复杂度。倘若要扩容集群节点,只需简单地启动新的节点机器进行自动负载均衡就可以了。
Kafka正是采用了这样的思想——每台Kafka服务器上的状态统一交由ZooKeeper保管。扩展Kafka集群也只需要一步:启动新的Kafka服务器即可。
2. Kafka基本概念与术语
在Kafka 0.10.0.0版本正式推出了Kafka Streams,即流式处理组件。自此Kafka正式成为了一个流式处理框架,而不仅仅是消息引擎了。Kafka的架构图如下:
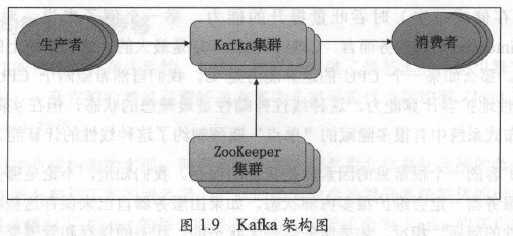
不论Kafka如何变迁,其核心架构总是类似的,无非是生产一些消息然后再消费一些消息。如果总结起来那就是三句话:
- 生产者发送消息给Kafka服务器。
- 消费者从Kafka服务器读取消息。
- Kafka服务器依托于ZooKeeper集群进行服务的协调管理
Kafka服务器即broker。Kafka有一些基本术语需要掌握,这是后续学习Kafka的基础。首先,Kafka是分布式的集群。一个集群可能由一台或多台机器组成。Kafka集群中保存的每条消息都归属于一个topic。本节将分别从消息、topic、partition和replica几个方面详细介绍Kafka的基本概念。
2.1 消息
Kafka的消息格式由很多字段组成,其中的很多字段都是用于管理消息的元数据字段,对用户来说是完全透明的。Kafka消息格式共经历过3次变迁,它们被分别称为V0,V1和V2版本。目前大部分用户使用的应该还是V1版本的消息格式。V1版本消息的完整格式如图1.10所示。
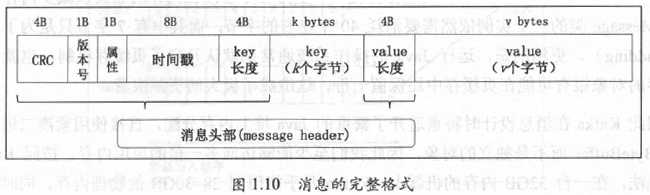
如图1.10所示,消息由消息头部、key和value组成。消息头部包括消息的CRC码、消息版本号、属性、时间戳、键长度和消息体长度等信息。其实,对于普通用户来说,掌握以下3个字段的含义就足够一般的使用了。
- Key:消息键,对消息做partition时使用,即决定消息被保存在某topic下的哪个partition。
- Value:消息体,保存实际的消息数据。
- Timestamp:消息发送时间戳,用于流式处理及其他依赖时间的处理语义。如果不指定则取当前时间。
另外这里单独提一下消息的属性字段,Kafka为该字段分配了1字节。目前只使用了最低的3位用于保存消息的压缩类型,其余5位尚未使用。当前只支持4种压缩类型:0(无压缩)、1(GZIP)、2(Snappay)和3(LZ4)。
其次,Kafka使用紧凑的二进制字节数组来保存上面这些字段,也就是说没有任何多余的比特位浪费。在Java内存模型(Java memory model,JMM)中,对象保存的开销其实相当大,对于小对象而言,通常要花费2倍的空间来保存数据(甚至更糟)。另外,随着堆上数据量越来越大,GC的性能会下降很多,从而整体上拖慢了系统的吞吐量。因此Kafka在消息设计时特意避开了繁重的Java堆上内存分配,直接使用紧凑二进制字节数组ByteBuffer而不是独立的对象,因此我们至少能够访问多一倍的可用内存。按照Kafka官网的说法,在一台32GB内存的机器上,Kafka几乎能用到28~30GB的物理内存,同时还不必担心GC的糟糕性能。
同时,大量使用页缓存而非堆内存还有一个好处——当出现Kafka broker进程崩溃时,堆内存上的数据也一并消失,但页缓存的数据依然存在。下次Kafka broker重启后可以继续提供服务,不需要再单独“热”缓存了。
2.2 topic和partition
在本节中我们详细说说这两个Kafka核心概念。
从概念上来说,topic只是一个逻辑概念,代表了一类消息,也可以认为是消息被发送到的地方。通常我们可以使用topic来区分实际业务,比如业务A使用一个topic,业务B使用另外一个topic。
Kafka中的topic通常都会被多个消费者订阅,因此出于性能的考量,Kafka并不是topic-message的两级结构,而是采用了topic-partition-message的三级结构来分散负载。从本质上说,每个Kafka topic都由若干个partition组成,如图1.11所示。
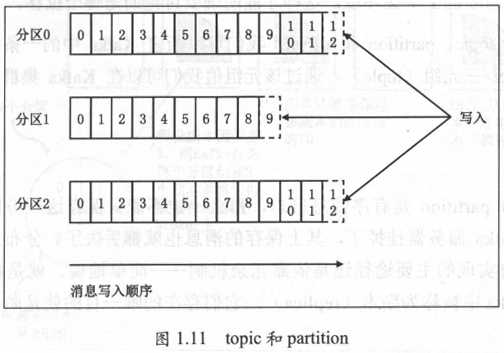
这张来自Kafka官网的topic和partition关系图非常清楚地表明了它们二者之间的关系:topic是由多个partition组成的。而Kafka的partition是不可修改的有序消息序列,也可以说是有序的消息日志。每个partition有自己专属的partition号,通常是从0开始的。用户对partition唯一能做的操作就是在消息序列的尾部追加写入消息。partition上的每条消息都会被分配一个唯一的序列号——按照Kafka的术语来讲,该序列号被称为位移(offset)。该位移值是从0开始顺序递增的整数。位移信息可以唯一定位到某partition下的一条消息。
值得一提的是,Kafka的partition实际上并没有太多的业务含义,它的引入就是单纯地为了提升系统的吞吐量,因此在创建kafka topic的时候可以根据集群实际配置设置具体的partition数,实现整体性能的最大化。
2.3 offset
前面说过,topic partition下的每条消息都被分配一个位移值。实际上,Kafka消费者端也有位移(offset)的概念,但一定要注意这两个offset属于不同的概念,如图1.12所示。
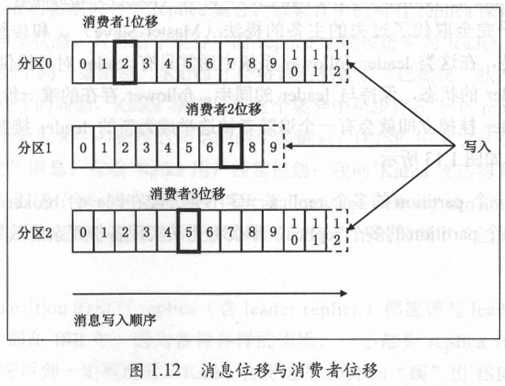
显然,每条消息在某个partition的位移是固定的,但消息该partition的消费者的位移会随着消费进度不断前移,但终究不可能超过该分区最新一条消息的位移。在以后讨论位移的时候要注意区分是生产位移还是消费位移的。
综合之前说的topic、partition和offset,我们可以断言Kafka中的一条消息其实就是一个<topic,partition,offset>三元组(tuple),通过该元组值我们可以在Kafka集群中找到唯一对应的那条消息。
2.4 replica
分布式系统必然要实现高可靠性,而目前实现的主要途径还是依靠冗余机制——简单地说,就是备份多份日志。这些备份日志在Kafka中被称为副本(replica),它们存在的唯一目的就是防止数据丢失。
副本分为两类:领导者副本(leader replica)和追随者副本(follower replica)。follower replica 是不能提供服务给客户端的,也就是说不负责响应客户端发来的消息写入和消息消费请求。它只是被动地向领导者副本(leader replica)获取数据,而一旦leader replica所在的broker宕机,kafka会从剩余的replica中选举出新的leader继续提供服务。
2.5 leader和follower
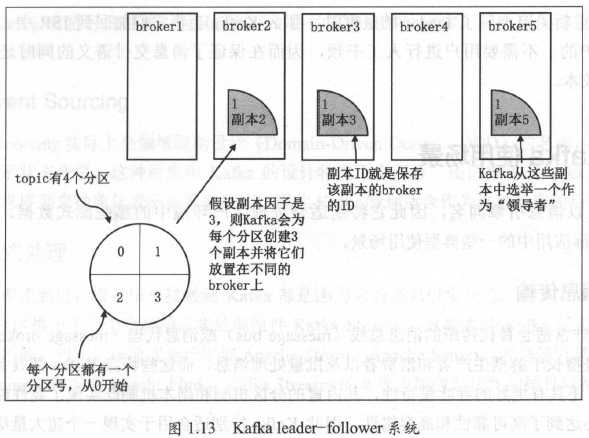
如前所述,Kafka的replica分为两个角色:领导者(leader)和追随者(follower)。如今这种角色设定几乎完全取代了过去的主备的提法(Master-Slave)。和传统主备系统(比如mysql)不同的是,在这类leader-follower系统中通常只有leader对外提供服务,follower只是被动地追随leader的状态,保持与leader的同步。follower存在的唯一价值就是充当leader的候补:一旦leader挂掉立即就会有一个追随者被选举成为新的leader接替它的工作。Kafka就是这样的设计,如图1.13所示。
Kafka保证同一个partition的多个replica一定不会分配在同一台broker上。毕竟如果同一个broker上有同一个partition的多个replica,那么将无法实现备份冗余的效果。
2.6 ISR
ISR的全称是in-sync replica,翻译过来就是与leader replica保持同步的replica集合。这是一个特别重要的概念。前面讲了很多关于Kafka的副本机制,比如一个partition可以配置N个replica,那么这是否就意味着该partition可以容忍N-1个replica失效而不丢失数据呢?答案是“否”!
