hbase的典型场景
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hbase的典型场景相关的知识,希望对你有一定的参考价值。
1. hbase整合Mapreduce
在离线任务场景中,MapReduce访问HBASE数据,加快分析速度和扩展分析能力。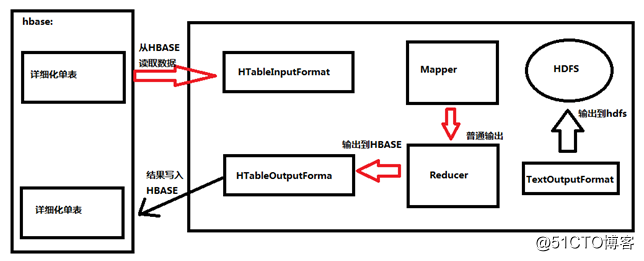
从hbase中读取数据(result)
public class ReadHBaseDataMR {
private static final String ZK_KEY = "hbase.zookeeper.quorum";
private static final String ZK_VALUE = "hadoop01:2181,hadoop01:2182,hadoop03:2181";
private static Configuration conf;
static {
conf=HBaseConfiguration.create();
conf.set(ZK_KEY,ZK_VALUE);
//因为是从hbase中读取到自己的hdfs集群中,所以这里需要加载hdfs的配置文件
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
}
//job
public static void main(String[] args) {
Job job = null;
try {
//这里使用hbase的 conf
job = Job.getInstance(conf);
job.setJarByClass(ReadHBaseDataMR.class);
//全表扫描
Scan scans=new Scan();
String tableName="user_info";
//设置MapReduce与hbase的整合
TableMapReduceUtil.initTableMapperJob(tableName,
scans,
ReadHBaseDataMR_Mapper.class,
Text.class,
NullWritable.class,
job,
false);
//设置ReducerTask 的个数为0
job.setNumReduceTasks(0);
//设置输出搭配hdfs上的路径
Path output=new Path("/output/hbase/hbaseToHDFS");
if(output.getFileSystem(conf).exists(output)) {
output.getFileSystem(conf).delete(output, true);
}
FileOutputFormat.setOutputPath(job, output);
//提交任务
boolean waitForCompletion = job.waitForCompletion(true);
System.exit(waitForCompletion?0:1);
} catch (Exception e) {
e.printStackTrace();
}
}
//Mapper
//使用TableMapper,去读取hbase中的表的数据
private static class ReadHBaseDataMR_Mapper extends TableMapper<Text, NullWritable> {
Text mk = new Text();
NullWritable kv = NullWritable.get();
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
//默认的按照每一个rowkey读取
List<Cell> cells = value.listCells();
//这里以四个坐标确定一行记录,行键,列簇,列,时间戳
for(Cell cell:cells){
String row= Bytes.toString(CellUtil.cloneRow(cell)); //行键
String cf=Bytes.toString(CellUtil.cloneFamily(cell)); //列簇
String column=Bytes.toString(CellUtil.cloneQualifier(cell)); //列
String values=Bytes.toString(CellUtil.cloneValue(cell)); //值
long time=cell.getTimestamp(); //时间戳
mk.set(row+" "+cf+" "+column+" "+value+" "+time);
context.write(mk,kv);
}
}
}
}写入数据到hbase中(put)
public class HDFSToHbase {
private static final String ZK_CONNECT_KEY = "hbase.zookeeper.quorum";
private static final String ZK_CONNECT_VALUE = "hadoop02:2181,hadoop03:2181,hadoop01:2181";
private static Configuration conf;
static {
conf=HBaseConfiguration.create();
conf.set(ZK_CONNECT_KEY,ZK_CONNECT_VALUE);
//因为是从hbase中读取到自己的hdfs集群中,所以这里需要加载hdfs的配置文件
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
}
//job
public static void main(String[] args) {
try {
Job job = Job.getInstance(conf);
job.setJarByClass(HDFSToHbase.class);
job.setMapperClass(MyMapper.class);
//指定Map端的输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
/**
* 指定为nulL的表示使用默认的
*/
String tableName="student";
//整合MapReduce reducer 到hbase
TableMapReduceUtil.initTableReducerJob(tableName,MyReducer.class,
job,null, null, null, null,
false );
//指定MapReducer的输入路径
Path input = new Path("/in/mingxing.txt");
FileInputFormat.addInputPath(job, input);
//提交任务
