基于乐理模型的算法作曲研究
Posted sci-dev
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于乐理模型的算法作曲研究相关的知识,希望对你有一定的参考价值。
Abstraction
Musical composition is a sophisticated movement of thought that is unique for humans. More concretely, composition reflects the basic technology and theory of music, i.e. harmonics, polyphony, orchestration, structure and so on, which are utilized to express the spirit of originators. Currently algorithm composition has become a topic much worthy of discussion.
In this paper we attempt to shrink the research scope and construct a model of musical theories, discussing a practical way to make pop music automatically. For the research on algorithm composition, it‘s the first step to abstract the traits of composition procedures, and the following is to take into account the implement for computer based on structured algorithms. This imparity of the procedure enforces the algorithm to follow principle of abstraction.
There are mainly two chapters of this paper: primarily the theory foundation of automatic composition, secondarily details of computer implement. In conclusion, we have constructed a C++/YAML prototype program, including musical theorical model (MTM) and knowledge library system (KLS), then we have succeeded to design and evaluate the target algorithm.
Keywords: Algorithm Composition; Musical Theorical Model; Knowledge Library System.
摘要
作曲是人类的一种复杂的思维过程,具体来说作曲反应了创作者运用基本乐理、和声学、复调、配器法、曲式结构的技术理论体系来表达音乐思想的方法,而如何利用计算机模拟作曲过程,反映作曲的理论体系,是一个值得探讨的问题。
本文试图通过缩小研究范围,从流行音乐的角度出发建立乐理模型,提出实现流行音乐算法作曲的可行实现方法,同时提出了一种研究算法作曲的思路:首先对作曲过程进行抽象化分析,围绕过程抽象展开结构化程序的设计。本文主要从两个层面论述:其一,作曲的理论支撑;其二,结构化算法程序的设计。通过C++/YAML原型设计,最终实现了乐理模型和知识库系统的建立,完成了目标算法的设计、评估以及后续工作。
关键字:算法作曲;乐理模型;知识库系统
前言
当前算法作曲的研究主要集中于机器学习方向,其中基于离散时间马尔可夫链的算法作曲是经典算法之一。通过建立各音符的状态转移概率矩阵,马尔科夫链可以对每一步的旋律走向进行决策。除马尔可夫链外,外还存在基于遗传算法、细胞自动控制理论等的其它算法。
所有作曲算法都离不开基础乐理、和声学、复调、配器法、曲式结构等理论的约束,如果缺乏有效约束,单纯从概率等角度出发,则难以得出令人满意的结果。关于算法作曲的研究,大多离不开对音乐语法约束的探究。本文的主要工作是建立基础乐理的算法模型,同时提出激励层、变换层、记谱层的三层模型,利用乐理建模实现音型变换,并基于约束条件自动化地组织音型,最终得出连贯的音乐作品。
一、抽象模型分析
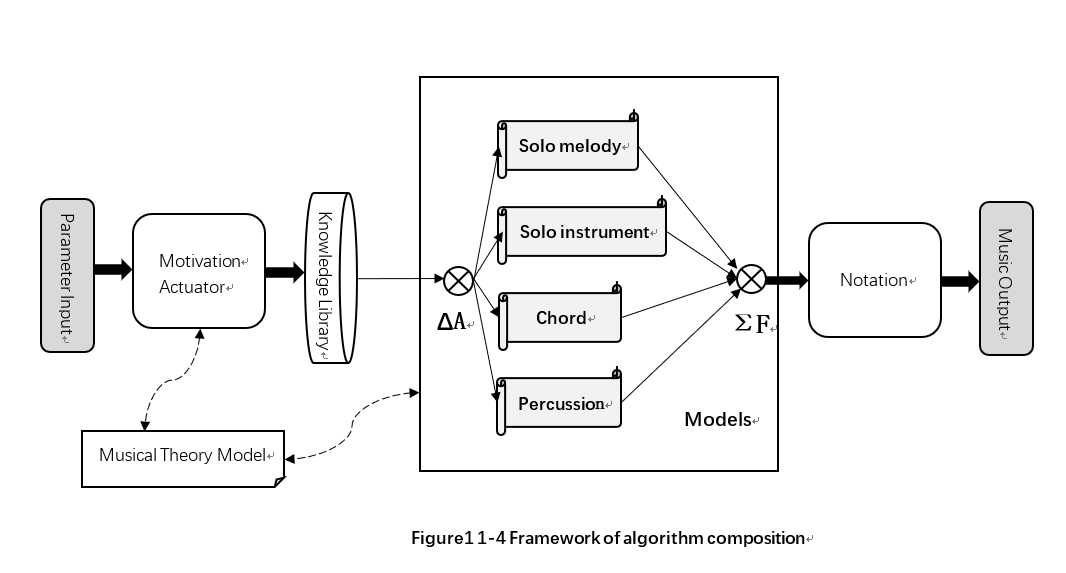
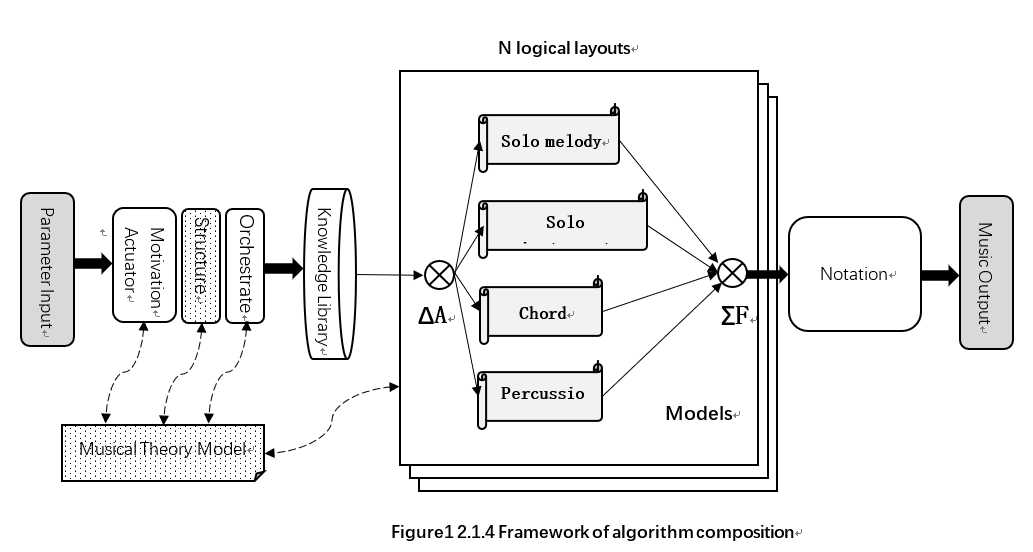
本算法是一个三层模型,即激励层、变换层和记谱层。第n层模型始终对n+1层模型起制约作用,第n层模型的输出作为第n+1层模型的输入的一个子集。除此之外还确定了乐理模型。三层模型对乐理模型存在依赖关系。其中,激励层主要包括一个动机激励器和知识库系统;变换层主要包括四个独立的变换模型;记谱层负责算法内部格式到外部格式的转换。
下面就每个层面分别进行讨论,并总结出算法的整体思路框架。
1、激励层(Actuator layout)
作曲家开始音乐作品的创作,必要条件是具有创作动机。如果没有动机,就不会有音乐作品的产生。从作曲家角度出发,创作动机的产生主要归因于两个层面:从空间角度讲,受到主观的思维活动和客观的环境两方面影响;从时间角度讲,作曲家的经验阅历等,也会对当前的作曲活动产生影响。
本节研究的核心问题是解决计算机如何表示创作动机,如何产生创作动机,进而为算法作曲提供总约束条件的问题。而最根本的问题是找出影响音乐风格的因素。由于作曲家主观思维的参杂,该方面是本算法研究中的难点之一。从构成音乐的要素上看,旋律、结构、配器等,对影响情绪表达起到了决定性作用。只有综合考虑和声、旋律、配器等方面才能相对准确地控制作品的情感。
1.1 调式、和弦走向对作曲风格的约束
调式由不同音高的音组成集合,这些音互相之间具有某种特定的音程关系,并在调式中担任不同的角色。调式是决定音乐风格最重要的因素之一。在不同的历史时期与不同的民族和地域,形成各种不同的调式,例如,中国民乐以五声音阶为主的五声调式或以五声音阶为基础的七声调式。各种调式因其音阶结构、调式音级间相互关系以及音律等方面的差异,而各具特色与表现力。调式和其他表现手法配合在一起,可赋予音乐以一定的表情素质与不同的风格。
而和弦走向反映了旋律总体的发展趋势,不同曲风的作品,和弦走向上会有所差别。
例如,Leading Bass走向:
C—G/B—Am—C/G—F—C/E—Dm—G—C。其柱式和弦音型如下图所示。

Leading Bass起源于Canon。在多数表现浪漫主义色彩的作品中有所体现。
又如:
Am—F—C—G。为尽可能确保变量唯一,这里仍采用柱式和弦音型,如下图所示。

与Leading Bass相比,可以发现总体风格的变化。
产生和弦色彩的主要因素在于和弦组成音之间的音程关系,而具有不同色彩和弦的相互融合,使得其具有某种情感倾向。算法作曲中利用和弦走向的这种特性,可以为旋律提供反向约束条件,缩小旋律可用的音符范围,为旋律生成提供参考依据。
然而,仅有旋律是远远不够的,节奏型对情绪表达同样起着至关重要的的作用。对于相同旋律,不同节奏能使其呈现出不同的表达效果。同样以上节Am-F-C-G和弦为例。下图为柱式和弦改编为半分解和弦后的音型。与原始柱式和弦相比较,采用新的节奏型增大了音乐织体。柱式音型比较单一,而新的音型更加活泼。