Kafka为partition动态维护一个replica集合。该集合中的所有replica保存的消息日志都与leader replica保持同步状态。只有这个集合中的replica才能被选举为leader,也只有该集合中所有replica都接收到了同一条消息,kafka才会将该消息置于“已提交”状态,即认为这条消息发送成功。回到刚才的问题,Kafka承诺只要这个集合中至少存在一个replica,那些“已提交”状态的消息就不会丢失——记住这句话的两个关键点:①ISR中至少存在一个“活着的”replica;②“已提交”消息。
正常情况下,partition的所有replica(含leader replica)都应该与leader replica保持同步,即所有replica都在ISR中。因为各种各样的原因,一小部分replica开始落后于leader replica的进度。当滞后到一定程度时,Kafka会将这些replica“踢”出ISR。相反地,当这些replica重新“追上”了leader的进度时,那么Kafka会将它们加回到ISR中。这一切都是自动维护的,不需要用户进行人工干预,因而在保证了消息交付语义的同时还简化了用户的操作成本。
3. Kafka使用场景
Kafka以消息引擎闻名,因此它特别适合处理生产环境中的那些流式数据。以下就是Kafka在实际应用中的一些典型使用场景。
3.1 消息传输
Kafka非常适合替代传统的消息总线(message bus)或消息代理(message broker)。传统的这类系统擅长于解耦生产者和消费者以及批量处理消息,而这些特点Kafka都具备。除此之外,Kafka还具有更好的吞吐量特性,其内置的分区机制和副本机制既实现了高性能的消息传输,同时还达到了高可靠性和高容错性。因此Kafka特别适合用于实现一个超大量级消息处理应用。
3.2 网站行为日志追踪
Kafka最早就是用于重建用户行为数据追踪系统的。很多网站上的用户操作都会以消息的形式发送到Kafka的某个对应的topic上。这些点击流蕴含了巨大的商业价值,事实上,目前就有很多创业公司使用机器学习或其他实时处理框架来帮助收集并分析用户的点击流数据。鉴于这种点击流数据量时很大的,Kafka超强的吞吐量特性此时就有了用武之地。
3.3 审计数据收集
很多企业和组织都需要对关键的操作和运维进行监控和审计。这就需要从各个运维应用程序处实时汇总操作步骤信息进行集中式管理。在这种使用场景下,你会发现Kafka是非常适合的解决方案,它可以便捷地对多路消息进行实时收集,同时由于其持久化的特性,使得后续离线审计成为可能。
3.4 日志收集
这可能是Kafka最常见的使用方式了——日志收集汇总解决方案。每个企业都会产生大量的服务日志,这些日志分散在不同的机器上。我们可以使用Kafka对它们进行全量收集,并集中送往下游的分布式存储中(比如HDFS等)。比起其他主流的日志抽取框架(比如Apache Flume),Kafka有更好的性能,而且提供了完备的可靠性解决方案,同时还保持了低延时的特点。
3.5 Event Sourcing
Event Sourcing实际上是领域驱动设计(Domain-Driven Design,DDD)的名词,它使用事件序列表示状态变更,这种思想和Kafka的设计特性不谋而合。还记得吧,Kafka也是用不可变更的消息序列来抽象化表示业务消息的,因此Kafka特别适合作为这种应用的后端存储。
3.6 流式处理
前面简要提到过,很多用户接触到Kafka都是因为它的消息引擎功能。自0.10.0.0版本开始,Kafka社区推出了一个全新的流式处理组件Kafka Streams。这标志着Kakfa正式进入流式处理框架俱乐部。相比Apache Storm、Apache Samza,或是最近风头正劲的Spark Streaming,抑或是Apache Flink,Kafka Streams目前还有点差距,相信后面完善会越来越好。
4. Kafka新版本功能简介
4.1 新版本功能简介
在Kafka世界中,通常把producer和consumer通称为客户端(即clients),这是与服务器(即broker)相对应的。
新版本producer
在Kafka 0.9.0.0版本中,社区正式使用Java版本的producer替换了原Scala版本的producer。新版本的producer的主要入口类是org.apache.kafka.clients.producer.KafkaProducer,而非原来的kafka.producer.Producer。
新版本producer重写了之前服务器端代码提供的很多数据结构,摆脱了对服务器端代码库的依赖,同时新版本的producer也不再依赖于Zookeeper,甚至不需要和Zookeeper集群进行直接交互,降低了系统的维护成本,也简化了部署producer应用的开销成本。一段典型的新版本producer代码如下:
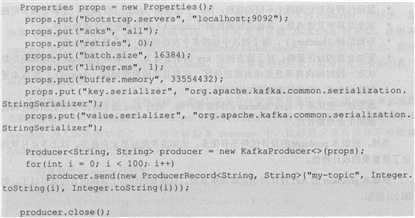
上面的代码中比较关键的是KafkaProducer.send方法,它是实现发送逻辑的主要入口方法。新版本producer整体工作流程图如图2.2所示。
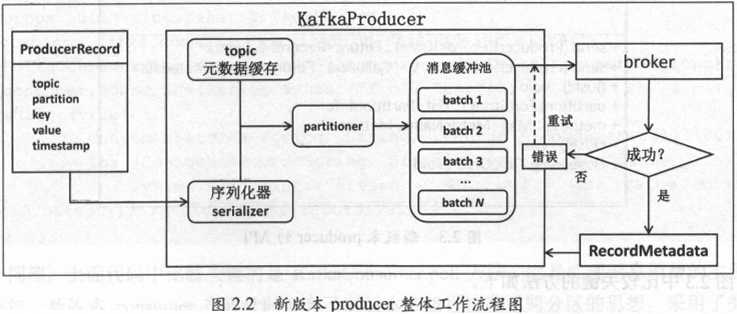
新版本的producer大致就是将用户待发送的消息封装成一个ProducerRecord对象,然后使用KafkaProducer.send方法进行发送。实际上,KafkaProducer拿到消息后对其进行序列化,然后结合本地缓存的元数据信息确立目标分区,最后写入内存缓冲区。同时,KafkaProducer中还有一个专门的Sender I/O线程负责将缓冲区中的消息分批次发送给Kafka broker。
比起旧版本的producer,新版本在设计理念上有以下几个特点(或者说是优势)。
- 发送过程被划分到两个不同的线程:用户主线程和Sender I/O线程,逻辑更容易把控。
- 完全是异步发送消息,并提供回调机制(callback)用于判断发送成功与否。
- 分批机制(batching),每个批次中包括多个发送请求,提升整体吞吐量。
- 更加合理的分区策略:对于没有指定key的消息而言,旧版本producer分区策略是默认在一段时间内将消息发送到固定分区,这容易造成数据倾斜;新版本采用轮询方式,消息发送将更加均匀化。
- 底层统一使用基于Java Selector的网络客户端,结合Java的Future实现更加健壮和优雅的生命周期管理。
新版本producer的API中比较关键的方法如下:
- send:实现消息发送的主逻辑方法。
- close:关闭producer。
- metrics:获取producer的实时监控指标数据,比如发送消息的速率等。
新版本consumer
Kafka 0.9.0.0 版本不仅废弃了旧版本producer,还提供了新版本的consumer。同样地,新版本consumer也是使用Java语言编写的,也不再需要依赖Zookeeper的帮助。新版本consumer的入口类是org.apache.kafka.clients.consumer.KafkaConsumer。由此也可以看出,新版本客户端的代码包都是org.apache.kafka.clients,这一点需要特别注意,因为它是区分新旧客户端的一个重要特征。
在旧版本consumer中,消费位移(offset)的保存与管理都是依托于ZooKeeper来完成的。当数据量很大且消费很频繁时,ZooKeeper的读/写性能往往容易成为系统瓶颈。这是旧版本consumer为人逅病的缺陷之一。而在新版本consumer中,位移的管理与保存不再依靠ZooKeeper了,自然这个瓶颈就消失了。
