机器学习入门-K-means算法
Posted my-love-is-python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习入门-K-means算法相关的知识,希望对你有一定的参考价值。
无监督问题,我们手里没有标签
聚类:相似的东西聚在一起
难点:如何进行调参
K-means算法
需要制定k值,用来获得到底有几个簇,即几种类型
质心:均值,即向量各维取平均值
距离的度量: 欧式距离和余弦相似度
优化目标: min∑∑dist(ci, xi) 即每种类别的数据到该类别质心距离的之和最小
1-k x
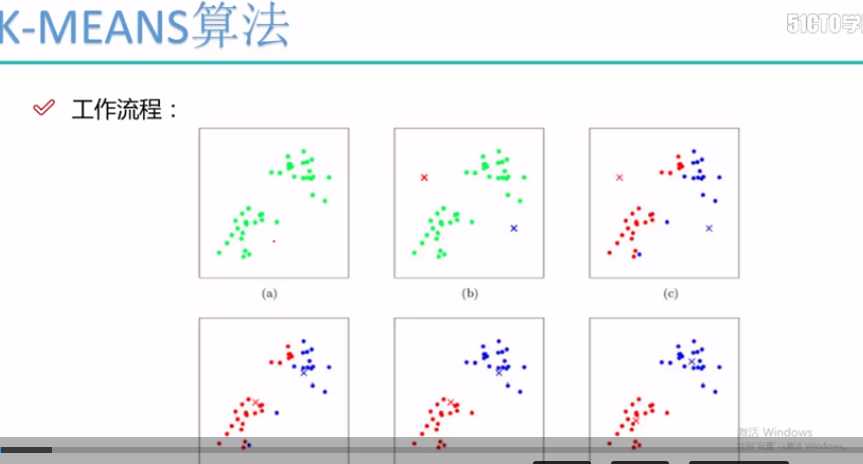
根据上述的工作流程:
第一步:随机选择两个初始点,类别的质心点(图二)
第二步: 根据所选的质心点,根据欧式距离对数据进行分类(图三)
第三步:求得分类后的每个类别的质心(图四)
第四步: 根据所选的质心点,根据欧式距离对数据进行分类(图五)
第五步:求得分类后的每个类别的质心(图五)
.... 一直到分类的数据类别不发生变化为止
优势:简单,快速,适用于常规数据集,分布较为规则的数据集
劣势:
K值难确定
复杂度与样本数据呈线性关系
不太适用于不规则的数据
以上是关于机器学习入门-K-means算法的主要内容,如果未能解决你的问题,请参考以下文章