1.2 结构与配器与作品风格的关系
流行音乐的曲式结构由主歌(Verse),副歌(Chorus),过渡句(插句),桥段(Instrumental and Ending)(序唱,过门,间奏)等组成,不同形式下谱曲方法不同。结构的存在使流行音乐符合一套统一的“语法”,这一点为算法作曲提供了有价值的参考。例如主歌与副歌存在的对照性关系。主歌与副歌构往往具有相似性;而副歌在旋律和情绪上都超越主歌。又例如前奏尾奏与主体的呼应关系,使得作品结构完整,有始有终。在算法作曲时,应当充分考虑这种语法约束,不能任凭旋律发展,而全然不顾形式的要求。
下表总结了常见的流行音乐结构。
| 1 | Blank, Prelude, Verse, Chorus, Ending |
| 2 | Blank, Prelude, Verse, Chorus, interlude, Verse, Chorus, Ending |
| 3 | Blank, Prelude, Verse, Trans, Chorus, Interlude, Verse, Trans, Chorus, Ending |
| 4 | Blank, Prelude, Verse, Trans, Chorus, Interlude, Verse, Trans, Chorus, Interlude, Verse, Trans, Chorus, Ending |
配器对曲风的影响也是显著的。例如,流行音乐往往采用各类乐器逐步加入的方法,即前奏仅采用一种或几种乐器,而随着音乐发展加入乐器。这种手法使得音乐有曲直变化,更易于听众接受。其次,各种乐器在音乐中的核心功能是提供音色。由于听众的经验认知,部分音色本身就带有某种情绪倾向。算法作曲也应当考虑到配器原理和配器手法,同时还应符合潜在的语法。
1.4 激励层总体设计
结合调式、和弦走向、结构与配器等,创作动机的生成归结于如下输入输出模型:输入:反映作曲意图的参数;输出:作品的基本参数(调式,调性,节拍等)、结构、和弦走向、配器。下文统称该模型为动机激励器(Motivation Actuator)。该模型需要一定规模的数据库作为支撑,在这里引入知识库系统:动机激励器承担知识库系统中推理机构的一个组成成分,而一个数据库构成知识库系统的数据来源。由动机激励器和知识库模型构成的子系统,便是激励层。
2. 变换层(Transformation layout)
在完全基于已知经验的前提下,即仅考虑作曲家在已有经验和音乐体系下的创作过程,不考虑对新理论体系的探索过程,旋律创作可以概括为“变换”(Transformation),它主要存在于两个层面:
(1)、作曲家将已知音型变换为新的音型,并最终成为已知音型;
(2)、作曲家在创作动机的驱动下,将已知音型变换为新的音型,并最终成为作品的一部分。
作曲过程经过抽象后,可以描述为以变换为基础组织完整音乐作品的过程。上一节中,我们主要讨论了创作动机的相关问题。激励层生成的是音乐的框架信息,仅仅为作曲提供了约束条件。变换层讨论的问题正是如何对这个框架进行展开。由于激励层为接下来的作曲过程提供了约束条件,使得变换层处理的范围大幅缩小,变换层只需依据激励层的输出对知识库中的音型进行变换。
由于知识库中的音型具有独立的调性或节拍、和弦走向,因此变换层需要根据激励层输出的结果,对已有音型进行转调或伸缩变换、和弦转换等操作。此外,变换过程还必须充分考虑不同种类乐器的特性,做出必要的特定优化。例如主旋律和伴奏旋律具有显著差异性,而伴奏旋律中又包括器乐独奏和器乐合奏。即便对于同一种类型,乐器的适用音域,演奏方式等也存在差异。因此,应有针对地设计各类变换模型,利用调度器将变换的每个分步骤分配到合适的模型进行处理。最终通过综合器对所有输出结果进行汇总。采用调度-综合的方式,避免了碎片化,提高封装性,同时利于并行计算的实现。
在本算法中,划分了四个变换模型,即solo melody、solo instrumental、chord和percussion,负责根据输入分别对旋律独奏、器乐独奏、和弦型伴奏和打击乐的音符序列进行变换操作。这四个模型和调度器、综合器组成了变换层。
3. 记谱层(Notation layout)
一方面,算法内部持有独立的音符序列量化方法,另一方面,算法内部的音符序列需要转换到人类可读的乐谱中,这就需要选择适当的记谱格式。目前主流格式包括MusicXML,MIDI文件等,其中MusicXML广泛应用于各类记谱软件中,而MIDI文件则更为通用,几乎所有的编曲或音频工作站都支持MIDI文件格式,但MIDI文件是由头信息和大量MIDI事件组成,更侧重于对数字乐器的自动化控制,而非乐谱的表达。不论何种记谱格式,选择的主要标准为:是否具有准确表示音符序列的能力。
根据谱表文件的格式,将算法内的量化标准,映射到目标谱表文件的量化标准,并按照目标格式存储,是记谱层需要完成的工作。
4. 算法的整体框架
综合对激励层、变换层、记谱层的抽象,我们可以得出作曲算法的总体框架。其中ΔA表示对变换过程的调度,ΣF表示对输出音型的综合,实线表示数据流路径,虚线表示模块间的依赖关系。
二、作曲算法的程序设计
激励层-变换层-记谱层的三层模型为算法设计提供了整体思路,接下来重点讨论算法和程序的设计与实现,其中根据和声学、配器法和曲式结构的相关理论建立乐理模型是本算法的核心,其次还包括知识库系统的建立和记谱层的设计思路。
2.1 乐理模型的建立
为了便于进一步的建模,算法内部将音符表示为一个四维向量Vn=(p, v, s, e),该向量的四个维度分别对应音符的音调、力度、起音时间和关断时间。而算法在输出阶段需要将四维向量组成的序列映射到人类可读的乐谱中。
算法内部的量化过程需要遵循一定的标准,对于时间的量化,考虑到不同拍速(tempo)对音符时值的影响,只能以相对值的形式表示,具体方法是:采用固定的采样频率Fs对音符时值进行采样。
Fs = 1 / Tq
Tq为当前拍速下,每个参考音符持续时间。参考音符时值决定量化精度,参考音符时值与量化精度成反比。
将每个采样的时值除以Tq,便得到时间刻度相对值。
对于音调的量化,我们采用MIDI标准,利用连续的整数为每个8度音阶中的音符编码,并确定中央C(C4)编码为60。p值与音调呈正相关,p值差值的乐理含义为以音数为单位的音程差。力度采用128级分层,v = 0表示最弱,而v = 127表示最强。
2.1.1 调式建模
调式规定了各音之间的音程关系。调式系统中最重要的是自然大调和自然小调,自然大调的规则是:除了中音和下属音,下主音和主音这两对音之间的音程是小二度之外,其他相邻两音之间都是大二度 ,其音程总结来说便是“全全半全全全半”;而自然小调的音程关系则可以总结为“全半全全半全全“。
下表总结了两个八度内,自然大调与自然小调内每个音与主音的相对关系。
| 音阶 | C0 | D0 | E0 | F0 | G0 | A0 | B0 | C1 | D1 | E1 | F1 | G1 | A1 | B1 | |
| 自然大调 | 音数 | 0 | 2 | 4 | 5 | 7 | 9 | 11 | 12 | 14 | 16 | 17 | 19 | 21 | 23 |
| 自然小调 | 音数 | 0 | 2 | 3 | 5 | 7 | 8 | 10 | 12 | 14 | 15 | 17 | 19 | 20 | 22 |