一段典型的consumer代码如下:
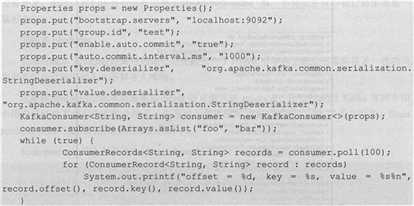
同理,上面代码中比较关键的是KafkaConsumer.poll方法。它是实现消息消费的主逻辑入口方法。新版本consumer在设计时摒弃了旧版本多线程消费不同分区的思想,采用了类似于Linux epoll的轮询机制,使得consumer只使用一个线程就可以管理连向不同broker的多个Socket,既减少了线程间的开销成本,同时也简化了系统的设计。
比起旧版本consumer,新版本在设计上的突出优势如下:
- 单线程设计——单个consumer线程可以管理多个分区的消费Socket连接,极大地简化了实现。虽然0.10.1.0版本额外引入了一个后台心跳线程(background heartbeat thread),不过双线程的设计依然比旧版本consumer鱼龙混杂的多线程设计要简单得多。
- 位移提交与保存交由Kafka来处理——位移不再保存在ZooKeeper中,而是单独保存在Kafka的一个内部topic中,这种设计既避免了ZooKeeper频繁读/写的性能瓶颈,同时也依托Kafka的备份机制天然地实现了位移的高可用管理。
- 消费者组的集中式管理——上面提到了ZooKeeper要管理位移,其实它还负责管理整个消费者组(consumer group)的成员。这进一步加重了对于ZooKeeper的依赖。新版consumer改进了这种设计,实现了一个集中式协调者(coordinator)的角色。所有组成员的管理都交由该coordinator负责,因此对于group的管理将更加可控。
比起旧版本而言,新版本在API设计上提供了更加丰富的功能,新版consumer API其中比较关键的方法如下:
- poll:最重要的方法,它是实现读取消息的核心方法。
- subscribe:订阅方法,指定consumer要消费哪些topic的哪些分区。
- commitSync/commitAsync:手动提交位移方法。新版本consumer允许用户手动提交位移,并提供了同步/异步两种方式。
- seek/seekToBeginning/seekToEnd:设置位移方法。除了提交位移,consumer还可以直接消费特定位移处的消息。
和producer不同的是,目前新旧consumer共存于最新版本的Kafka中。
5. Kafka线上环境部署
5.1 集群环境规划
典型的生产环境至少需要部署多个节点共同组成一个分布式集群整体为我们提供服务。本章将会详细讨论生产环境中集群的安装、配置与验证。不过在此之前,我们还需要解决3个方面的问题。它们分别是操作系统的选型、硬件规划和容量规划。
5.1.1 操作系统的选型
Kafka的服务器端代码是由Scala语言编写的,而新版本客户端代码是由Java语言编写的。和Java一样,Scala编译器会把源程序.scala文件编译成.class文件,因此Scala也是JVM系的语言。因此,只要是支持Java程序部署的平台都应该能够部署Kafka。
目前部署Kafka最多的3类操作系统分别是Linux,OS X和Windows,其中部署在Linux上的最多,而Linux也是推荐的操作系统。
5.1.2 磁盘规划
现在,我们将分别从磁盘、内存、带宽和CPU等几个方面探讨部署Kafka集群所必要的关键规划因素。首先从磁盘开始说起。
众所周知,Kafka是大量使用磁盘的,Kafka的每条消息都必须被持久化到底层的存储中,并且只有被规定数量的broker成功接收后才能通知clients消息发送成功,因此消息越是被更快地保存在磁盘上,处理clients请求的延时越低,表现出来的用户体验也就越好。
在确定磁盘时,一个常见的问题就是选择普通的机械硬盘(HDD)还是固态硬盘(SSD)。机械硬盘成本低且容量大,而SSD通常有着极低的寻道时间(seek time)和存取时间(access time),性能上的优势很大,但同时也有着非常高的成本。因此在规划Kafka线上环境时,读者就需要根据公司自身的实际条件进行有针对性的选型。其实,Kafka使用磁盘的方式在很大程度上抵消了SSD提供的那些突出优势。因为Kafka是顺序写磁盘,而磁盘顺序I/O的性能,即使机械硬盘也是不弱的——顺序I/O不需要频繁地移动磁头,因而节省了耗时的寻道时间。因此对于预算有限且追求高性价比的公司而言,机械硬盘完全可以胜任Kafka存储的任务。
关于磁盘的选择,另一个比较热门的争论就在于,JBOD与磁盘阵列(下称RAID)之争。这里的JBOD全称是Just Bunch Of Disks,翻译过来就是一堆普通磁盘的意思。在部署线上Kafka环境时,应当如何抉择呢?是使用一堆普通商用磁盘进行安装还是搭建专属的RAID呢?具体问题具体分析。
首先分析一下RAID与Kafka的相适性。常见的RAID是RAID 10 ,也被称为RAID 1+0,它结合了磁盘镜像和磁盘条带化两种技术共同保护数据,既实现了不错的性能也提供了很高的可靠性。RAID 10集合了RAID 0 和RAID 1的优点,但在空间上使用了磁盘镜像,因此整体的磁盘使用率只有50%。换句话说就是将一般的磁盘容量都用作提供冗余。自Kafka 0.8.x版本,用户就可以使用RAID作为存储来为Kafka提供服务了。事实上,根据公开的资料显示,LinkedIn公司的Kafka集群就是使用RAID 10作为底层存储的。除了默认提供的数据冗余之外,RAID 10还可以将数据自动地负载分布到多个磁盘上。
由此可见,RAID作为Kafka的底层存储其实主要的优势有两个。
- 提供冗余的数据存储空间。
- 天然提供负载均衡。
以上两个优势对于任何系统而言都是非常好特性。不过对于Kafka而言,Kafka在框架层面其实已经提供了这两个特性:通过副本机制提供冗余和高可靠性,以及通过分散到各个节点的领导者选举机制来实现负载均衡,所以从这方面来看,RAID的优势就显得不是那么明显了。实际上, 依然有很多公司和组织使用或者打算在RAID之上构建Kafka集群。
这里,我们看看LinkedIn公司是怎么做的?LinkedIn公司目前的Kafka就搭建于RAID 10之上。他们在Kafka层面设定的副本数是2,因此根据RAID 10的特性,这套集群实际上提供了4倍的数据冗余,且只能容忍一台broker宕机(因为副本数是2)。若LinkedIn公司把副本数提高到3,那么就提供了6倍的数据冗余。这将是一笔很大的成本开销。但是,如果我们假设LinkedIn公司使用的是JBOD方案。虽然目前JBOD有诸多限制,但其低廉的价格和超高的性价比的确是非常大的优势。另外通过一些简单的设置,JBOD方案可以达到和RAID方案一样的数据冗余效果。比如说,如果使用JBOD并且设置副本数为4,那么Kafka集群依然提供4倍的数据冗余,但是这个方案中整个集群可以容忍最多3台broker宕机而不丢失数据。对比之前的RAID方案,JBOD方案没有牺牲任何高可靠性或是增加硬件成本,同时还提升了整个集群的高可用性。
事实上,LinkedIn公司目前正在计划将整个Kafka集群从RAID 10 迁移到JBOD上。
对于一般的公司或组织而言,选择JBOD方案的性价比更高。另外推荐用户为每个broker都配置多个日志路径,每个路径都独立挂载在不同的磁盘上,这使得多块物理磁盘磁头同时执行物理I/O写操作,可以极大地加速Kafka消息生产的速度。
