链家数据爬取
Posted jzxs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了链家数据爬取相关的知识,希望对你有一定的参考价值。
爬取杭州在售二手房的数据
https://hz.lianjia.com/ershoufang/这是首页地址,我们可以看见有翻页栏,总共100页,每一页30条数据,
第二页地址https://hz.lianjia.com/ershoufang/pg2/,对比可以发现多了一个参数pg2,这样就可以找到规律,1-100页请求地址都可以找到
使用正则表达式提取每一页的数据
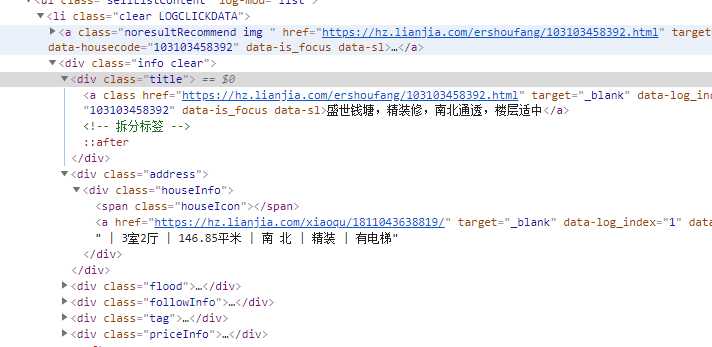
‘<li.*?LOGCLICKDATA.*?class="info clear".*?title.*?<a.*?>(.*?)</a>.*?houseInfo.*?region.*?>(.*?)</a>(.*?)</div>.*?positionIcon.*?</span>(.*?)<a.*?>(.*?)</a>.*?starIcon.*?</span>(.*?)</div>.*?class="totalPrice"><span>(.*?)</span>(.*?)</div>.*?unitPrice.*?<span>(.*?)</span>‘
import requests import re import json import time def get_one_page(url): headers={ ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/70.0.3538.110 Safari/537.36‘ } response=requests.get(url,headers=headers) if response.status_code==200: return response.text return None def parse_one_page(html): pattern=re.compile(‘<li.*?LOGCLICKDATA.*?class="info clear".*?title.*?<a.*?>(.*?)</a>.*?houseInfo.*?region.*?>(.*?)</a>(.*?)</div>.*?positionIcon.*?</span>(.*?)<a.*?>(.*?)</a>.*?starIcon.*?</span>(.*?)</div>.*?class="totalPrice"><span>(.*?)</span>(.*?)</div>.*?unitPrice.*?<span>(.*?)</span>‘) items=re.findall(pattern,html) for item in items: yield{ ‘title‘:item[0], ‘address‘:item[1], ‘houseIcon‘:item[2], ‘flood‘:item[3].strip()+item[4].strip(), ‘personStar‘:item[5], ‘price‘:item[6]+item[7] } def write_file(content): with open(‘result12.json‘,‘a‘,encoding=‘utf8‘)as f: print(type(json.dumps(content))) f.write(json.dumps(content,ensure_ascii=False)+‘ ‘) def main(offset): url=‘https://hz.lianjia.com/ershoufang/pg‘+str(offset) html=get_one_page(url) for item in parse_one_page(html): write_file(item) if __name__ == ‘__main__‘: for i in range(101): main(offset=i) time.sleep(1)
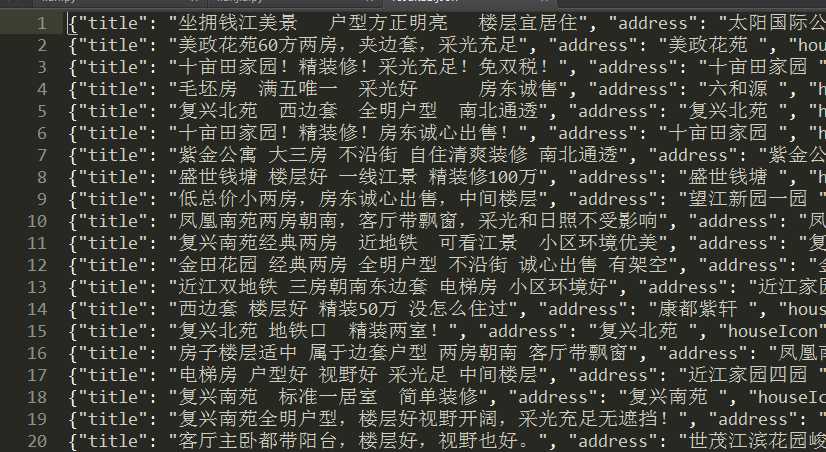
全部数据保存到json文件
以上是关于链家数据爬取的主要内容,如果未能解决你的问题,请参考以下文章