根据变换层的需求,这里给出调式变换的实现思路。已知主音音高,则可以换算出调内音的音高。而已知任意音和主音,却不一定能换算出调内音。这是因为任意音不一定都在调内。经过实验,选取离源音高最近的调内音即可满足要求。考虑到调内音的偏移变换,在程序末尾添加循环偏移,保证变换后调内音位于两个八度之内。最终得出调内音后,根据偏移即可计算出绝对音高。算法程序如下。
1 int pitch_get_in_scale(int pitch, int diff_tone, int key, int scale) 2 { 3 const int *in_scale_list = scale_component_pitch[scale]; 4 int in_scale_count = SCALE_COMPONENT_PITCH_NUM; 5 6 int pitch_offset = util::floor_mod(pitch - key, 12); 7 int index; 8 for(index=0; index < in_scale_count; index++) 9 { 10 if( pitch_offset == in_scale_list[index] ) 11 break; 12 } 13 if( index == in_scale_count ) /* pitch in 12-tone is not in-scale, then utilize the nearest scale */ 14 { 15 index--; 16 for(int i=0; i < in_scale_count; i++) 17 if( pitch_offset < in_scale_list[i] ) 18 { 19 index = i; 20 break; 21 } 22 } 23 24 int shifted_index = index + diff_tone; 25 26 while( shifted_index > in_scale_count ) /* shift down if index is higher than current 2 oct */ 27 { 28 index -= in_scale_count / 2; 29 shifted_index -= in_scale_count / 2; 30 pitch_offset -= 12; 31 } 32 while( shifted_index < 0 ) /* shift up when index is lower than current 2 oct */ 33 { 34 index += in_scale_count / 2; 35 shifted_index += in_scale_count / 2; 36 pitch_offset += 12; 37 } 38 39 return pitch + (in_scale_list[shifted_index] - pitch_offset); 40 }
2.1.2 和声问题建模
和声学是一门研究和声的产生、构成原则,和弦的连接与相互关系,和声风格的形成、发展与演变的学科,而本算法仅涉及与和弦相关的内容。
为了便于研究,首先规定和弦的表示方法:和弦采用二维向量Vc=(r, s)表示,r为和弦根音编码,从0开始按照C调音阶(C、#C、D、#D、E、F、#F、G、#G、A、#A、B)的顺序编码;s为和弦记号,该编码主要规则如下:
| 0 | |
| m | 1 |
| m7 | 2 |
| 7 | 3 |
| M7 | 4 |
| aug | 5 |
| dim | 6 |
| dim7 | 7 |
| sus2 | 8 |
| sus4 | 9 |
| 7sus4 | 10 |
| 6sus4 | 11 |
| 6 | 12 |
| m6 | 13 |
| -5 | 14 |
| +5 | 15 |
| M7+5 | 16 |
| m-5 | 17 |
| 7-5 | 18 |
| 7+5 | 19 |
因此,Vc=(0, 0)表示C和弦,Vc=(0, 1)表示Cm和弦。
在接下来的算法中涉及取音阶内相对音高的运算。为了便于实现,本文采用基于floor除法的取余运算,因此需另外规定floor_mod函数的实现。
1 template <typename T> 2 static inline T floor_mod(T op1, T op2) 3 { 4 return op1 - (op2 * static_cast<T>(std::floor(float(op1)/float(op2)))); 5 }
此时实现和弦转换便非常容易,只需要转换和弦根音,并保持和弦标记即可。
1 /** 2 * @brief Shift a chord by root with offset. 3 */ 4 ChordPair chord_shift(const ChordPair &chord, int root_offset) 5 { 6 return ChordPair(util::floor_mod(chord.root + root_offset, 12), chord.sign); 7 }
和弦是由几个固定音程的音叠置组成的,为了表示这种关系,我们采用二维数组存储组成音之间的相对偏移音数。值得注意的是,存在一部分和弦有4个组成音,而其它和弦只有3个组成音的情况。由于和弦根音与比根音高八度的音呈完全协和音程关系,因此对于只有3个组成音的和弦而言,在第4个音位置添加八度音数。
1 #define CHORD_COMPONENT_PITCH_NUM 4 2 static const int chord_component_pitch[CHORD_SIGN_NUM][CHORD_COMPONENT_PITCH_NUM] = 3 { 4 {0, 4, 7, 12}, /**/ 5 {0, 3, 7, 12}, /* m */ 6 {0, 3, 7, 10}, /* m7 */ 7 {0, 4, 7, 10}, /* 7 */ 8 {0, 4, 7, 11}, /* M7 */ 9 {0, 4, 8, 12}, /* aug */ 10 {0, 3, 6, 12}, /* dim */ 11 {0, 3, 6, 9}, /* dim7 */ 12 {0, 2, 7, 12}, /* sus2 */ 13 {0, 5, 7, 12}, /* sus4 */ 14 {0, 5, 7, 10}, /* 7sus4 */ 15 {0, 5, 7, 9}, /* 6sus4 */ 16 {0, 4, 7, 9}, /* 6 */ 17 {0, 3, 7, 9}, /* m6 */ 18 {0, 4, 6, 12}, /* -5 */ 19 {0, 4, 8, 12}, /* +5 */ 20 {0, 4, 8, 11}, /* M7+5 */ 21 {0, 3, 6, 12}, /* m-5 */ 22 {0, 4, 6, 10}, /* 7-5 */ 23 {0, 4, 8, 10} /* 7+5 */ 24 };
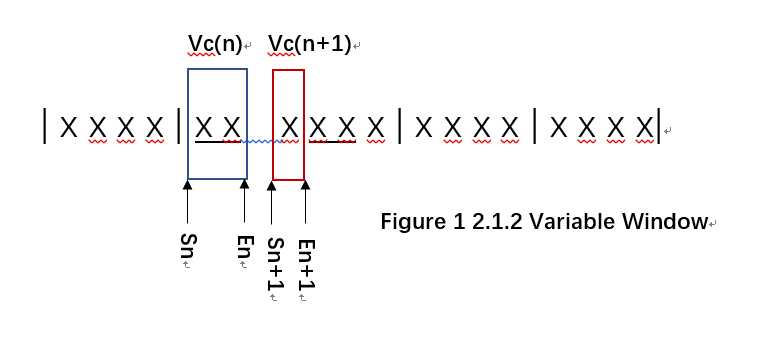
考虑变换层的需求,这里提出对音序进行和弦变换的思路。为了简化问题,引入滑动窗口的变换方法,即假设音序中每拍对应一种和弦,于是对音序的和弦变换可拆分为对每拍音符子序的变换,这使得每一步都只涉及一种和弦。
滑动窗口时确定当前窗口的起始位置和结束位置,每次仅转换完全被窗口包围的音符,转换完成后移动窗口至下一拍。滑动窗口的有效长度相当于一个1/4音符的长度,窗口的起止位置由如下通项决定(起止位置采用1/64量化),其中n>=1表示的窗口编号:
Sn = 16 * (n - 1), En = 16 * n.