最后关于磁盘的一个建议就是,尽量不要使用NAS(Network Attached Storage)这样的网络存储设备。对比本地存储,人们总是认为NAS方案速度更快也更可靠,其实不然。NAS一个很大的弊端在于,它们通常都运行在低端的硬件上,这就使得它们的性能很差,可能比一台笔记本电脑的硬盘强不了多少,表现为平均延时有很大的不稳定性,而几乎所有高端的NAS设备厂商都售卖专有的硬件设备,因此成本的开销也是一个需要考虑的因素。
综合以上所有的考量,硬盘规划的结论性总结如下。
- 追求性价比的公司可以考虑使用JBOD。
- 使用机械硬盘完全可以满足Kafka集群的使用,SSD更好。
5.1.3 磁盘容量规划
Kafka集群到底需要多大的磁盘容量?这又是一个非常经典的规划问题。如前所述,Kafka的每条消息都保存在实际的物理磁盘中,这些消息默认会被broker保存一段时间之后清除。这段时间是可以配置的,因此用户可以根据自身实际业务场景和存储需求来大致计算线上环境所需的磁盘容量。
让我们以一个实际的例子来看下应该如何思考这个问题。假设在你的业务场景中,clients每天会产生1亿条消息,每条消息保存两份并保留一周的时间,平均一条消息的大小是1KB,那么我们需要为Kafka规划多少磁盘空间呢?如果每天1亿条消息,那么每天产生的消息会占用1亿 * 2 * 1KB / 1000 /1000 = 200GB的磁盘空间。我们最好在额外预留10%的磁盘空间用于其他数据文件(比如索引文件等)的存储,因此在这种使用场景下每天新发送的消息将占用210GB左右的磁盘空间。因为还要保存一周的数据,所以整体的磁盘容量规划是210 * 7 = 1.5TB。当然,这是无压缩的情况。如果在clients启用了消息压缩,我们可以预估一个平均的压缩比(比如0.5),那么整体的磁盘容量就是0.75TB。
总之对于磁盘容量的规划和以下多少个因素有关。
- 新增消息数。
- 消息留存时间。
- 平均消息大小。
- 副本数。
- 是否启用压缩。
5.1.4 内存规划
Kafka对于内存的使用可称作其设计亮点之一。虽然在前面我们强调了Kafka大量依靠文件系统和磁盘来保存消息,但其实它还会对消息进行缓存,而这个消息缓存的地方就是内存,具体来说是操作系统的页缓存(page cache)。
Kafka虽然会持久化每条消息,但其实这个工作都是底层的文件系统来完成的,Kafka仅仅将消息写入page cache而已,之后将消息“冲刷”到磁盘的任务完全交由操作系统来完成。另外consumer在读取消息时也会首先尝试从该区域中查找,如果直接命中则完全不用执行耗时的物理I/O操作,从而提升了consumer的整体性能。不论是缓冲已发送消息还是待读取消息,操作系统都要先开辟一块内存区域用于存放接收的Kafka消息,因此这块内存区域大小的设置对于Kafka的性能就显得尤为关键了。
有些令人惊讶的是,Kafka对于Java堆内存的使用反而不是很多,因为Kafka中的消息通常都属于“朝生夕灭”的对象实例,可以很快地垃圾回收(GC)。一般情况下,broker所需的堆内存都不会超过6GB。所以对于一台16GB内存的机器而言,文件系统page cache的大小甚至可以达到10~14GB!
除以上这些考量之外,用户还需要把page cache大小与实际线上环境中设置的日志段大小相比较。假设单个日志段文件大小设置为10GB,那么你至少应该给予page cache 10GB以上的内存空间。这样,待消费的消息有很大概率会保存在页缓存中,故consumer能够直接命中页缓存而无须执行缓慢的磁盘I/O读操作。
总之对内存规划的建议如下。
- 尽量分配更多的内存给操作系统的page cache。
- 不要为broker设置过大的堆内存,最好不超过6GB。
- page cache大小至少要大于一个日志段的大小。
5.1.5 CPU规划
比起磁盘和内存,CPU于Kafka而言并没有那么重要——严格来说,Kafka不属于计算密集型(CPU-bound)的系统,因此对于CPU需要记住一点就可以了:追求多核而非高时钟频率。简单来说,Kafka的机器有16个CPU核这件事情比该机器CPU时钟高达4GHz更加重要,因为Kafka可能无法充分利用这4GHz的频率,但几乎肯定会用满16个CPU核。Kafka broker通常会创建几十个后台线程,再加上多个垃圾回收线程,多核系统显然是最佳的配置选择。
当然,凡事皆有例外。若clients端启用了消息压缩,那么除了要为clients机器分配足够的CPU资源外,broker端也有可能需要大量的CPU资源——尽管Kafka 0.10.0.0改进了在broker端的消息处理,免除了解压缩消息的负担以节省磁盘占用和网络带宽,但并非所有情况下都可以避免这种解压缩(比如clients端和broker端配置的消息版本号不匹配)。若出现这种情况,用户就需要为broker端的机器也配置充裕的CPU资源。
基于以上的判断依据,我们对CPU资源规划的建议如下。
- 使用多核系统,CPU核数最好大于8。
- 如果使用Kafka 0.10.0.0之前的版本或clients端与broker端消息版本不一致(若无显式配置,这种情况多半由clients和broker版本不一致造成),则考虑多配置一些资源以防止消息解压缩操作消耗过多CPU。
5.1.6 带宽规划
对于Kafka这种在网络间传输大量数据的分布式数据管道而言,带宽资源至关重要,并且特别容易成为系统的瓶颈,因此一个快速且稳定的网络是Kafka集群搭建的前提条件。低延时的网络以及高带宽有助于实现Kafka集群的高吞吐量以及用户请求处理低延时。
当前主流的网络环境皆使用以太网,带宽主要也有两种:1Gb/s和10Gb/s,即平时所说的千兆位网络和万兆位网络。无论是哪种带宽,对于大多数的Kafka集群来说都足矣了。
关于带宽资源方面的规划,用户还需要注意的是尽量避免使用跨机房的网络环境,特别是那些跨城市甚至是跨大洲的网络。因为这些网络条件下请求的延时将会非常高,不管是broker端还是clients端都需要额外做特定的配置才能适应。
综合上述内容,我们对带宽资源规划的建议如下。
- 尽量使用高速网络。
- 根据自身网络条件和带宽来评估Kafka集群机器数量。
- 避免使用跨机房网络。
5.1.7 典型线上环境配置
下面给出一份典型的线上环境配置,用户可以参考这份配置以及结合自己的实际情况进行二次调整。
- CPU 24核。
- 内存 32GB。
- 磁盘 1TB 7200转SAS盘两块。
- 带宽1Gb/s。
- ulimit -n 1000000。
- Socket Buffer 至少64KB
5.2 参数设置
接下来,需要讨论Kafka集群涉及的各方面参数,主要包括以下几种参数。
- broker端参数。
- topic级别参数。
- GC配置参数。
- JVM参数。
- OS参数。
5.2.1 broker端参数
Kafka broker端提供了很多参数用于调优系统的各个方面,有一些参数是所有Kafka环境都需要考虑和配置的,不论是单机环境还是分布式环境。这些参数都是Kafka broker的基础配置,一定要明确它们的含义。
broker端参数需要在Kafka目录下的config/server.properties文件中进行设置。当前对于绝大多数的broker端参数而言,Kafka尚不支持动态修改——这就是说,如果要新增、修改、抑或是删除某些broker参数的话,需要重启对应的broker服务器。下面就让我们来看看主要的参数配置。
- broker.id——Kafka使用唯一的一个整数来标识每个broker,这就是broker.id。该参数默认是-1。如果不指定,Kafka会自动生成一个唯一值。总之,不管用户指定什么都必须保证该值在Kafka集群中是唯一的,不能与其他broker冲突。在实际使用中,推荐使用从0开始的数字序列,如0、1、2......
