性能分析以及优化
使用的是vs2017自带的性能分析工具。
主要分析了遇到的性能瓶颈,以及想到的优化方法,有的验证了,有的没有来得及。
首先看整体用时以及cpu占有率。
最终在我的设备上(I5-5200U 三星860EVO固态)运行时间约为27.3S。期间cpu占有率比较稳定.

前0.5秒cpu占用率低,大概是因为这段时间是刚开始读取文件,cpu并没有处理任务,后来便进入一边读取一遍计算的状态,cpu占有率就上来了,大概25%,但是还是不高。
而且在这里我遇到一个十分奇怪的现象
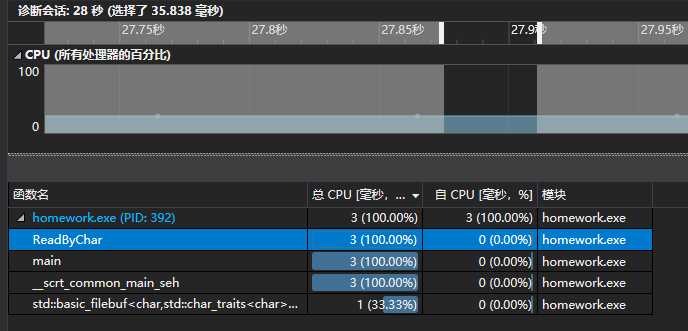
直到代码运行结束,ReadByChar的占有率一直居高不下,占有一直接近100%,这就有点难以理解,讲道理最后cpu做的是事情应该是遍历1600多万个单词查找最大值,并且感觉应该会花许多时间,也就是说查找前十的top()函数应该在最后的的几秒占用率极高,但是没有发现这个现象,感觉应该还是这个性能分析结果自己理解有偏差把。
我们先看看性能瓶颈:

ReadByChar是我写的字符读入,以及单词判定逻辑实现的函数,并且其调用了许多其他函数,所以它飘红是意料之中的。
进入函数,首先占用最高的是

openbychar是一个fstream的实例对象,get()为获取字符的方法,虽然条语句花费了许多时间,但这是必须的,处理思路就是要求必须一个一个的处理,基本没有优化余地,但是假如创建对象,而是使用c语言文件读取的方法,因为不需要创建对象调用方法,一定是可以快的,但是最后时间没来的及,就没有改。
从这里我们也可以发现,文件读取(IO)是一个瓶颈,我当时有思考大幅度改善这个问题,不太确定多线程能否改善这个问题,因为在这个程序中应该是不处理完当前字符是不会读取下一个的,但是多线程后,可以将文件分成多份分别处理,再综合起来,因为从代码热行看,哈希表访问是非常快的,几乎没有耗费时间,这样最后结果整合应该也花费不了多少时间,但是无奈时间仓促,而且ddl前出现了bug,没有来得及验证,最近有时间一定试一下。

word[sword]与wordend[sword]查找都用时较多,但这个也是没有办法的,这部分花费查找的时间也是必须的,而且选取hash已经是想到的最优的方法,再想优化,就得针对数据特征进行分析,更改默认的hash函数 ,让单词尽量减少冲突,这花费时间太多了,也不一定能比默认的hash快多少,所以就没搞。

这个地方是我之前说过的唯一一处算是做出有卓越成效的优化,首先这两句是完成词组拼接,每判定成功就要执行一次,从最后单词结果看是执行了1600多万次,我之前图简单,直接写的是sphrase=sphrase+ " ”+sword,总时间占有率高达10%,但是这样写表达式右侧会先创建一个对象储存结果,然后再赋给sphrase,比较复杂,想变快应该调用string自带的拼接方法,我更改之后,占有率直接降到1%以下。
其余的代码在整个代码运行过程中几乎不占多少时间。
但是假如真的是追求极致的话,感觉有几个细节还是可以修改下的。
1
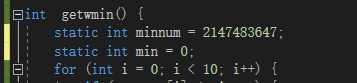
一些经常调用的函数中的变量对象可以用static修饰为静态,这样就不用每次调用时候都重新创建对象了,有这个特点的是getmax(),getmin()函数,这两个在输出结果文件,以及查找前十中会被多次用到,但是对于一个30s的任务,这样的优化根本没有什么作用。
2
查找前十的方法,我是一次遍历,遍历过程中储存一个数组,每次替代其中的最小值,这样每读一个词,就要在10个词中查找最小值,这个从分析看并不是性能瓶颈,因为10个实在太少了,但是假如查找最小的10000个,100000个肯定就不能这么写了,我们虽然还是用一次遍历的方法,但是此时应该维护的是一个10000大小的最小堆。
以上就是性能分析以及优化思路