对于每个窗口的和弦变换。首先应界定新音序的音区,否则可能出现音调过高或过低的情况,这里以目标和弦根音与源和弦根音的音程之差作为衡量依据,确定是否有必要对音序进行升调或降调。根据实验结果,判断阈值确定为五度时效果最佳。当目标和弦高出源和弦五度以上时,新音序在源音高基础上降低八度,反之,当目标和比源和弦低五度以上时,新音序应升高八度。
本文提出一种基于和弦根音音程相似度的和弦变换方法。和弦变换依赖两方面的输入,其一为原始和弦,其二为目标和弦。所有变换都必须在调式体系下进行。为了便于表达,首先定义音程差函数 f(p, r),p为音序中音符的音调,r为和弦根音的音调。为了保证转换前后音符与和弦根音音程差关系的相似性,再引入残差Q,其中n为音序中所有音符的个数,{Sn}为原始音符组成的集合,而{Sr}、{Dr}分别为原始和弦与目标和弦的根音组成的集合。算法的目标是,求出所有满足约束条件的Xi,使得Q取最小值。
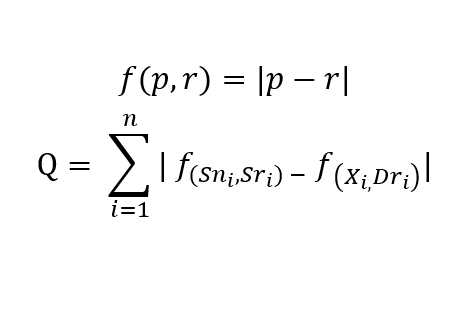
Xi的约束条件如下:设集合S为调内音阶中从目标和弦的根音开始组成的子音阶,则Xi∈S。该约束条件的目的是保证结果始终处在目标调式系统中,而不出现离调。
为了便于程序实现,在前序音区范围的界定下,所有和弦变换都只需在一个八度音阶下进行,具体方法为:求出目标和弦根音的调内音Dri,再对原始音序中的音符逐一处理,求出每个音符与原始和弦根音的音程差Sni,在高于Dri的调内音阶中进行遍历,找出使得Q最小的Xi。
如下为针对每个音符进行变换的算法实现,其中变量dst_scale保存目标调式的索引,而变量dst_chord_tone保存了目标和弦根音的调内音。经过循环比较后,变量note_chord保存最终结果,即调内目标和弦根音的音程差。该结果与目标和弦根音相加,便得到八度音阶内的相对音高,最终根据界定的音区,可换算出新音符的绝对音高。
int min_delta = 100; int min_delta_index = 0; for(int j=dst_chord_tone + 1; j < SCALE_COMPONENT_PITCH_NUM; j++) { int Td = scale_component_pitch[dst_scale][j] - scale_component_pitch[dst_scale][dst_chord_tone]; int delta = ABS(Td - Sd); if( ABS(delta) < min_delta ) { min_delta = delta; min_delta_index = j; } } note_chord = scale_component_pitch[dst_scale][min_delta_index] - scale_component_pitch[dst_scale][dst_chord_tone];
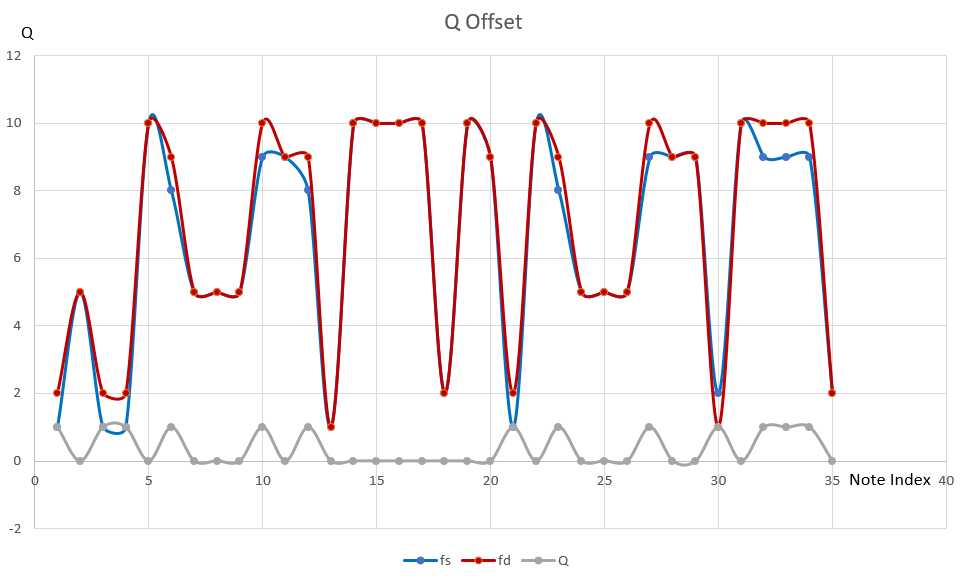
如图所示为一个测试音序样本,该样本为bB调,包含和弦走向#A, #A, F, F, Gm, Gm, F, F, #D, #D, Dm, Dm, Cm, Cm, F, F, #A, #A, F, F, Gm, Gm, F, F, #D, #D, Dm, Dm, Cm, Cm, F, F。采用该样本测试算法的初步效果。

设定目标调性为#C调,目标和弦为Fm, Fm, Fm, #C, #C, #C, Fm, Fm, Fm, #G, #G, #G, Fm, Fm, Fm, #C, #C, #C, #G, #G, #G, #C, #C, #C,目标节拍为3/4拍。经过和弦变换后得出的音序如图所示。由于原始节拍与目标节拍不同,因此在变换过程中对原始音序位置和时值进行了伸缩变换,原始音序长度大于和结果音序。

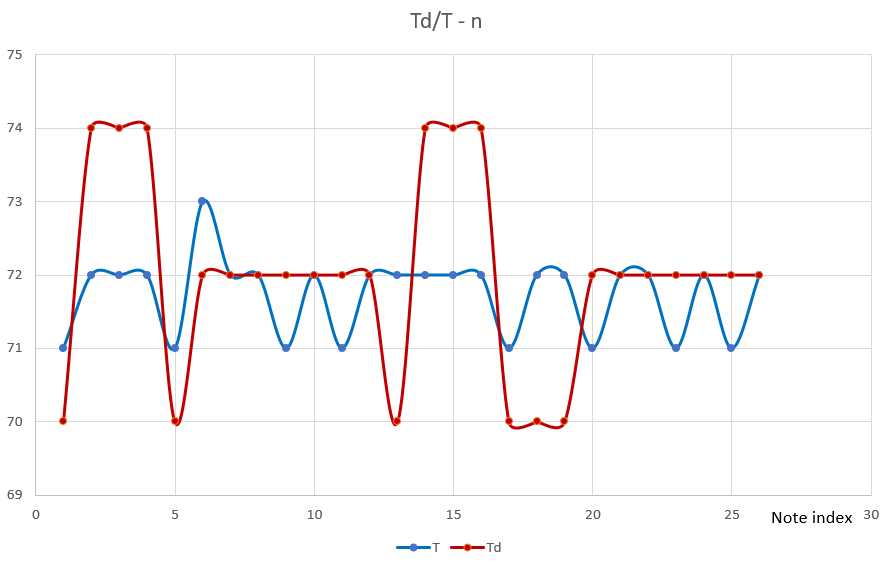
该测试用例直观地反映了和弦变换对音序的影响程度,与原始音序相比,变换后的音序在保持旋律的和谐性的基础下,呈现出截然不同的效果。而为了更加精确地对残差Q进行评估,我们将对上述音序变换过程中每个音符对应的原始音程差fs,目标音程差fd,以及残差Q绘制成平滑曲线,如下图所示。
2.1.3 配器问题建模
配器是为每个声部分配乐器的过程。在进行配器时,整个音乐作品的结构已经基本确定了,这时只需为每个音轨选择合适的音色。从流行音乐角度出发,流行音乐声部注意包括:主旋律声部、管弦伴奏声部、打击伴奏声部,一个完整的作品至少应包含主旋律,而管弦伴奏和打击声部则可以选择性地保留;此外还包括一些装饰音声部,包括特殊效果器、合成器、特殊采样等。由于音色和音型的相关关系,作曲算法中的配器便是通过音色筛选音型的过程。本节从各种乐器之间的共性和特性出发,总结出适合程序实现的配器方法。
首先分析音色之间的差异性:由于不同乐器之间,适用音域、演奏方法、功能角色等不尽相同,每种乐器所对应的音型是不同的,这就要求激励层充分考虑到乐器的差异,因此首先需要对General MIDI音色进行分类。事实上GM音色编码的排列是按照音色规律进行的,但我们希望给出对音型的分类,即音型堆分类,于是按照GM音色表将音型分为了钢琴、吉他、贝斯、风琴、鼓组、弦乐、管风、效果器、民乐和未定义十个堆。通过建立一个二维数组简单地描述这种关系。
1 #define GM_TIMBRE_BANK_NUM 10 2 static const int gm_timbre_banks[GM_TIMBRE_BANK_NUM][27] = 3 { 4 {0, 1, 2, 3, 4, 5, 6, 7, -1}, /* Piano */ 5 {24, 25, 26, 27, 28, 29, 30, 31, -1}, /* Guitar */ 6 {32, 33, 34, 35, 36, 37, 38, 39, -1}, /* Bass */ 7 {16, 17, 18, 19, 20, 21, 22, 23, -1}, /* Organ */ 8 {128, -1}, /* Drums */ 9 {40, 41, 42, 43, 44, 45, 48, 49, 50, 51, 52, 53, 54, 55, -1}, /* Strings */ 10 {56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, -1}, /* Wind */ 11 {80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, -1}, /* Effect */ 12 {104, 105, 106, 107, 108, 109, 110, 111, -1}, /* National */ 13 {8, 9, 10, 11, 12, 13, 14, 15, 46, 47, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, -1} /* Unsorted */ 14 };
从宏观的的角度对音型进行分类,则可以分为伴奏类、独奏类、加花类三种,这些类型都是互相独立,不可替换的。
再分析共同性:在同一类乐器间,某些音色是可以互换的,正是这种互换性减少了分类讨论的种数,同时也为配器提供了更对的选择。音型替换是在音型堆的层面上进行,但前提是类型必须相同,因为替换后的音型必须符和风格要求。如下代码通过建立二维数组描述各音型堆之间的替换关系。