- log.dirs——非常重要的参数!该参数指定了Kafka持久化消息的目录。若待保存的消息数量非常多,那么最好确保该文件夹下有充足的磁盘空间。该参数可以设置多个目录,以逗号分隔,比如/home/kafka1,home/kafka2。在实际使用过程中,指定多个目录的做法通常是被推荐的,因为这样Kafka可以把负载均匀地分配到多个目录下。值得一提的是,若不设置该参数,Kafka默认使用/tmp/kafka-logs作为消息保存的目录。把消息保存在/tmp目录下,在实际的生产环境中是极其不可取的。
- zookeeper.connect——同样是非常重要的参数。此参数没有默认值,是必须要设置的。该参数可以是一个CSV(comma-separated values)列表,比如在前面的例子中设置的那样:zk1:2181,zk2:2181,zk3:2181。如果要使用一套ZooKeeper环境管理多套Kafka集群,那么设置该参数的时候就必须指定ZooKeeper的chroot,比如zk1:2181,zk2:2181,zk3:2181/kafka_cluster1。结尾的/kafka_cluster1就是chroot,它是可选的配置,如果不指定则默认使用ZooKeeper的根路径。在实际使用过程中,配置chroot可以起到很好的隔离效果。这样管理Kafka集群将变得更加容易。
- listeners——broker监听器的CSV列表,格式是[协议]://[主机名]:[端口]。该参数主要用于客户端连接broker使用,可以认为是broker端开放给clients的监听端口。如果不指定主机名,则表示绑定默认网卡;如果主机名是0.0.0.0,则表示绑定所有网卡。Kafka当前支持的协议类型包括PLAINTEXT、SSL以及SASL_SSL等。对于新版本的Kafka,推荐只设置listeners一个参数就够了,对于已经过时的两个参数host.name核port,就不用再配置了。对于未启用安全的Kafka集群,使用PLAINEXT协议足以。如果启用了安全认证,可以考虑使用SSL或SASL_SSL协议。
- advertised.listeners——核listeners类似,该参数也是用于发布给clients的监听器,不过该参数主要用于laaS环境,比如云上的机器通常都配有多块网卡(私网网卡和公网网卡)。对于这种机器,用户可以设置该参数绑定公网IP供外部clients使用,然后配置上面的listeners来绑定私网IP供broker间通信使用。当然不设置该参数也是可以的,只是云上的机器很容易出现clients无法获取数据的问题,原因就是listeners绑定的是默认网卡,而默认网卡通常都是绑定私网IP的。在实际使用场景中,对于配有多块网卡的机器而言,这个参数通常都是需要配置的。
- unclean.leader.election.enable——是否开启unclean leader选举。何为unclean leader选举?ISR中的所有副本都有资格随时成为新的leader,但若ISR变空而此时leader又宕机了,Kafka应该如何选举新的leader呢?为了不影响Kafka服务,该参数默认值是false,即表明如果发生这种情况,Kafka不允许从剩下存活的非ISR副本中选择一个当leader。因为如果允许,这样做固然可以让Kafka继续提供服务给clients,但会造成消息数据丢失,而在一般的用户使用场景中,数据不丢失是基本的业务需求,因此设置此参数为false显得很有必要。事实上,Kafka社区在1.0.0版本才正式将该参数默认值调整为false,这表明社区在高可用性与数据完整性之间选择了后者。
- delete.topic.enable——是否允许Kafka删除topic。默认情况下,Kafka集群允许用户删除topic及其数据。这样当用户发起删除topic操作时,broker端会执行topic删除逻辑。在实际生产环境中我们发现允许Kafka删除topic其实是一个很方便的功能,再加上自Kafka0.9.0.0新增的ACL权限特性,以往对于误操作和恶意操作的担心完全消失了,因此设置该参数为true是推荐的做法。
- log.retention.(hours|minutes|ms)——这组参数控制了消息数据的留存时间,它们是“三兄弟”。如果同时设置,优化选取ms的设置,minutes次之,hours最后。有了这3个参数,用户可以很方便地在3个时间纬度上设置日志的留存时间。默认的留存时间是7天,即Kafka只会保存最近7天的数据,并自动删除7天前的数据。当前较新版本的Kafka会根据消息的时间戳信息进行留存与否的判断。对于没有时间戳的老版本消息格式,Kafka会根据日志文件的最近修改时间(last modified time)进行判断。可以这样说,这组参数定义的是时间纬度上的留存策略。实际线上环境中,需要根据用户的业务需求进行设置。保存消息很长时间的业务通常都需要设置一个较大的值。
- log.retention.bytes——如果说上面那组参数定义了时间纬度上的留存策略,那么这个参数便定义了空间纬度上的留存策略,即它控制着Kafka集群需要为每个消息日志保存多大的数据。对于大小超过该参数分区日志而言,Kafka会自动清理该分区的过期日志段文件。该参数默认值是-1,表示Kafka永远不会根据消息日志文件总大小来删除日志。和上面的参数一样,生产环境中需要根据实际业务场景设置该参数的值。
- min.insync.replicas——该参数其实是与producer端的acks参数配合使用的。acks=-1表示producer端寻求最高等级的持久化保证,而min.insync.replicas也只有在acks=-1时才有意义。它指定了broker端必须成功响应clients消息发送的最少副本数。假如broker端无法满足该条件,则clients的消息发送并不会被视为成功。它与acks配合使用可以令Kafka集群达成最高等级的消息持久化。在实际使用中如果用户非常在意被发送的消息是否真的成功写入了所有副本,那么推荐将参数设置为副本数-1。举一个例子,假设某个topic的每个分区的副本数是3,那么推荐设置该参数为2,这样我们就能够容忍一台broker宕机而不影响服务;若设置参数为3,那么只要任何一台broker宕机,整个Kafka集群将无法继续提供服务。因此用户需要在高可用和数据一致性之间取得平衡。
- num.network.threads——一个非常重要的参数。它控制了一个broker在后台用于处理网络请求的线程数,默认是3。通常情况下,broker启动时会创建多个线程处理来自其他broker和clients发送过来的各种请求。注意,这里的“处理”其实只是负责转发请求,它会将接收到的请求转发到后面的处理线程中。在真实的环境中,用户需要不断地监控NetworkProcessorAvgIdlePercent JMX指标。如果该指标持续低于0.3,建议适当该参数的值。
- num.io.threads——这个参数就是控制broker端实际处理网络请求的线程数,默认值是8,即Kafka broker默认创建8个线程以轮询方式不停地监听转发过来的网络请求并进行实时处理。Kafka同样也为请求处理提供了一个JMX监控指标RequestHandlerAvgIdlePercent。如果发现该指标持续低于0.3,则可以考虑适当增加该参数的值。
- message.max.bytes——Kafka broker能够接收的最大消息大小,默认是977KB,还不到1MB,可见是非常小的。在实际使用场景中,突破1MB大小的消息十分常见,因此用户有必要综合考虑Kafka集群可能处理的最大消息尺寸并设置该参数值。
5.2.2 topic级别参数
除broker端参数之外,Kafka还提供了一些topic级别的参数供用户使用。所谓的topic级别,是指broker端全局参数。每个不同的topic都可以设置自己的参数值。举一个例子来说,上面提到的日志留存时间。显然,在实际使用中,在全局设置一个通用的留存时间并不方便,因为每个业务的topic可能有不同的留存策略。如果只能设置全局参数,那么势必要取所有业务留存时间的最大值作为全局参数值,这样必然会造成空间的浪费。因此Kafka提供了很多topic级别的参数,常见的包括如下几个。
- delete.retention.ms——每个topic可以设置自己的日志留存时间以覆盖全局默认值。
- max.message.bytes——覆盖全局的message.max.bytes,即为每个topic指定不同的最大消息尺寸。
- retention.bytes——覆盖全局的log.retention.bytes,每个topic设置不同的日志留存尺寸。
5.2.3 GC参数
Kafka broker端代码虽然是用Scala语言编写的,但终归要编译为.class文件在JVM上运行。既然是JVM上面的应用,垃圾回收(garbage collection, GC)参数的设置就显得非常重要。
推荐使用Java8版本,并推荐使用G1垃圾收集器。在没有任何调优的情况下,G1收集器本身会比CMS表现出更好的性能,主要体现在Full GC的次数更少、需要微调的参数更少等方面。因此推荐用户始终使用G1收集器,不论是在broker端还是在clients端。