boolean waitForCompletion = job.waitForCompletion(true);
System.exit(waitForCompletion ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
//Mapper
private static class MyMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
NullWritable mv = NullWritable.get();
//map端不做任何操作,直接将读取的数据输出到reduce端
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
context.write(value, mv);
}
}
//Reudcer,使用TableReducer的Reudcer
/**
* TableReducer<KEYIN, VALUEIN, KEYOUT>
* KEYIN:mapper输出的key
* VALUEIN:mapper输出的value
* KEYOUT:reduce输出的key
* 默认的有第四个参数:Mutation,表示put/delete操作
*/
private static class MyReducer extends TableReducer<Text, NullWritable, NullWritable>{
//列簇
String family[] = { "basicinfo","extrainfo"};
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
// zhangfenglun,M,20,13522334455,[email protected],23521472 字段
for(NullWritable value:values){
String fields[]=key.toString().split(",");
//以名称作为rowkey
Put put=new Put(fields[0].getBytes());
put.addColumn(fields[0].getBytes(),"sex".getBytes(),fields[1].getBytes());
put.addColumn(fields[0].getBytes(),"age".getBytes(),fields[2].getBytes());
put.addColumn(fields[1].getBytes(),"phone".getBytes(),fields[3].getBytes());
put.addColumn(fields[1].getBytes(),"email".getBytes(),fields[4].getBytes());
put.addColumn(fields[1].getBytes(),"qq".getBytes(),fields[5].getBytes());
context.write(value, put);
}
}
}
}2. mysql导入到HBASE
#使用sqoop从MySQL导入HBASE
sqoop import --connect jdbc:mysql://hadoop01:3306/test #MySQL的入口
--username hadoop #登录MySQL的用户名
--password root #登录MySQL的密码
--table book #插入的到MySQL的表
--hbase-table book #HBASE的表名
--column-family info #HBASE表中的列簇
--hbase-row-key bid #mysql中的哪一个列为rowkey
#ps:这里由于版本不兼容的问题,所以,这里的HBASE中插入的表必须提前创建,并且不能使用:--hbase-create-table ,这个语句
3.HBASE整合hive
原理:Hive与HBASE利用两者本身对外的API来实现整合,主要靠的是HBaseStorageHandler 进 行通信,利用 HBaseStorageHandler,Hive 可以获取到 Hive 表对应的 HBase 表名,列簇以及 列,InputFormat 和 OutputFormat 类,创建和删除 HBase 表等。
Hive 访问 HBase 中表数据,实质上是通过 MapReduce 读取 HBase 表数据,其实现是在 MR 中,使用 HiveHBaseTableInputFormat 完成对 HBase 表的切分,获取 RecordReader 对象来读 取数据。
对HBASE表的切分原则:一个region切分成一个split,即表中有多少个region,MapReduce就有多少个map task。
读取HBASE表数据都是通过scanner,对表进行全表扫描,如果有过滤条件,则转化为filter,当过滤条件为rowkey时,则转化为rowkey的过滤。
具体操作:
#指定 hbase 所使用的 zookeeper 集群的地址:默认端口是 2181,可以不写:
hive>set hbase.zookeeper.quorum=hadoop02:2181,hadoop03:2181,hadoop04:2181;
#指定 hbase 在 zookeeper 中使用的根目录
hive>set zookeeper.znode.parent=/hbase;
#创建基于 HBase 表的 hive 表
hive>create external table mingxing(rowkey string, base_info map, extra_info map) row format delimited fields terminated by ‘ ‘
>stored by ‘org.apache.hadoop.hive.hbase.HBaseStorageHandler‘
>with serdeproperties ("hbase.columns.mapping" = ":key,base_info:,extra_info:")
>tblproperties("hbase.table.name"="mingxing","hbase.mapred.output.outputtable"="mingxing");
#ps:org.apache.hadoop.hive.hbase.HBaseStorageHandler:处理 hive 到 hbase 转换关系的处理器
#ps:hbase.columns.mapping:定义 hbase 的列簇和列到 hive 的映射关系
#ps:hbase.table.name:hbase 表名虽然hive整合了hbase,但是实际的数据还是存储在hbase上,hive相应的表目录下对应的文件为空,但是每次hbase中有数据添加时,hive在执行这张表查询的时候,也会更新相应的字段。
以上是关于hbase的典型场景的主要内容,如果未能解决你的问题,请参考以下文章