#define RELATED_TIMBRES_NUM 10 static const int related_timbre_banks[RELATED_TIMBRES_NUM][8] = { {FIGURE_BANK_GUITAR, FIGURE_BANK_PIANO, FIGURE_BANK_STRINGS, FIGURE_BANK_WIND, FIGURE_BANK_ORGAN, FIGURE_BANK_EFFECT, FIGURE_BANK_UNSORTED, -1}, /* Piano */ {FIGURE_BANK_GUITAR, FIGURE_BANK_PIANO, FIGURE_BANK_STRINGS, FIGURE_BANK_WIND, FIGURE_BANK_ORGAN, FIGURE_BANK_EFFECT, FIGURE_BANK_UNSORTED, -1}, /* Guitar */ {FIGURE_BANK_BASS, -1}, /* Bass */ {FIGURE_BANK_STRINGS, FIGURE_BANK_WIND, FIGURE_BANK_ORGAN, FIGURE_BANK_EFFECT, FIGURE_BANK_PIANO, -1}, /* Strings */ {FIGURE_BANK_DRUMS, -1}, /* Drums */ {FIGURE_BANK_WIND, FIGURE_BANK_STRINGS, FIGURE_BANK_ORGAN, FIGURE_BANK_EFFECT, FIGURE_BANK_PIANO, -1}, /* Wind */ {FIGURE_BANK_ORGAN, FIGURE_BANK_STRINGS, FIGURE_BANK_WIND, FIGURE_BANK_EFFECT, FIGURE_BANK_PIANO, -1}, /* Organ */ {FIGURE_BANK_EFFECT, FIGURE_BANK_STRINGS, FIGURE_BANK_WIND, FIGURE_BANK_ORGAN, FIGURE_BANK_PIANO, -1}, /* Effect */ {FIGURE_BANK_NATIONAL, FIGURE_BANK_PIANO, FIGURE_BANK_STRINGS, FIGURE_BANK_WIND, FIGURE_BANK_ORGAN, FIGURE_BANK_EFFECT, FIGURE_BANK_UNSORTED, -1}, /* National */ {FIGURE_BANK_UNSORTED, FIGURE_BANK_PIANO, FIGURE_BANK_WIND, FIGURE_BANK_ORGAN, FIGURE_BANK_EFFECT, FIGURE_BANK_NATIONAL, -1} /* Unsorted */ };
对音型的筛选,需要以当前声部为参考,优先选取满足当前类型的所有音序。倘若得出的音型数量不足时,再考虑互换音色。如下程序给出了具体实现,循环体中,首先进行精确匹配,若找到匹配项则继续下次循环,否则进行模糊匹配。模糊匹配的前提是音型的类型一致,其次是两种音型具有可互换的音型堆。
1 std::vector<const KnowledgeEntry *> related_entries; 2 std::vector<int> related_tracks; 3 4 for(std::size_t i=0; i < knowledge_entries.size(); i++) 5 { 6 std::vector<int> timbre_banks; 7 std::vector<int> figure_banks; 8 std::vector<int> figure_classes; 9 10 if( int err = get_timbres(knowledge_entries[i], timbre_banks, figure_banks, figure_classes) ) 11 return err; 12 13 bool not_found = true; 14 for(std::size_t j=0; j < timbre_banks.size(); j++) 15 { 16 if( figure_bank == figure_banks[j] && figure_class == figure_classes[j] ) 17 { 18 not_found = false; 19 dst_entries.push_back(knowledge_entries[i]); 20 dst_tracks.push_back(j); 21 break; 22 } 23 } 24 if( not_found ) 25 { 26 for(std::size_t j=0; j < timbre_banks.size(); j++) 27 { 28 if( figure_class == figure_classes[j] ) 29 { 30 if( is_timbre_bank_related(figure_bank, figure_banks[j]) ) 31 { 32 related_entries.push_back(knowledge_entries[i]); 33 related_tracks.push_back(j); 34 break; 35 } 36 } 37 } 38 } 39 } 40 41 /* 42 * Utilize related figures when the quantity of matched figures is poor. 43 */ 44 if( dst_entries.size() < 10 ) 45 { 46 for(std::size_t i=0; i < related_entries.size(); i++) 47 dst_entries.push_back(related_entries[i]); 48 for(std::size_t i=0; i < related_tracks.size(); i++) 49 dst_tracks.push_back(related_tracks[i]); 50 }
在音型筛选的基础上,只需考虑声部安排即可实现配器。在这之前我们讨论的作曲模型是面向单个音轨的,为了便于多声部作曲,有必要对作曲模型做出调整。首先为N个音轨分配对应的逻辑变换层,注意逻辑与实例是两个相对的概念,算法允许内存中只有一个变换层实例的情况;其次在主数据路径上添加配器筛选,调整后的作曲模型如图所示:
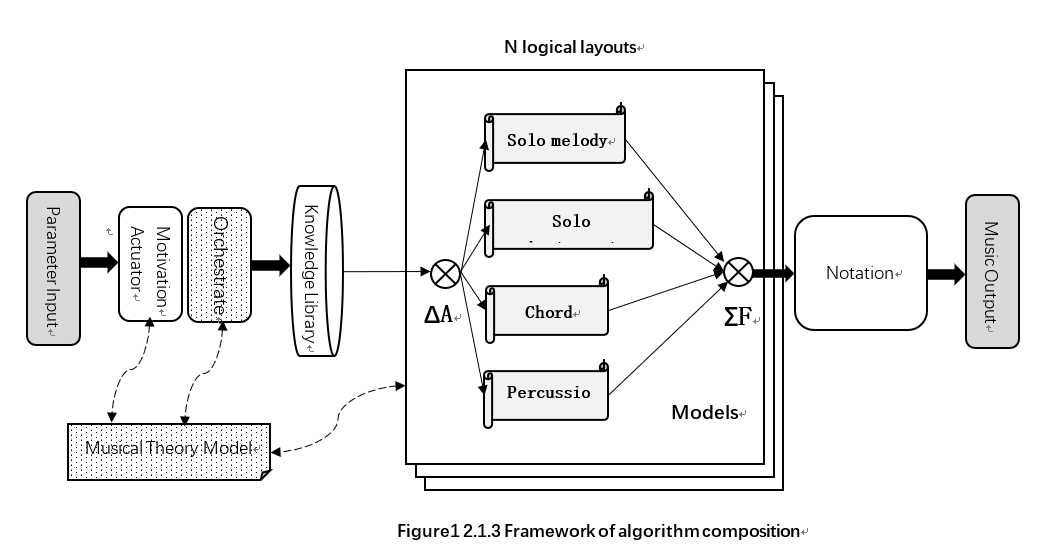
根据动机激励器输出,循环对每个变换层进行配器。算法维护一个全局集合U,集合U记录必须排除的乐器类型。每次配器前,算法都随机选取乐器,并检查当前乐器是否存在于U中,若存在则重新选取。得出乐器后,根据音色与音型的筛选规则对知识库中的音型进行筛选,得出最终音型并发送到变换层处理。若选取的乐器为主旋律乐器或鼓组,则将当前乐器添加到集合U中,否则无需添加到集合U。为每个音轨都分配了乐器后,算法结束。
全局集合U的主要作用在于避免同一音乐作品中出现重复的主旋律或鼓组,同时不会约束其它乐器的重复出现。例如流行音乐中出现双吉他或者多组弦乐是可以接受的。
2.1.4 曲式结构的建模
流行音乐在发展过程中,已经形成了基本稳定的曲式结构。算法作曲中对曲式结构的处理与对配器的处理完全相似,其本质都为根据曲式结构与音型的相关关系对音型进行筛选。曲式结构同样可以用模板来表达。而不同结构之间,同样具有可互换替换性。总体来说,曲式结构筛选算法的实现思路与配器筛选算法基本一致,这里不在赘述。
如下程序实现曲式结构的筛选,其思路非常简单:首先进行精确筛选,若无法得出结果,则采取替换规则。若筛选后仍无结果,则从原始音型中随机选取。
const FigureListEntry *pick_form(StructureForm::FormType form, const std::vector<const FigureListEntry *> &forms_vector) { for(std::size_t i=0; i < forms_vector.size(); i++) if( int(form) == forms_vector[i]->segment ) return forms_vector[i]; const StructureForm::FormType *candidate_form = form_replacement_rules[form]; for(unsigned int i=0; candidate_form[i] != StructureForm::FORM_INVALID; i++) for(std::size_t j=0; j < forms_vector.size(); j++) if( int(candidate_form[i]) == forms_vector[j]->segment ) return forms_vector[j]; return util::random_choice(forms_vector); }