除此之外,我们还需要打开GC日志的监控,并实时确保不会出现“G1HR #StartFullGC”。至于G1的其他参数,可以根据实际使用情况酌情考虑做微小调整。
5.2.4 JVM参数
之前说过,Kafka推荐用户使用最新版本的JDK——当前最新的Oracle JDK版本是1.8.0_162。另外鉴于Kafka broker主要使用的堆外内存,即大量使用操作系统的页缓存,因此其实并不需要为JVM分配太多的内存。在实际使用中,通常为broker设置不超过6GB的堆空间。以下就是一份典型的生产环境中的JVM参数列表:
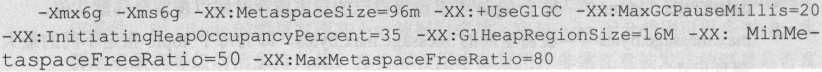
5.2.5 OS参数
Kafka支持很多平台,但到目前为止被广泛使用并已被证明表现良好的平台,依然是Linux平台。目前Kafka社区在Windows平台上已经发现了一些特有的问题,而且在Windows平台上的工具支持也不像Linux上面那样丰富,因此推荐应该将生产环境部署在Linux平台上。
通常情况下,Kafka并不需要太多的OS级别的参数调优,但依然有一些OS参数是必须要调整的。
- 文件描述符限制:Kafka会频繁地创建并修改文件系统中的文件,这包括消息的日志文件、索引文件及各种元数据管理文件等。因此如果一个broker上面有很多topic的分区,那么这个broker势必就需要打开很多个文件——大致数量约等于分区数*(分区总大小/日志段大小)* 3。举一个例子,假设broker上保存了50个分区,每个分区平均尺寸是10GB,每个日志段大小是1GB,那么这个broker需要维护1500个左右的文件描述符。因此在实际使用场景中最好首先增大进程能够打开的最大文件描述符上限,比如设置一个很大的值,如100000。具体设置方法为ulimit -n 100000。
- Socket缓冲区大小:这里指的是OS级别的Socket缓冲区大小,而非Kafka自己提供的Socket缓冲区参数。事实上,Kafka自己的参数将其设置为64KB,这对于普通的内网环境而言通常是足够的,因为内网环境下往返时间(round-trip time,RTT)一般都很低,不会产生过多的数据堆积在Socket缓冲区中,但对于那些跨地区的数据传输而言,仅仅增加Kafka参数就不够了,因为前者也受限于OS级别的设置。因此如果是做远距离的数据传输,那么建议将OS级别的Socket缓冲区调大,比如增加到128KB,甚至更大。
- 最好使用Ext4或XFS文件系统:其实Kafka操作的都是普通文件,并没有依赖于特定的文件系统,但依然推荐使用Ext4或XFS文件系统,特别是XFS通常都有着更好的性能。这种性能的提升主要影响的是Kafka的写入性能。根据官网的测试报告,使用XFS的写入时间大约是160毫秒,而使用Ext4大约是250毫秒。因此生产环境中最好使用XFS文件系统。
- 关闭swap:其实这是很多使用磁盘的应用程序的常规调优手段,具体命令为sysctl wm.swappiness=<一个较小的数>,即大幅度降低对swap空间的使用,以免极大地拉低性能。
- 设置更长的flush时间:我们知道Kafka依赖OS缓存的“刷盘”功能实现消息真正写入物理磁盘,默认的刷盘间隔是5秒。通常情况,这个间隔太短了。适当增加该值可以在很大程度上提升OS物理写入操作的性能。LinkedIn公司自己就将该值设置为2纷争以增加整体的物理写入吞吐量。
6. 调优Kafka集群
6.1 调优目标
本章会从4个方面来考量调优目标:吞吐量、延时、持久性和可用性,如图9.2所示。
在性能调优时,吞吐量和延时是相互制约的。假设Kafka producer每发送一条消息需要花费2毫秒(即延时是2毫秒),那么显然producer的吞吐量就应该是500条/秒,因为1秒可以发送1 / 0.002 = 500条消息。因此,吞吐量和延时的关系似乎可以使用公式来表示:TPS = 1000 / Latency(毫秒)。
其实,两者的关系远非上面公式表示的这么简单。我们依然以Kafka producer来举例,假设它仍然以2毫秒的延时来发送消息。如果每次只发送一条消息,那么TPS自然就是500条/秒。但如果producer不是每次发送一条消息,而是在发送前等待一段时间后统一发送一批消息。假设producer每次发送前会等待8毫秒,而8毫秒之后producer缓存了1000条消息,那此时总延时就累加到10毫秒(2+8),这时TPS等于1000 / 0.01 = 100000条/秒。由此可见,虽然延时增加了4倍,但TPS却增加了将近200倍。
上面的场景解释了目前为什么批次化(batching)以及微批次(micro-batching)流行的原因。实际环境中用户几乎总是愿意用增加较小延时的代价去换取TPS的显著提升。值得一提的是,Kafka producer也采取了这样的理念,这里的8毫秒就是producer参数linger.ms所表达的含义。producer累积消息一般仅仅是将消息发送到内存中的缓冲区,而发送消息却需要涉及网络I/O传输。内存操作和I/O操作的时间量级是不同的,前者通常是几百纳级,而后者从毫秒到秒级别不等,故producer等待8毫秒积攒出的消息数远远多于同等时间内producer能够发送的消息数。
6.2 集群基础调优
配置合理的操作系统(OS)参数能够显著提升Kafka集群的性能、阻止错误条件的发生,而OS级错误几乎总是会降低系统性能,甚至影响其他非功能性需求指标。在Kafka中经常碰到的操作系统级别错误可能包括如下几种。
- connection refused。
- too many open files。
- address in use: connect。
通过恰当的OS调优我们就可能提前预防这些错误的发生,从而降低问题修复的成本。本节我们将从以下几个方面分别探讨OS级别的调优。
6.2.1 禁止atime更新
由于Kafka大量使用物理磁盘进行消息持久化,故文件系统的选择是重要的调优步骤。对于Linux系统上的任何文件系统,Kafka都推荐用户在挂载文件系统(mount)时设置noatime选项,即取消文件atime(最新访问时间)属性的更新——禁掉atime更新避免了inode访问时间的写入操作,因此极大地减少了文件系统写操作数,从而提升了集群性能。Kafka并没有使用atime,因此禁掉它是安全的操作。用户可以使用mount -o noatime命令进行设置。
值得一提的是,Kafka虽然没有使用atime,但却使用了mtime,即修改时间用于日志切分等操作。当然随着时间戳属性在0.10.0.0版本的引入,mtime的使用场景也大大地减少了。
6.2.3 文件系统选择
Linux平台当前有很多文件系统,最常见的当属EXT4和XFS了。EXT4是EXT系列的最新一版,由EXT3演变提升而来。EXT4已成为目前大部分Linux发行版的默认文件系统。鉴于EXT4是最标准的文件系统,故目前EXT4的适配性是最好的。绝大多数运行在Linux上的软件几乎都是基于EXT4构建和测试的,因此兼容性上EXT4要优于其他文件系统。
而作为高性能的64位日志文件系统(journaling file system),XFS表现出了高性能、高伸缩性,因此特别适用于生产服务器,特别是大文件(30+ GB)操作。很多存储类的应用都适合选择XFS作为底层文件系统。目前RHEL 7.0已然将XFS作为默认的文件系统。
至于采用哪种文件系统实际上并没有统一的规定。上面两种文件系统都能很好地与Kafka集群进行适配。只不过在使用时每种文件系统都有一些特定的配置。
对于使用EXT4的用户而言,Kafka建议设置以下选项。
- 设置data=writeback:默认是data=ordered,即所有数据在其元数据被提交到日志(journal)前,必须要依次保存到文件系统中;而data=writeback则不要求维持写操作顺序。数据可能会在元数据提交之后才被写入文件系统。据称这是一个提升吞吐量的好方法,同时还维持了内部文件系统的完整性。不过该选项的不足在于,文件系统从崩溃恢复后过期数据可能出现在文件中。不过对不执行覆盖操作且默认提供最少一次处理语义的Kafka而言,这是可以忍受的。用户需要修改/etc/fstab和使用tune2fs命令来设置该选项。
- 禁掉记日志操作:日志化(journaling)是一个权衡(trade-off),它能极大地降低系统从崩溃中恢复的速度,但同时也引入了锁竞争导致写操作性能下降。对那些不在乎启动速度但却想要降级写操作延时的用户而言,禁止日志化是一个不错的选择。用户可执行tune2fs -O has_journal <device_name>来禁止journaling。
- commit=N_secs:该选项设置每N秒同步一次数据和元数据,默认是5秒。如果该值设置得比较小,则可减少崩溃发生时带来的数据丢失;但若设置较大,则会提升整体吞吐量以及降低延时。鉴于Kafka已经在软件层面提供了冗余机制,故在实际生产环境中推荐用户设置一个较大的值,比如1~2分钟。
- nobh:只有当data=writeback时该值才生效,它将阻止缓存头部与数据页文件之间的关联,从而进一步提升吞吐量。设置方法为修改/etc/fstab中的mount属性,比如noatime,data=writeback,nobh,errors=remount-ro。
对于XFS用户而言,推荐设置如下参数。
