深度探索二维码及其应用
Posted yunlambert
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度探索二维码及其应用相关的知识,希望对你有一定的参考价值。
前言
二维码在目前我们生活中是太常见了,扫码登陆、扫码支付、加好友......二维码又称QR Code,是一个在移动设备上非常流行的编码方式。
这一篇博客里将从原理和艺术二维码生成的角度来谈一谈,先给大家看看最终的效果:

二维码原理
二维码的前身是超市购物时的条形码(一维码):

但是很明显这个一维码的局限性太大了,只能识别0-9数字编成的标识符;所以在这个信息化社会,二维码的产生我认为是自然而然的。首先,我们先说一下二维码最常见的有黑白两种颜色:

一共有40个尺寸。官方叫版本Version。Version 1是21 x 21的矩阵,Version 2是 25 x 25的矩阵,Version 3是29的尺寸,每增加一个version,就会增加4的尺寸,公式是:(V-1)*4 + 21(V是版本号)
最高Version 40,(40-1)*4+21 = 177,所以最高是177 x 177 的正方形。
下面是一张二维码的简单示意图:
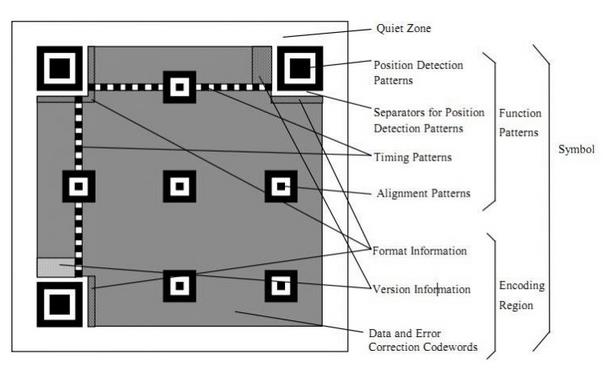
翻译一下是这样的:
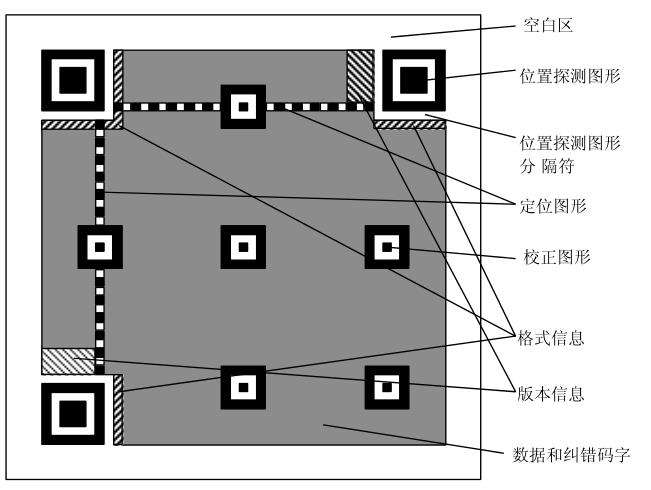
定位图案
任何一个二维码除了右下角,其他的三个方块就是定位图案,用来标记二维码矩形的大小,之所以用3个就和为什么TCP是三次握手一样,少了无法确定信息、多了则显得赘余。定位图形是用作标准线,为了防止尺寸过大后扫描可能会发生扫歪的情况。矫正图形是(Version$ge$2)时定位用的。
功能性数据
格式信息存放格式化数据,版本信息在Version$ge$7时需要预留两块3*6的区域存放版本信息。
数据码和纠错码
图中整个灰色区域就是放置数据码和纠错码的地方,为什么有纠错码我们放在后面详谈。
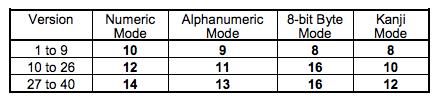
QR码支持以下编码方式:数字编码、字符编码、字节编码、双字节编码、特殊字符集、混合编码以及特殊编码.....不同版本(尺寸)的二维码,对于,数字,字符,字节和Kanji模式下,对于单个编码的2进制的位数:
举个简单具体例子来说明是如何进行数据编码的:
我们现在有个"HELLO WORLD"的字符串需要编码,我们从字符索引表中找到这几个字母的索引:
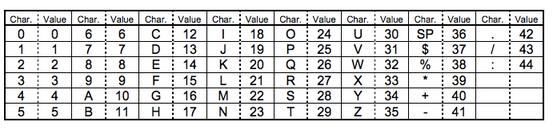
为(17,14,21,21,24,36,32,24,27,21),然后两两分组(17,14),(21,21),(24,36),(32,24),(27,21)。把每一组转成11bits的二进制,比如(17,14)就是17*45+14=779转成01100001011,全部转换后拼接起来为:01100001011 01111000110 10001011100 10110111000 10011010100 001101,然后把字符的个数11专程二进制000001011(Version 1-H为9 bits),最前面加上字符编码0010,其他字符的形式见下表:
| Mode Name | Mode Indicator |
|---|---|
| Numeric Mode | 0001 |
| Alphanumeric Mode | 0010 |
| Byte Mode | 0100 |
| Kanji Mode | 1000 |