为了方便曲式结构的转换,需要实现对不同长度音型之间的转换。一种方法是对音符起止位置进行比例伸缩变换,但这种方法将导致原始音型拍速的改变,因此设计非连续的伸缩变换是解决问题的关键。另外,转换分为上行转换和下行转换两种情况:对于上行转换,要求从短音型转换到一个较长的音型,而下行转换则恰恰相反。下面就两种情况分别做出讨论。
上行转换时,由于拍速的限制,不能对原始音型进行拉伸。为了便于实现,采用重复原始音型结尾的方法。设原始音型长度为Ls,目标音型长度为Ld,ΔL0 = |Ls - Ld|,则又有如下两种情况:
1. ΔL0 <= Ls,此时可以直接从原始音型Ls - ΔL0位置开始,选取音符填补到空缺位置
2. ΔL0 > Ls,由于空缺位置长度超出了原始音符的长度,因此不能简单地从Ls - ΔL0开始。此时可以分块填补,即:每次从Ls - min{Ls, ΔL}位置开始,每次填补后将ΔL减去已经填补的长度,并继续下次填补,直到没有空缺为止。开始位置与ΔL的递推式如下:
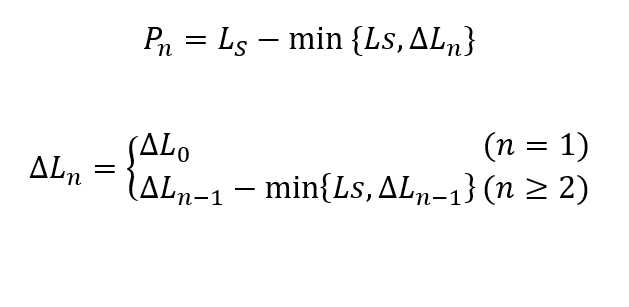
下行转换时,情况则简单很多。我们同样不能对全部音符进行压缩,为了简化,直接将原始音型中,起音时间超出目标长度的音符删除,并修改起音时间在允许范围内,但关断时间超出目标长度的音符,使其在目标音型长度的时间内关断。
向作曲算法总体框架中添加曲式结构筛选,如图所示为修改后的框架。
2.2 知识库设计
知识库是知识库系统中主要的数据来源,承担数据的存取和调用的工作。本文讨论一种基于YAML语言的知识库设计方法。YAML是YAML Ain‘t Markup Language的递归缩写,该语言旨在强化数据的中心地位,而不是语言本身,相较于XML等较为复杂的标记语言,YAML提供了简洁的格式,便于人类阅读修改的同时,也能方便计算机的读取,降低解析成本。本文采用开源的yaml-cpp类库实现YAML文件的解析工作。
知识库的规划,需要大致明确知识库中存储的数据内容,同时提供可扩展的特性,方便后续添加新的数据项。首先,整个知识库可看作是一个大型的一维数组,而数组中的每个元素构成了知识库中的每一项数据。对于每项数据,我们提供两个入口knowledge_array、knowledge_constraint,knowledge_array是数据项内的小型数组,负责存储知识实体;而knowledge_constraint是一个字典,负责存储本数据项的相关参数,例如调式,拍号,速度等。
如下为数据文件中,一个knowledge_array的示例:
knowledge_array:
-
timbre_bank: 1
figure_bank: 1
class: 1
figure_list:
- node:
chord: [10,0,10,0,10,0,10,0,5,0,5,0,5,0,5,0,10,0,10,0,10,0,10,0,10,0,10,0,10,0,10,0,10,0,10,0,10,0,10,0,10,0,10,0,...]
segment: 1
offset: 1
begin: 0
end: 8
pitch: []
- node:
chord: [10,0,10,0,10,0,10,0,3,0,3,0,3,0,3,0,7,1,7,1,7,1,7,1,5,0,5,0,5,0,5,0,3,0,3,0,3,0,3,0,2,1,2,1,2,1,2,1,0,1,0,1,0,1,0,1,5,0,5,0,5,0,5,0]
segment: 2
offset: 1
begin: 8
end: 16
pitch: [65,120,12,16,74,120,16,24,74,120,24,28,72,120,28,32,...]
该实例显示了knowledge_array中的每个知识实体都具有的基本参数,timbre_bank反映了该实体的GM音色编号。figure_bank反映了该实体的音型堆编号,知识库为各种音型堆分配了连续的整数编号,见表1。
| 索引 | 符号 | 描述 |
| 0 | FIGURE_BANK_PIANO | 钢琴 |
| 1 | FIGURE_BANK_MELODY | 旋律独奏 |
| 2 | FIGURE_BANK_GUITAR | 吉他 |
| 3 | FIGURE_BANK_BASS | 贝斯 |
| 4 | FIGURE_BANK_ORGAN | 风琴 |
| 5 | FIGURE_BANK_DRUMS | 鼓组 |
| 6 | FIGURE_BANK_STRINGS | 弦乐 |
| 7 | FIGURE_BANK_WIND | 吹奏 |
| 8 | FIGURE_BANK_FX | 效果 |
| 9 | FIGURE_BANK_NATIONAL | 民乐 |
| 10 | FIGURE_BANK_UNSORTED | 未分类 |
表1
class反映了该实体的音型特征,具体编号见表2
| 索引 | 符号 | 描述 |
| 0 | FIGURE_CLASS_CHORD | 和弦 |
| 1 | FIGURE_CLASS_SOLO | 独奏 |
| 2 | FIGURE_CLASS_DEC | 加花 |
表2
figure_list中记录了所有可能的音型。其中chord记录了该音型对应的和弦序列。和弦序列由若干和弦向量组成。segment记录了该音符序列可能出现的曲式结构。begin、end、offset记录该音符序列在完整作品中出现的位置信息。pitch记录了所有音符,音符以四维向量Vn=(p, v, s, e)的形式表示。
而knowledge_constraint存储的信息则比较简单,如下为一个实例:
knowledge_constraint:
key: 10
scale: 0
tempo: 69
time_beats: 4
time_beat_type: 4
character: [0,1,2,3,4,5,6,7]
genre: [0,1,2]
其中前五个字段主要记录了数据项的一些基本参数,包括调式、调性、拍速、拍号。character和genre记录了反映音型特性的数字索引。
有了数据的具体格式,就可以开始知识库的设计工作。知识库的首要任务就是将磁盘中的数据文件加载到内存中,并解析为可用的数据结构,通过一个全局链表保存所有数据项。如下为加载和解析数据文件函数的伪代码:
1 try 2 { 3 YAML::Node root = YAML::LoadFile(filename); 4 YAML::Node knowledge_array = root["knowledge_array"]; 5 YAML::Node knowledge_constraint = root["knowledge_constraint"]; 6 7 if( knowledge_array.IsSequence() && knowledge_constraint.IsMap() ) 8 { 9 (Create a data entry) 10 for(std::size_t i=0; i < knowledge_array.size(); i++) 11 { 12 (Read-in figures from knowledge_array) 13 (Push figures into the list of data entry) 14 } 15 16 (Read-in parameetrs from knowledge_constraint) 17 (Modify data entry) 18 (Push data entry into global list) 19 } 20 } 21 catch( YAML::Exception &excp ) 22 { 23 (error handling) 24 }
其次还应提供操作数据的接口,包括数据的存取等。本算法所涉及的数据存取较为简单,主要为通过character和genre匹配所有和弦序列、乐器音色或完整的音型,其次为提供通过索引随机访问数据库的接口。完整的知识库接口如下:
1 public: 2 int loadModel(const char *filename); 3 inline std::vector<const KnowledgeEntry *> & models() 4 { 5 return m_knowledgeEntries; 6 } 7 8 int getChord(std::vector<const KnowledgeEntry *> & dst, int character); 9 int getTimbreBank(std::vector<const KnowledgeEntry *> & dst, int genre); 10 int getKnowledgeEntry(std::vector<const KnowledgeEntry *> & dst, int character); 11 int getKnowledgeEntry(std::vector<const KnowledgeEntry *> & dst, int character, int genre);
2.3 变换层模型设计
变换层主要涉及四种基本模型。在抽象一节我们指出,变换的对象涉及两个音型:原始音型与目标音型,针对不同的音型类型有不同的变换方法。由于篇幅有限,本节重点从独奏音型变换和伴奏音型变换两个层面论述。
2.3.1 solo音型变换
solo音型的变换,根本目标是使变换后的旋律与原始旋律相似,而保持原始节奏。该算法的价值在于能获得大量新的音型,从而为作曲过程增加变化。算法的输入为原始音序和目标音序,约束条件是原始音型的和弦走向,输出为变换后的音序。
旋律变换需要解决的首要问题是原始音型音符数量与目标音型不同,原始节奏与目标节奏并不呈现一一对应关系,因此如何确定目标音型中的每个音便成为了问题的关键。我们采用取区间内平均值的方法,对于目标音型中每个音符,其开始位置为Ps,结束位置为Pe,T为原始音型中由Ps开始到Pe截止的所有音符的平均值,则易知目标音符Td与T有某种关联。首先考虑直接取Td = T,发现得出的音型非常不协和,原因是直接取平均值的方法没有考虑到各音符直接音程的关系,出现大量不协和音程,解决办法是从原始音型中选取音符,最大程度保留原始音程关系。
参考前一节和弦走向变换中残差Q的表示方法,我们引入由原始音型中从Ps到Pe的所有音符组成的集合N,表示solo音型变换的残差如下:
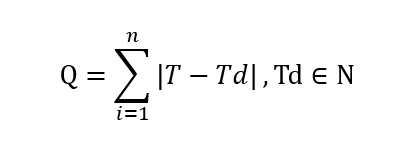
但这种方法存在某种局限性,因为使得残差Q最小的的Td,不一定能与当前和弦相协和。而一旦出现这种不协和音,对最终效果的贡献往往是负面的。解决的办法是额外引入一个约束参数,使得Td与当前和弦达到一定程度上的协和。
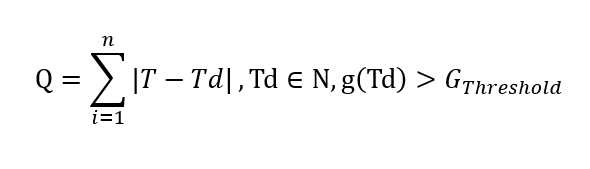
列中,g(x)为音符x与当前和弦协和程度的评估函数,g(x)取值与协和程度正相关。Gthreshold为协和程度的阈值,当超过这个阈值时,说明该音符协和程度达到了要求。至此,我们已经建立了音高变换的基本模型。
考虑评估函数g(x)的实现。对于出现在和弦组成音中的音,我们可以认为该音与和弦完全协和,规定此时g(x)=1。则对于完全不协和与完全协和之间的每个音符,g(x)都可以取到(0,1]之间的某个数值。由于原始音与和弦组成音的音程差与协和程度呈现负相关,因此用C++设计评估函数如下。
1 float g_pitch_chord(int pitch, const ChordPair &chord) 2 { 3 int pitch_offset = util::floor_mod(pitch - chord.root, 12); 4 int min_delta = 128; 5 for(unsigned int i=0; i < CHORD_COMPONENT_PITCH_NUM; i++) 6 { 7 if( chord_component_pitch[chord.sign][i] == pitch_offset ) 8 return 1.0f; 9 int delta = ABS(chord_component_pitch[chord.sign][i] - pitch_offset); 10 if( delta < min_delta) 11 min_delta = delta; 12 } 13 return 1.0f / min_delta; 14 }
上述模型还需要考虑另外两种特殊情况,其一:原始音符与目标音符的起止位置严格对应,此时直接取原始音高作为Td;其二:在原始音符中找不到与当前和弦走向协和的音,此时只能从所有原始音符中选取适合的Td。变换过程关键代码如下:
1 for(int i=0; i < barlen; i++) 2 { 3 std::vector<PitchNote> reg_rhythm_figure_list; 4 std::vector<PitchNote> reg_pitch_figure_list; 5 6 /* 7 * Data Window 8 * Only does it process notes that is in the current bar. 9 */ 10 int32_t bar_start = i * 2 * 2 * 2 * 2 * beats; 11 int32_t bar_end = (i + 1) * 2 * 2 * 2 * 2 * beats; 12 for(std::size_t j=0; j < src_figures.size(); j++) 13 { 14 if( bar_start <= dst[j].start && dst[j].start < bar_end ) 15 reg_pitch_figure_list.push_back(dst[j]); 16 } 17 for(std::size_t j=0; j < current_rhythm_figures.size(); j++) 18 { 19 if( bar_start <= current_rhythm_figures[j].start && current_rhythm_figures[j].start < bar_end ) 20 reg_rhythm_figure_list.push_back(current_rhythm_figures[j]); 21 } 22 23 for(std::size_t j=0; j < reg_rhythm_figure_list.size(); j++) 24 { 25 PitchNote &rhythm_figure = reg_rhythm_figure_list[j]; 26 int32_t start_figure = rhythm_figure.start; 27 int32_t end_figure = rhythm_figure.end; 28 29 std::vector<PitchNote> candidate_pitch_figure_list; 30 for(std::size_t k=0; k < reg_pitch_figure_list.size(); k++) 31 { 32 const PitchNote &pitch_figure = reg_pitch_figure_list[k]; 33 if( pitch_figure.end > start_figure || end_figure < pitch_figure.start ) 34 candidate_pitch_figure_list.push_back(pitch_figure); 35 } 36 37 if( candidate_pitch_figure_list.size() ) 38 { 39 if( candidate_pitch_figure_list.size() == 1 ) 40 rhythm_figure.pitch = candidate_pitch_figure_list[0].pitch; 41 else 42 { 43 /* 44 * Statistics the quantity of in-chord notes and point out the average pitch. 45 * The average pitch will be considered as the center (main) pitch. 