- largeio:该参数将影响stat调用返回的I/O大小。对于大数据量的磁盘写入操作而言,它能够提升一定的性能。largeio是标准的mount属性,故可使用与nobh相同的方式设置。
- nobarrier:禁止使用数据块层的写屏障(write barrier)。大多数存储设备在底层都提供了基于电池的写缓存,故设置nobarrier可以禁掉阶段性的“写冲刷”操作,从而提高写性能。不过自RHEL6开始,nobarrier已不被推荐,因为write barrier对系统的性能影响几乎可以忽略不计(大概3%),而启用write barrier带来的收益要大于其负面影响。如果是RHEL5的用户,则可以考虑设置此mount选项。
6.2.4 设置swapiness
一般Linux发行版会将该值默认设置为60。很多教程和有经验的人都建议将该值设置为0,即完全禁掉swap以提升内存使用率。
虽然swap开启时的确会拖慢机器的速度,但若Kafka“吃掉”了所有的物理内存,用户还可以通过swap来定位应用并及时处理。假设完全禁掉了swap,当系统耗尽所有内存(out of memory,OOM)后,Linux的OOM killer将会开启并根据一定法则选取一个进程杀掉(kill),这个过程对用户来说是不可见的,因此用户完全无法进行干预(比如在杀掉应用前保存状态等)。换句话说,一旦用户关闭了swap,就意味着当OOM出现时有可能丢失一些进程的数据。因此我们禁掉swap的前提就是要确保你的机器永远不会出现OOM,这对于生产环境上的Kafka集群而言,通常都是不能保证的。
建议将swap限定在一个非常小的值,比如1~10之间。这样既预留了大部分的物理内存,同时也能保证swap机制可以帮助用户及时发现并处理OOM。
临时修改swapiness可以使用sudo sysctl vm.swappiness=N来完成;若要永久生效,用户需要修改/etc/sysctl.conf文件增加vm.swappiness=N,然后重启机器。
6.2.5 JVM设置
推荐用户使用Java 8。
由于Kakfa并未大量使用堆上内存(on-the-heap memory)而是使用堆外内存(off-the-heap memory),故不需要为Kafka设定太大的堆空间。生产环境中6GB通常是足够了的,要知道以LinkedIn公司1500+台的Kafka集群规模来说,其JVM设置中也就是6GB的堆大小。另外,由于是Java 8,因此推荐使用G1垃圾收集器。下面给出一份典型的调优后JVM配置清单:

对于使用Java 7的用户,可以参考下面的清单:
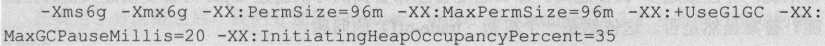
6.2.6 其他调优
使用Kafka的用户有时候会碰到“too many files open”的错误,这就需要为broker所在机器调优最大文件部署符上限。调优可参考这样的公式:broker上可能的最大分区数 * (每个分区平均数据量 / 平均的日志段大小 + 3)。这里的3是索引文件的个数。假设某个broker上未来要放置的最大分区数是20,平均每个分区总的数据量是100GB(不考虑follower副本),每个日志段大小是1GB,那么这台broker所在机器的最大文件部署符大小就大概是20 * (100GB / 1GB + 3),即2060。当然考虑到broker还会打开多个底层的Socket资源,实际一般将该值设置得很大,比如100000。
在实际线上Linux环境中,如果单台broker上topic数过多,用户可能碰到java.lang.OutOfMemoryError:Map failed的严重错误。这是因为大量创建topic将极大地消耗操作系统内存,用于内存映射操作。在这种情况下,用户需要调整vm.max_map_count参数。具体方法可以使用命令/sbin/sysctl -w vm.max_map_count=N来设置。该参数默认值是65536,可以考虑为线上环境设置更大的值,如262144甚至更大。
另外如果broker所在机器上有多块物理磁盘,那么通常推荐配置Kafka全部使用这些磁盘,即设置broker端参数log.dirs指定所有磁盘上的不同路径。这样Kafka可以同时读/写多块磁盘上的数据,从而提升系统吞吐量。需要注意的是,当前Kafka根据每个日志路径上分区数而非磁盘容量来做负载均衡,故在实际生产环境中容易出现磁盘A上有大量剩余空间但Kafka却将新增的分区日志放置到磁盘B的情形。用户需要实时监控各个路径上的分区数,尽量保证不要出现过度倾斜。一旦发生上述情况,用户可以执行bin/kafka-reassign-partitions.sh脚本,通过手动的分区迁移把占用空间多的分区移动到其他broker上来缓解这种不平衡性。
6.3 调优吞吐量
若要调优TPS,producer、broker和consumer都需要进行调整,以便让它们在相同的时间内传输更多的数据。
Kafka基本的并行单元就是分区。producer在设计时就被要求能够同时向多个分区发送消息,这些消息也要能够被写入到多个broker中供多个consumer同时消息。因此通常来说,分区数越多TPS越高,然而这并不意味着每次创建topic时要创建大量的分区,这是一个权衡(trade-off)的问题。
过多的分区可能有哪些弊端呢?首先,server/clients端将占用更多的内存。producer默认使用缓冲区为每个分区缓存消息,一旦满足条件producer便会批量发出缓存的消息。看上去这是一个提升性能的设计,不过由于该参数是分区级别的,因此如果分区很多,这部分缓存的内存占用也会变大;而在broker端,每个broker内部都维护了很多分区级别的元数据,比如controller、副本管理器、分区管理器等。显然,分区数越多,缓存成本越大。
虽然没法给出统一的分区数,但用户基本上可以遵循下面的步骤来尝试确定分区数。
- 创建单分区的topic,然后在实际生产机器上分别测试producer和consumer的TPS,分别为Tp和Tc。
- 假设目标TPS是Tt,那么分区数大致可以确定为Tt / max(Tp, Tc)。
Kafka提供了专门的脚本kafka-producer-perf-test.sh和kafka-consumer-perf-test.sh用于计算Tp和Tc。值得说明的是,测试producer的TPS通常是很容易的,毕竟逻辑非常简单,直接发送消息给Kafka broker即可;但测试consumer就与应用关系很大了,特别是与应用处理消息的逻辑有关。测试consumer时尽量使用真实的消息处理逻辑,这样测量的结果才能准确地反映线上环境。
在确定了分区数之后,我们分别从producer、broker和consumer这3个方面来讨论如何调优TPS。
如前所述,producer是批量发送消息的,它会将消息缓存起来后在一个发送请求中统一发送它们。若要优化TPS,那么最重要的就是调优批量发送的性能参数:批次大小(batch size)和批次发送间隔,即Java版本producer参数batch.size和linger.ms。通常情况下,增加这两个参数的值都会提升producer端的TPS。更大的batch size可以令更多的消息封装进同一个请求,故发送给broker端的总请求数会减少。此举既减少了producer的负载,也降低了broker端的CPU请求处理开销;而更大的linger.ms使producer等待更长的时间才发送消息,这样就能够缓存更多的消息填满batch,从而提升了整体的TPS。当然这样做的弊端在于消息的延时增加了,毕竟消息不是即时发送了。
就像前面说的,分区数的增加总要有个度,当增加到某个数值后由于锁竞争和内存占用过多等因素就会出现TPS的下降。在实际环境中,用户可以以2的倍数来逐步增加分区数进行测试,直至出现性能拐点。
除了上面这两个参数,producer端的另一个参数compression.type也是调优TPS的重要手段之一。对消息进行压缩可以极大地减少网络传输量,降低网络I/O开销从而提升TPS。由于压缩是针对batch做的,因此batch的效率也直接影响压缩率。这通常意味着batch中缓存的消息越多,压缩率越好。当前Kafka支持GZIP、Snappy和LZ4,但由于目前一些固有配置等原因,Kafka + LZ4组合的性能是最好的,因此推荐在那些CPU资源充足的环境中启用producer端压缩,即设置compression.type=lz4。
当producer发送消息给broker时,消息被发送到对应分区leader副本所在的broker机器上。默认情况下,producer会等待leader broker返回发送结果,这时才能知晓这条消息是否发送成功,consumer端也只能消费那些已成功发送的消息。显然等待leader返回这件事情也会影响producer端TPS:leader broker返回的速度越快,producer就能更快地发送下一条消息,因此TPS也就越高。producer端参数acks控制了这种行为,默认值等于1表示leader broker把消息写入底层文件系统即返回,无须等待follower副本的应答。用户也可以将acks设置成0,则表示producer端压根不需要broker端的响应即可开启下一条消息的发送。这种情况会提升producer的TPS,当然是以牺牲消息持久化为代价的。