| ECI Mode | 0111 |
结尾加上结束符0000。现在总共有78bits,但是部位8的倍数我们还要加上足够的0,然后按8个bits分好组:
00100000 01011011 00001011 01111000 11010001 01110010 11011100 01001101 01000011 01000000
如果最后还没有达到我们的最大bits数的限制,还要加上一些补齐码(魔数11101100 00010001 ),重复这个补齐码就行了,假设我们需要编码的是Version 1的Q纠错级,那么,其最大需要104个bits,而我们上面只有80个bits,所以,还需要补24个bits,也就是需要3个Padding Bytes,我们就添加三个,于是得到下面的编码:
00100000 01011011 00001011 01111000 11010001 01110010 11011100 01001101 01000011 01000000 11101100 00010001 11101100
上面的编码就是数据码了,叫Data Codewords,每一个8bits叫一个codeword,我们还要对这些数据码加上纠错信息。
纠错码数学原理
上面我们说到了一些纠错级别,Error Correction Code Level,二维码中有四种级别的纠错,这就是为什么二维码有残缺还能扫出来,也就是为什么有人在二维码的中心位置加入图标。
| Error Correction Level | Error Correction Capability |
|---|---|
| L | Recovers 7% of data |
| M | Recovers 15% of data |
| Q | Recovers 25% of data |
| H | Recovers 30% of data |
那么,QR是怎么对数据码加上纠错码的?首先,我们需要对数据码进行分组,也就是分成不同的Block,然后对各个Block进行纠错编码,对于如何分组,可以查看下表:
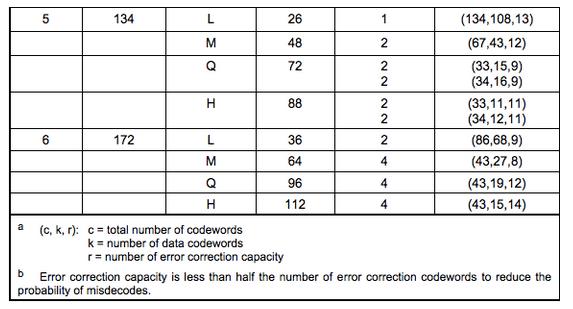
而这里的纠错方法采用的是Reed-Solomon Error correction ,有兴趣的可以前去阅读这一篇博客。这里简要的讲解一下,该算法运营比较广泛,在二维码中,为了抵抗扫描错误或污点,在磁盘中,为了抵抗媒体碎片的丢失,在高级存储系统中,比如谷歌的gfs和bigtable,为了抵抗数据丢失,也为了减少读取延迟(读取可以在不等待所有响应到达的情况下完成)。 (GF(2^{m}))可以在计算机上有效地实现,这意味着我们可以基于数学定理实现系统,而不必担心在对整数或实数建模时通常会遇到的溢出问题。
而在这个纠错过程中,纠错编码采用多项式长除法。为此,需要两个多项式。要使用的第一个多项式称为消息多项式。消息多项式使用来自数据编码步骤的数据码字作为其系数。例如,如果转换为整数的数据码字为25、218和35,则消息多项式将为(25x^{2}+218x+35)。在实际中,标准QR码的实际消息多项式要长得多,但这只是一个例子。消息多项式将被除以生成多项式。生成多项式是通过乘积((x-alpha^{0})......(x-alpha^{n-1}))生成的多项式.其中n是必须生成的纠错码字数(参见纠错表),α等于2,这些在我的博客中也有提到过。在这里也贴上一点:
假如我们现在有一个n-k循环码的生成多项式:(g(x)=1+x^{2}+x^{4}),则生成的(6,2)循环码的码字矢量和码字多项式如下:
| 消息矢量 | 码字矢量 | 码字多项式 |
|---|---|---|
| ((u_{0},u_{1})) | ((v_{0},v_{1},v_{2},v_{3},v_{4},v_{5})) | |
| (0,0) | (0,0,0,0,0,0) | (v_{0}(x)=0*g(x)=0) |
| (0,1) | (1,0,1,0,1,0) | (v_{1}(x)=1*g(x)=g(x)) |
| (1,0) | (0,1,0,1,0,1) | (v_{2}(x)=x*g(x)=x+x^{3}+x^{5}) |
| (1,1) | (1,1,1,1,1,1) | (v_{3}(x)=(x+1)*g(x)=1+x+x^{2}+x^{3}+x^{4}+x^{5}) |
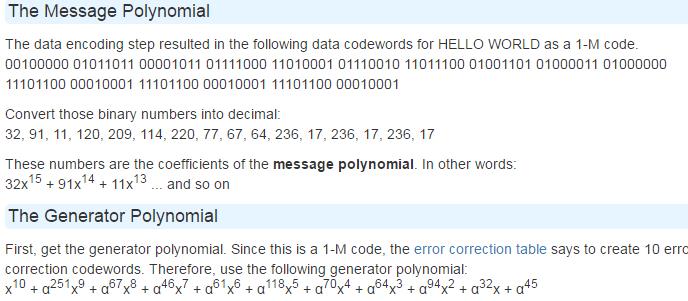
最终编码
在形成最终编码之前,还要把数据码和纠错码的各个codewords交替放在一起。如何交替呢,规则如下: 不论数据码还是纠错码,把每个块的第一个codewords先拿出来按顺度排列好,然后再取第一块的第二个,如此类推。
块1 67 85 70 134
块2 246 246 66 7
块3 182 230 247 119
块4 70 247 118 86先取第一列:67,246,182,70,然后再取第二列:67,246,182,70,85,246,230,247,如此类推就行了,最后把两组放在一起就是我们的数据区。
画二维码图
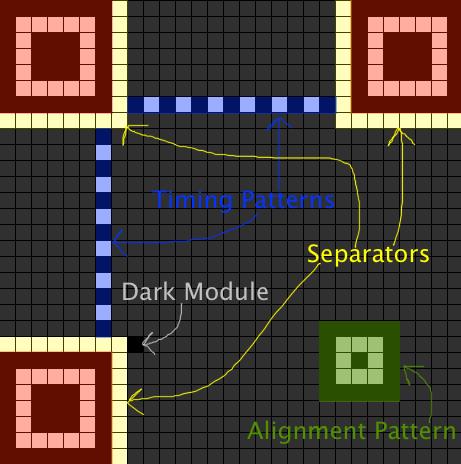
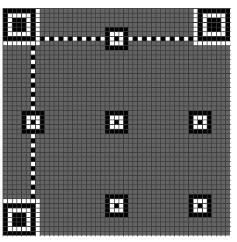
1.首先,先把Position Detection图案画在三个角上。(无论Version如何,这个图案的尺寸就是这么大)
2.然后把Alignment图案画上
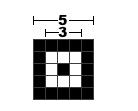
Alignment的位置可以根据QR Code关于Table-E.1的定义表:
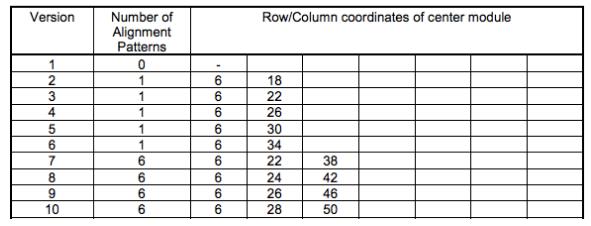
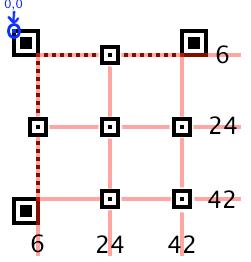
例如Version8,它的校正图形(Alignment Patterns)的数量在表格中为6个,位置分别为(6,24,42),画在图中为:
3.接下来画定位图形(Timing Pattern)的线,很简单将上方和左边的线连起来就OK:
4.然后将格式信息(Format Information)画在图中,由于格式信息是一个15bits的信息,所以按下图来画:
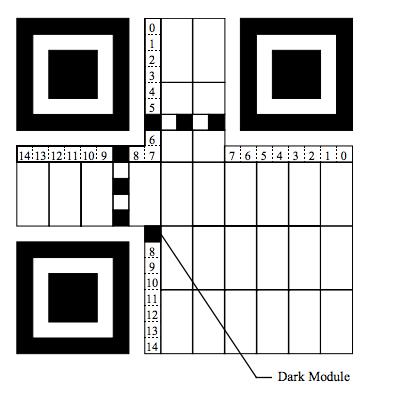
由于Position Detection图案的大小是固定的,所以格式信息始终是图中的标识;而这15bits中包括:5个数据bits(其中,2个bits用于表示使用什么样的Error Correction Level, 3个bits表示使用什么样的Mask)以及10个纠错bits(主要通过BCH Code来计算);然后15个bits还要与101010000010010做XOR操作。这样就保证不会因为选用了00的纠错级别和000的Mask,从而造成全部为白色,这会增加扫描器的图像识别的困难。
5.版本信息(Version大于等于7)如下蓝色部分:
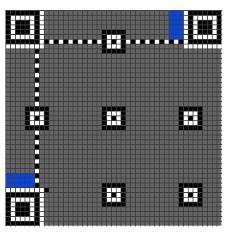
总共18个bits,其中6个bits为版本号、12bits为纠错码,例如Version7:

其填充位置是这样的:
BCH码是一种有限域中的线性分组码,具有纠正多个随机错误的能力,通常用于通信和存储领域中的纠错编码。
这里简要介绍一下BCH编码,想深入的了解如何encode的可以去看我的这一篇博客
若循环码的生成多项式具有如下形式(g(x)=LCM[m_{1}(x),m_{3}(x)..m_{2t-1}(x)])
其中LCM表示最小公倍式,t为纠错个数,(m_{i}(x))为素多项式,则由此生成的循环码称为BCH码,其最小码距(dge d_{0}=2t+1),其中(d_{0})为设计码距,则这个码能纠正t个随机独立差错。
举个例子来有个先验感知:BCH(15,5)码,可纠正3个随机独立差错(t=3),求它的生成多项式。
码距应该为(dge d_{0}=2*3+1=7)
n=15,根据(n=2^{m}-1),得出m等于4;查下表不可约多项式可知:
| 阶数 | 编号 | 多项式(二进制表示) |
|---|---|---|
| 2 | 1 | 111 |
| 3 | 1 | 1101 |
| 4 | 1 3 5 | 010011 011111 000111 |
| 5 | 1 3 5 | 100101 111101 110111 |
于是就有了(m_{1}(x)=x^{4}+x+1),(m_{3}(x)=x^{4}+x^{3}+x^{2}+x+1),(m_{5}(x)=x^{2}+x+1)
这样就得出:
(g(x)=LCM[m_{1}(x),m_{3}(x),m_{5}(x)]=x^{10}+x^{8}+x^{5}+x^{4}+x^{2}+x+1)
6.接着就是加上我们的最终编码,最终编码的填充方式如下:数据位从矩阵的右下角开始放置,并在两个模块宽的列中向上移动。0使用白色像素,1使用黑色像素。当列到达顶部时,下一个2模块列将立即从前一列的左边开始,并继续向下。每当当前列到达矩阵的边缘时,移动到下一个2模块列并更改方向。如果遇到函数模式或保留区域,则将数据位放置在下一个未使用的模块中。
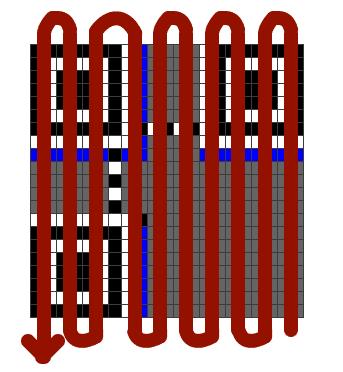
具体的放置方式为:

当然,已经复杂成这样了,我觉得到这里就可以了;但是QR Code并没有让我们到此为止。因为最终编码形成的区域可能会存在点不均衡,可能有大面积的空白或者黑块,扫描识别就会变得非常的困难。所以还要加上Masking(掩码图案)操作,该操作只能应用在数据码和纠错码放置的区域,操作会遵循以下四个规则:

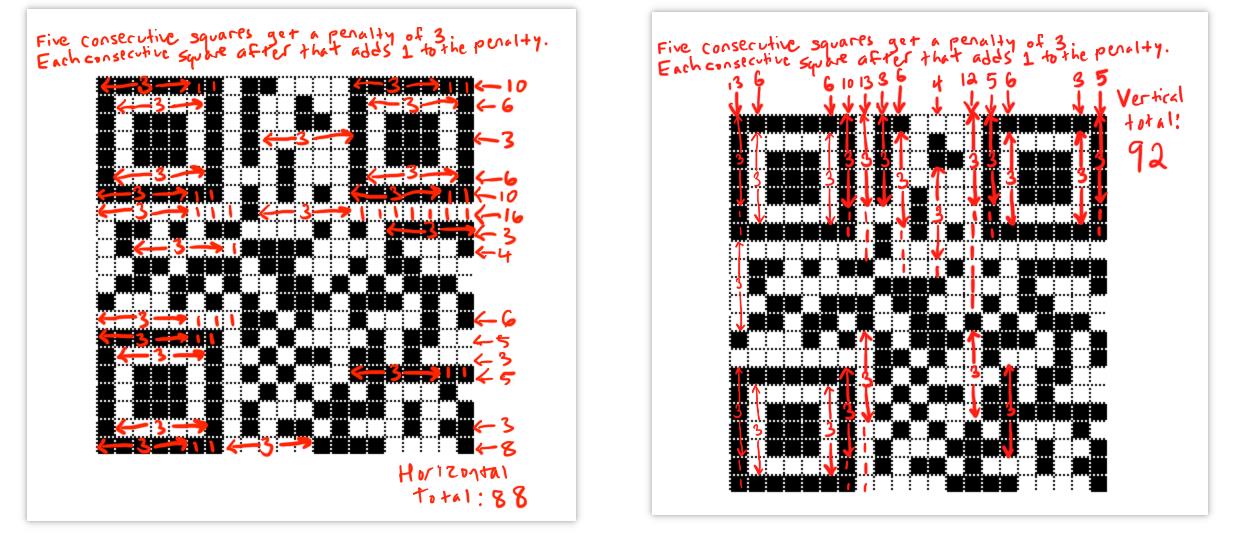
对于第一个评估条件,逐个检查每一行。如果有五个连续模块相同的颜色,增加3的惩罚。如果在前五个之后有更多相同颜色的模块,则为相同颜色的每个附加模块添加一个。然后,逐个检查每一列,检查相同的条件。将水平和垂直总数相加以获得惩罚分数。所以说是行与列都要进行计算,最后累加:
对于第二个评估条件,查找至少2x2模块或更大的相同颜色的区域。QR码规范规定,对于大小为m×n的实色块,惩罚分数为3×(m-1)×(n-1)。然而,QR代码规范并没有指定在有多种方法分割实色块时如何计算惩罚。因此,与其寻找大于2x2的实色块,只需将QR代码中相同颜色的2x2块中的每个2x2块的惩罚分数增加3,确保计算重叠的2x2块。例如,相同颜色的3x2块应该被计算为两个2x2块,一个重叠另一个。
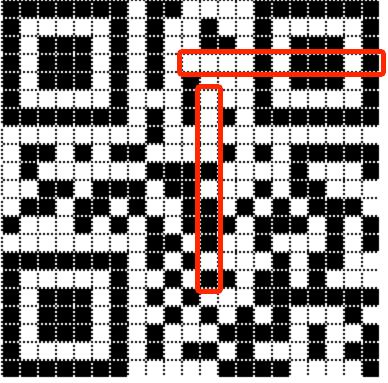
第三个惩罚规则寻找黑白黑黑黑白黑的模式,在两边任意一边存在有四个白模块。换句话说,它查找以下两种模式中的任何一种:

每次发现这种模式时,将40分加到罚分上。在下面的示例中,有两个这样的模式。
最终的评估条件是基于黑与白模块的比例。若要计算此惩罚规则,请执行以下步骤:

举个例子:

该二维码有228个白模块,213个黑模块,总共有441个模块。黑模块占比为48.2993%。该比例是在45-50之间,计算|45-50|=|-5|=5,|50-50|=0,除以5得到答案:1与0.这两个数字中最小的是0。乘以10,这仍然是0。所以该二维码的第四个规则中惩罚分数为0.
最后将这四个规则计算的惩罚分数加起来,再代入Mask计算后选择分数最小的,官方文件说QR有8个Mask可以使用:
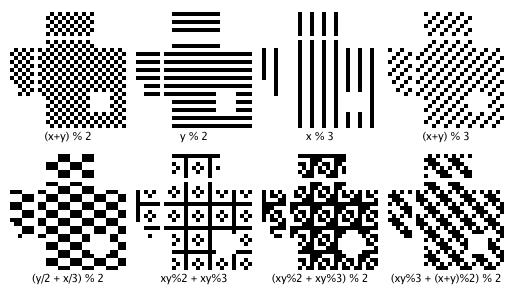
上面的例子如下图,应该选择Mask Pattern 0:

Mask的标识符如下:
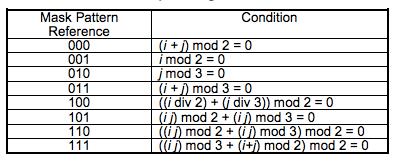
选择不同的Mask算法会有不同的结果
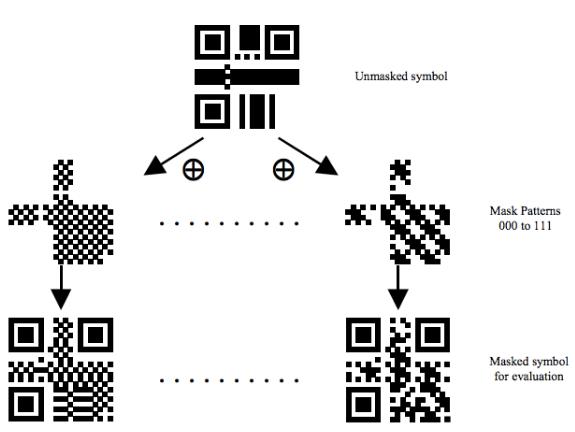
这样才是最终的二维码图。
整体流程简要的提及了一下,更为详细的步骤可以去参看一下这篇博客
最后根据"HELLO WORLD"生成的二维码如下,大家不妨扫一下试试:

艺术二维码
一些思路
首先推荐一下这篇文章里提到的方法:https://research.swtch.com/qart,此外还有一篇Halftone QR Codes与这一篇Embedding grayscale halftone pictures in QR Codes using Correction Trees
首先通过前文二维码的分析我们已经知道了,二维码利用了Reed-Solomon进行了纠错,同时最后会通过一个Mask进行黑白区块调整。
在QR中放置图片。我们可以设计编码的值,在没有固有错误的代码中创建图像,而不是在多余的部分上涂鸦或依靠错误更正来保留意义。而在Halftone QR Codes这篇论文中,通过一种新的二进制模式优化方法,即把数据点(信息点)进行缩小,在二维码图形中生成某种具象图形,从技术层面自动生成一种新的视觉QR码即半色调的QR。而在Embedding grayscale halftone pictures in QR Codes using Correction Trees中则是提出了嵌入灰度半色调图片的设计方法,相当于是前一篇论文在色彩上的改进。
论文中提及的基本都是思想与数学原理,如Halftone QR Codes这篇文章中,就是考虑了可读性与正则性两者,并以一个优化目标作为结果来考虑的。如果要实现的话,还是需要看看代码。
所以下面将就这几个方法进行讨论与实现:
方法1
这个方法是按照https://research.swtch.com/qart进行实现的,7sDream的pyqart实现了这一个算法。基本原理大致是将数据码和纠错码划分了新的区域,经过旋转或者经过其他变换使得仍然是具有意义的编码方式。
简要谈一下代码结构:
pyqart.qr 这一部分是一个基本上完整的二维码生成器, data 模块是数据编码, ec 模块是生成纠错码, args 是二维码的参数, painter.canvas 生成二维码的框架, painter.painter 的作用是把 canvas 、 data 、 ec 三部分组合起来,最后交给 printer 里的各种生成器输出二维码。
pyqart.art 里的 QArtSourceImage 是处理输入图像的,做一些二值化,dithering,计算对比度之类的操作。 QrArtist 里的 bis 函数是 QArt 的关键算法。
该方法产生的效果图如下:

方法2
这个方法在sylnsfar的qrcode中已经有完整的代码实现,sylnsfar自己实现了绘制二维码的代码,在该项目的mylibs中进行了实现,有兴趣的可以前去观摩一下。
首先看MyQR/mylibs/constant.py,这里的都是一些参数设置,供其他文件调取的。
MyQR/mylibs/matrix.py文件,其中有下面这些部分代码:
def get_qrmatrix(ver, ecl, bits):
num = (ver - 1) * 4 + 21
qrmatrix = [[None] * num for i in range(num)]
# [([None] * num * num)[i:i+num] for i in range(num * num) if i % num == 0]
# Add the Finder Patterns & Add the Separators
add_finder_and_separator(qrmatrix)
# Add the Alignment Patterns
add_alignment(ver, qrmatrix)
# Add the Timing Patterns
add_timing(qrmatrix)
# Add the Dark Module and Reserved Areas
add_dark_and_reserving(ver, qrmatrix)
maskmatrix = [i[:] for i in qrmatrix]
# Place the Data Bits
place_bits(bits, qrmatrix)
# Data Masking
mask_num, qrmatrix = mask(maskmatrix, qrmatrix)
# Format Information
add_format_and_version_string(ver, ecl, mask_num, qrmatrix)
return qrmatrix通过注释我们可以知道就是生成二维码的步骤!
MyQR/mylibs/data.py是对数据进行编码,MyQR/mylibs/ECC.py是利用Reed-Solomon进行纠错。MyQR/mylibs/structure.py是将data.py文件和ECC.py文件生成的数据码和纠错码进行联合并组织好最终编码形式。
MyQR/mylibs/draw.py是一个绘图程序,绘制边界与黑色模块。
最终汇集所有功能代码至MyQR/mylibs/theqrmodule.py中得到最终qrcode。
而将自己的图像与qrcode结合在一起的代码位于myqr.py中的combine函数。
效果图如下:

该二维码跳转至sylnsfar的github个人首页。
方法3
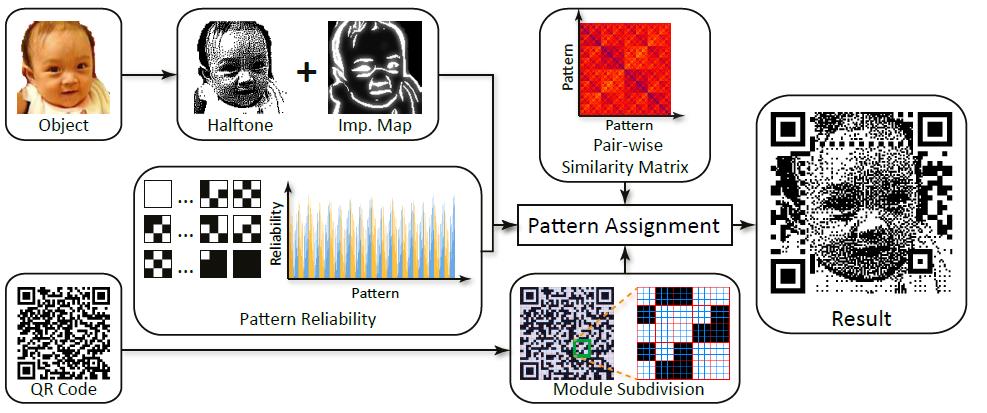
实现时,我们需要引入一个qrcode的package,这样我们就不用像方法2中那样手动按步骤生成二维码了。
首先实验一下这个qrcode包:
import qrcode
# ERROR_CORRECT_L
# About 7% or less errors can be corrected.
# ERROR_CORRECT_M (default)
# About 15% or less errors can be corrected.
# ERROR_CORRECT_Q
# About 25% or less errors can be corrected.
# ERROR_CORRECT_H.
# About 30% or less errors can be corrected.
qr = qrcode.QRCode(
version=1,
error_correction=qrcode.constants.ERROR_CORRECT_L,
box_size=10,
border=4,
)
qr.add_data('Some data is here,BY YunLambert') # 这里放链接也是OK的
qr.make(fit=True)
img = qr.make_image(fill_color="black", back_color="white")
img.save("test.png")结果出来的图片是这样的:

这里主要参考了chinuno的CuteR,具体的一些解释我也放在代码注释里了。值得一说的是,chinuno的代码对于gif处理是通过PIL将一张gif图一帧一帧进行处理,然后集中到一起播放的,生成的代码如下:
if len(result) == 1 or output.upper()[-3:] != "GIF": # 如果成功生成1张图片或者文件后缀不为GIF的多张图片
result[0].save(output)
elif len(result) > 1: # 如果是动图
result[0].save(output, save_all=True, append_images=result[1:], duration=100, optimize=True)考虑了加入images2gif这个package,原本想要使得处理gif会更加得体一些,但是花了很长时间研究images2gif后我发现结果生成的效果并不好(-_-||).......
代码中也加了images2gif这部分,如果是python3以上的话,很有可能会出现无法导入的情况,这里可以参照这一篇博客或者这些办法进行修改。
生成的结果如下:

以上是关于深度探索二维码及其应用的主要内容,如果未能解决你的问题,请参考以下文章