46 */ 47 std::vector<int> in_chord_index; 48 int sum_pitch_no = 0; 49 for(std::size_t k=0; k < candidate_pitch_figure_list.size(); k++) 50 { 51 int pitch_no = candidate_pitch_figure_list[k].pitch; 52 if(theory::pitch_is_in_chord(pitch_no, chord_list[i])) 53 in_chord_index.push_back(k); 54 sum_pitch_no += pitch_no; 55 } 56 int avg_pitch_no = int(float(sum_pitch_no) / candidate_pitch_figure_list.size()); 57 58 /* 59 * Set the pitch of current note as the nearest pitch related to the center pitch, 60 * which eliminates the possibility that rhythm becomes out of tone. 61 */ 62 if( in_chord_index.size() == 1 ) 63 rhythm_figure.pitch = candidate_pitch_figure_list[in_chord_index[0]].pitch; 64 else if( in_chord_index.size() > 1 ) 65 { 66 int nearest_pitch_no = avg_pitch_no; 67 int nearest_pitch_dis = 129; 68 for(std::size_t m=0; m < in_chord_index.size(); m++) 69 { 70 int index = in_chord_index[m]; 71 if( ABS(candidate_pitch_figure_list[index].pitch - avg_pitch_no) < nearest_pitch_dis ) 72 { 73 nearest_pitch_dis = ABS(candidate_pitch_figure_list[index].pitch - avg_pitch_no); 74 nearest_pitch_no = candidate_pitch_figure_list[index].pitch; 75 } 76 } 77 rhythm_figure.pitch = nearest_pitch_no; 78 } 79 else 80 { 81 int nearest_pitch_no = avg_pitch_no; 82 int nearest_pitch_dis = 129; 83 for(std::size_t index=0; index < candidate_pitch_figure_list.size(); index++) 84 { 85 const PitchNote &figure_pitch = candidate_pitch_figure_list[index]; 86 if( ABS(figure_pitch.pitch - avg_pitch_no) < nearest_pitch_dis ) 87 { 88 nearest_pitch_dis = ABS(figure_pitch.pitch - avg_pitch_no); 89 nearest_pitch_no = figure_pitch.pitch; 90 } 91 } 92 rhythm_figure.pitch = nearest_pitch_no; 93 } 94 } 95 } 96 if( (candidate_pitch_figure_list.size() == 0 || j == reg_rhythm_figure_list.size() - 1) && reg_pitch_figure_list.size() > 0 ) 97 rhythm_figure.pitch = reg_pitch_figure_list[reg_pitch_figure_list.size()-1].pitch; 98 } 99 100 for(std::size_t j=0; j < reg_rhythm_figure_list.size(); j++) 101 dst.push_back(reg_rhythm_figure_list[j]); 102 }
为了评估solo变换模型,我们仍然选择之前的测试的样本作为原始音型,而选择另一样本作为目标音型,目标音型如图所示。

经过solo变换后的音型如下图所示。

以音符序号为横坐标,Td和T为纵坐标,将变换中的T和结果Td绘制成平滑曲线,如图所示。
2.4 记谱层设计
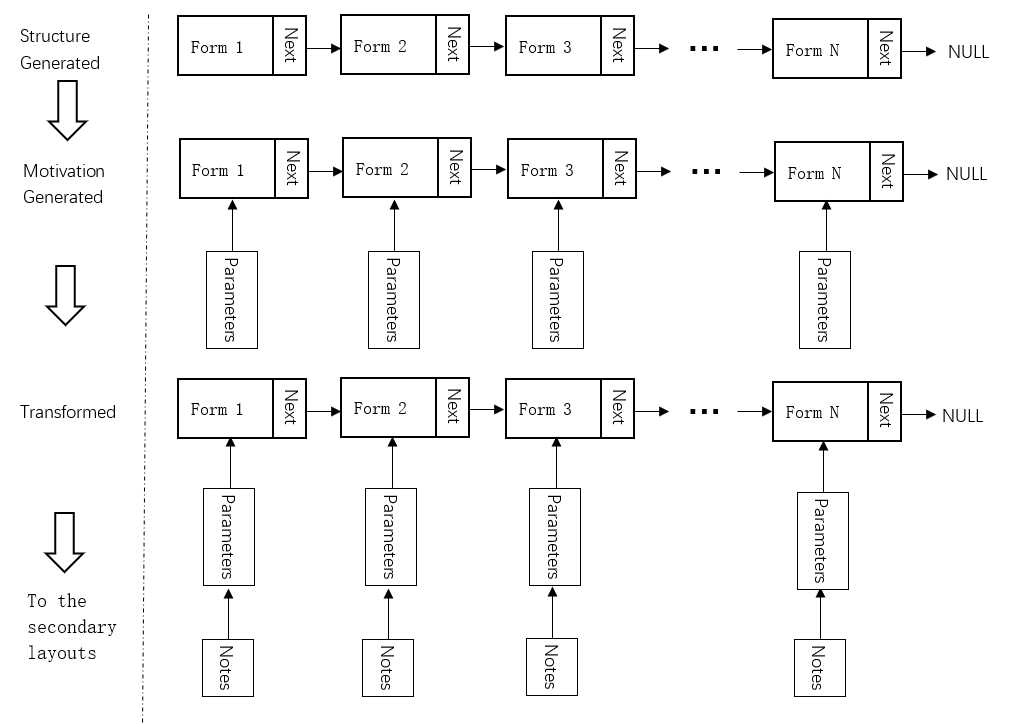
记谱层需要解决表达整个音乐作品的数据结构的问题。流行音乐是由若干个曲式结构(Form)构成的,而完整的音乐作品,可以表达为由N个forms组成的链表,如图显示了链表结构。每个form都具有可动态附加的数据项。链表结构使得算法可以流水线式地向结构中追加数据,随着数据在算法中的逐层流动,链表所保存的信息将逐步增加。当流动到记谱层时,链表所拥有的信息已经足够组织完整的音乐作品。
为了提高通用性,记谱层采用MIDI文件作为最终格式,本节所论述内容也围绕MIDI文件的生成,分析了MIDI文件格式的具体内容与算法内部格式到MIDI规范格式的转换。
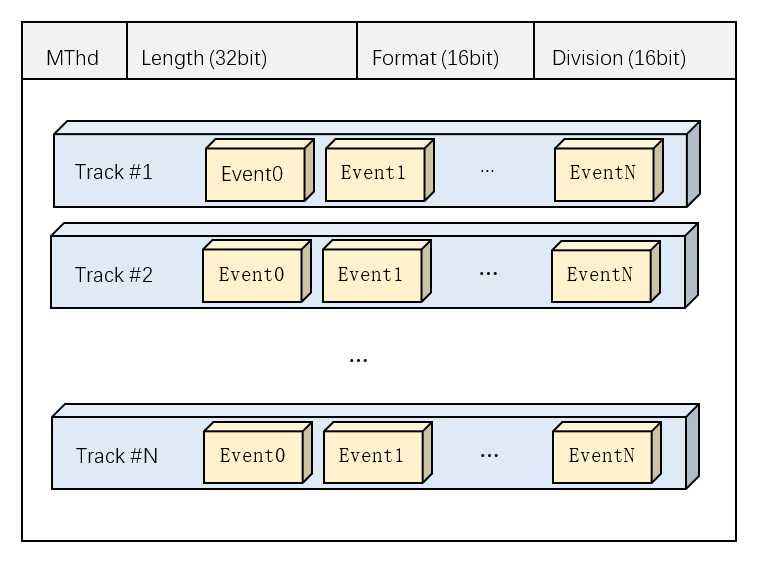
MIDI文件是二进制文件,一个标准的MIDI文件包含了文件头(Headers)和由事件块数据组成的实体(Body)两大部分,其中文件头以MThd开始(小端序机器32bit表示为0x4d546864),包含了数据实体的长度、格式、音轨数量与参考时钟分辨率4个参数。参考时钟是同步所有乐器的统一标准,MIDI中的时间以时钟节拍(Tick)为单位,而参考时钟分辨率与拍速共同决定了每个时钟节拍绝对时间的长度。
一个MIDI文件可以包含多个乐器轨道,每个乐器轨道的所有事件包围在成对出现的track开始事件与结束事件中。一个典型的MIDI文件如下图所示:
MIDI事件是数据主体的组成元素,每个MIDI事件都由事件的时间标记(Delta-Time)和操作码(Opcode)开始,而不同的操作码所对应的参数列表不同。本文重点讨论音符起音(Note On)和关断事件(Note Off)。
MIDI中时间采用增量系统,而事件则是模态(Model)的。所谓增量系统,即当前事件的时间是以相对于上一个事件的时间增量表示的;而模态系统是指若当前事件与前序的事件操作码相同,则省略当前操作码。其次,MIDI还使用了可变长整数表示方法,这种方法称为“动态字节”,具体说来是根据整数自身的二进制长度,动态调整所占的字节数。每个动态字节由1bit标识符和7bit二进制数值组成。标识符的作用为确定当前字节中7bit是否足够表示目标整数,而不发生溢出个。7bit二进制可以表示0~127的整数,如果数据溢出,则把本字节的标志位置1,记录下元素数据高7位,剩下位由下一字节处理,依次循环写入,如图所示为对动态字节的处理,图1(左)显示了对原始整数的拆分,图2(右)显示了按序写入每个动态字节的过程。
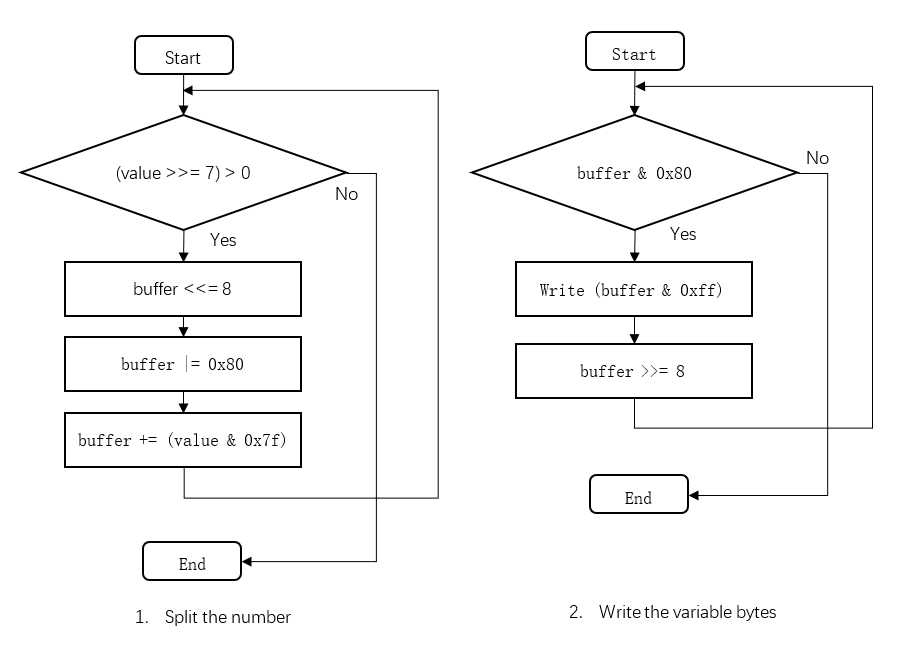
MIDI的量化体系为以tick为核心的相对时间体系。而算法中采用的是1/64音符量化。首先规定每个1/64音符的相对时值为T0,则参考时钟的分辨率为:
Division = T0 * 16
将算法内部音序中所有时间值乘系数T0,便可得到对应于MIDI体系的tick值。
三、后记
本文对乐理模型建模和基于该模型的作曲算法进行了初步讨论,有待完善的地方还有很多:其一:本文所涉及的算法并不属于机器学习,因此缺乏自我学习的能力;其二,本文仅考虑对理论或编曲经验的简单建模,利用的数学工具较为单一,建模精度较低。
本文写作过程历时两天,由于个人能力限制,难免有疏漏之处,还望批评指正。
以上是关于基于乐理模型的算法作曲研究的主要内容,如果未能解决你的问题,请参考以下文章