对于Java版本producer而言,它需要创建一定大小的缓冲区来缓存消息,为producer端参数buffer.memory的值,该参数默认是32MB,通常来说用户是不需要调整的,但若在实际应用中发现producer在高负载情况下经常抛出TimeoutException,则可以考虑增加此参数的值。增加此值后,producer高负载的情况(即阻塞)将得到缓解,从而比之前缓存更多分区的数据,因而整体上提升了TPS。
对于Java版本consumer来说,用户可以调整leader副本所在broker每次返回的最小数据量来间接影响TPS——这就是consumer端参数fetch.min.bytes的作用。该参数控制了leader副本每次返回consumer的最小数据字节数。通过增加该参数值,Kafka会为每个FETCH请求的response填入更多的数据,从而减少了网络开销并提升了TPS。当然它和producer端的batch类似,在提升TPS的同时也会增加consumer的延时,这是因为该参数增加后,broker端必须花额外的时间积累更多的数据才发送response。
另外,如果机器和资源充足,最好使用多个consumer实例共同消费多分区数据。令这些实例共享相同的group id,构成consumer group并行化消费过程,能够显著地提升consumer端TPS。在实际环境中,笔者推荐用户最好启动与待消费分区数相同的实例数,以保证每个实例都能分配一个具体的分区进行消费。
对于broker,笔者推荐用户增加参数num.replica.fetches的值。该值控制了broker端follower副本从leader副本处获取消息的最大线程数。默认值1表明follower副本只使用一个线程去实时拉取leader处的最新消息。对于设置了acks=all的producer而言,主要的延时可能都耽误在follower与leader同步的过程,故增加该值通常能够缩短同步的时间间隔,从而间接地提升producer端的TPS。
总结一下调优TPS的一些参数清单和要点。
broker端
- 适当增加num.replica.fetchers,但不要超过CPU核数。
- 调优GC避免经常性的Full GC。
producer端
- 适当增加batch.size,比如100~512KB。
- 适当增加linger.ms,比如10~100毫秒。
- 设置compression.type=lz4。
- acks=0或1。
- retries=0。
- 若多线程共享producer或分区数很多,增加buffer.memory。
consumer端
- 采用多consumer实例。
- 增加fetch.min.bytes,比如100000。
6.4 调优延时
对于producer而言,延时主要是消息发送的延时,即producer发送PRODUCE请求到broker端返回请求response的时间间隔;对于consumer而言,延时衡量了consumer发送FETCH请求到broker端返回请求response的时间间隔。还有一种延时定义表示的是集群的端到端延时(end-to-end latency),即producer端发送消息到consumer端“看到”这条消息的时间间隔。
适度地增加分区数会提升TPS,但大量分区的存在对于延时却是损害。分区数越多,broker就需要越长的时间才能够实现follower与leader的同步。在同步完成之前,设置acks=all的producer不会认为该请求已完成,而consumer端更无法看到这些未提交成功的消息,因此这样既影响了producer端的延时也增加了consumer端的延时。若要调优延时,我们必须限制单台broker上的总分区数,缓解的办法有3种:①不要创建具有超多分区数的topic;②适度地增加集群中broker数分散分区数;③和调优TPS类似,增加num.replica.fetchers参数提升broker端的I/O并行度。
和调优TPS相反的是,调优延时要求producer端尽量不要缓存消息,而是尽快地将消息发送出去。这就意味着最好将linger.ms参数设置成0,不要让producer花费额外的时间去缓存待发送的消息。
类似地,不要设置压缩类型。压缩是用时间换空间的一种优化方式。为了减少网络I/O传输量,我们推荐启用消息压缩:但为了降低延时,我们推荐不要启用消息压缩。
producer端的acks参数也是优化延时的重要手段之一。leader broker越快地发送response,producer端就能越快地发送下一批消息。该参数的默认值1实际上已经是一个非常不错的设置,但如果用户应用对于延时有着比较高的要求,但却能够容忍偶发的消息发送丢失,则可以考虑将acks设置成0,在这种情况下producer压根不会理会broker端的response,而是持续不断地发送消息,从而达成最低的延时。
在consumer端,用户需要调整leader副本返回的最小数据量来间接地影响consumer延时,即fetch.min.bytes参数值。对于延时来说,默认值1已经是一个很不错的选择,这样能够使broker尽快地返回数据,不花费额外的时间积累消费数据。
下面总结一下调优延时的一些参数清单。
broker端
- 适度增加num.replica.fetchers。
- 避免创建过多topic分区。
producer端
- 设置linger.ms=0。
- 设置compression.type=none。
- 设置acks=1或0。
consumer端
- 设置fetch.min.bytes=1
6.5 调优持久性
持久性通常由冗余来实现,而Kafka实现冗余的手段就是备份机制(replication)—— 它保证每条Kafka消息最终会保存在多台broker上。这样即使单个broker崩溃,数据依然是可用的。
对于producer而言,高持久性与acks的设置息息相关。acks的设置对于调优TPS和延时都有一定的作用,但acks参数最核心的功能实际上是控制producer的持久性。若要达成最高的持久性必须设置acks=all(或acks=-1),即强制leader副本等待ISR中所有副本都响应了某条消息后发送response给producer。ISR副本全都响应消息写入意味着ISR中所有副本都已将消息写入底层日志,这样只要ISR中还有副本存活,这条消息就不会丢失。
另一个提升持久性的参数是producer端的retries。在producer发送失败后,producer视错误情况而有选择性地自动重试发送消息。生产环境中推荐将该值设置为一个较大的值。
producer重试,而待发送的消息可能已经发送成功,造成了同一条消息被写入了两次,即重复消息。自0.11.0.0版本开始,Kafka提供了幂等性producer,实现了精确一次的处理语义。幂等性producer保证同一条消息只会被broker写入一次,因此很好地解决了这个问题。启用幂等性producer的方法也十分简单,只需要设置producer端参数enable.idempotence=true。
下面总结一下调优持久性的参数清单和要点。
broker端
- 设置unclean.leader.election.enable=false。
- 设置auto.create.topics.enable=false。
- 设置replication.factor=3,min.insync.replicas=replication.factor-1。
- 设置default.replication.factor=3
- 设置broker.rack属性分散分区数据到不同机架。
- 设置log.flush.interval.message和log.flush.interval.ms为一个较小的值。
producer端
- 设置acks=all。
- 设置retries为一个较大的值,比如10~30。
- 设置max.in.flight.requests.per.connection=1。
- 设置enable.idempotence=true启用幂等性。
consumer端
- 设置auto.commit.enable=false。
- 消息消费成功后调用commitSync提交位移。
6.6 调优可用性
下面总结一下调优可用性的一些参数清单。
broker端
- 避免创建过多分区。
- 设置unclean.leader.election.enable=true。
- 设置min.insync.replicas=1。
- 设置num.recovery.threads.per.data.dir=broker端参数log.dirs中设置的目录数。
producer端
- 设置acks=1,若一定要设置为all,则遵循上面broker端的min.insync.replicas配置。
consumer端
- 设置session.timeout.ms为较低的值,比如10000。
- 设置max.poll.interval.ms为比消息平均处理时间稍大的值。
- 设置max.poll.records和max.partition.fetch.bytes减少consumer处理消息的总时长,避免频繁rebalance。
参考资料
参考《Apache Kafka实战》
以上是关于Kafka实战分析的主要内容,如果未能解决你的问题,请参考以下文章