NN元数据工作机制
Posted theladyflower
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NN元数据工作机制相关的知识,希望对你有一定的参考价值。
HDFS的实现思路:
1.HDFS通过分布式集群来存储文件,为客户端提供便捷的访问方式
2.文件存储到HDFS集群去的时候,被切分为block
3.HDFS存放在若干datanode节点 上
4.HDFS文件系统与真实的block之间有映射关系,由于NameNode管理
5.每个block在集群中会存储多个副本,好处:提高数据的可靠性,吞吐量
HDFS架构:
NameNode
DataNode
SecondaryNameNode (次要的)
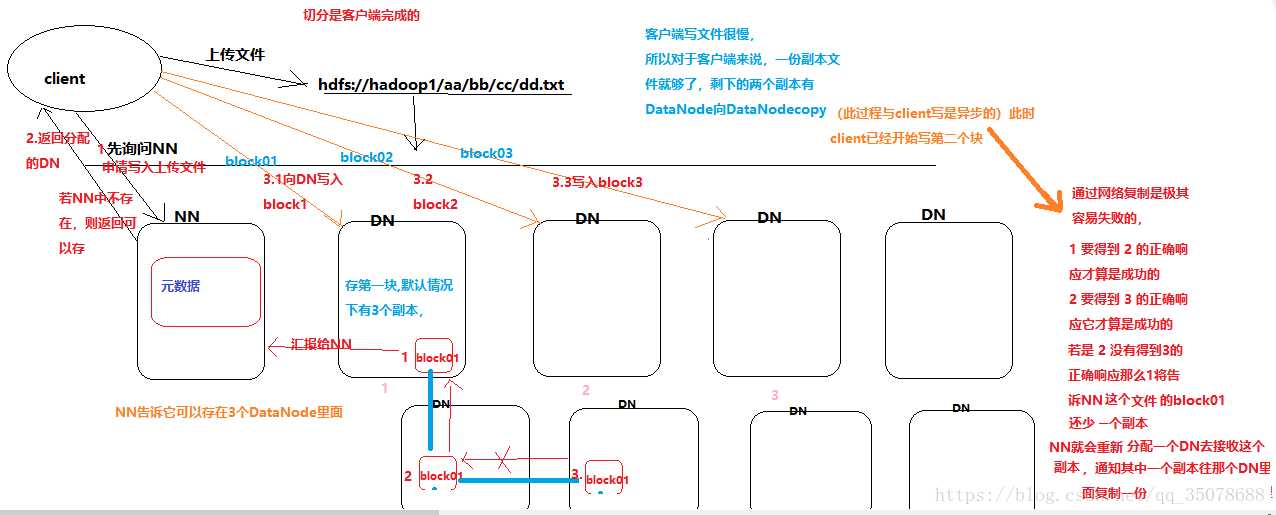
问题:
1)若将元数据存在文件里面,那么就属于文件的随机访问,要查询一条元数据,得定位到哪一行,速度很慢,
2)若放到内存里面,万一宕机了怎么办?断电了呢?那么元数据就丢失了。
3)定期flush到磁盘文件,可是内存很大,很容易丢失
解决:1.
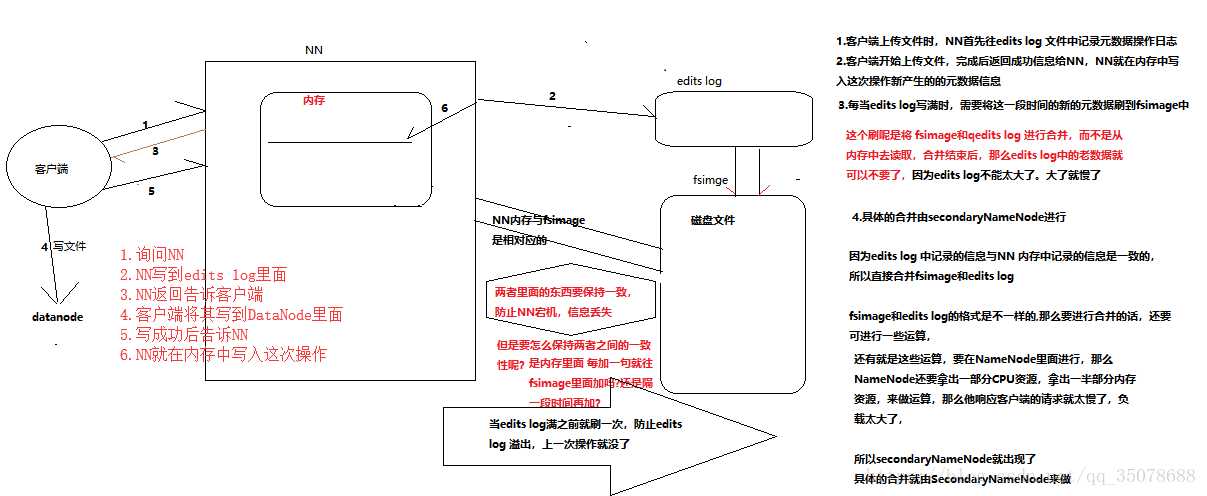
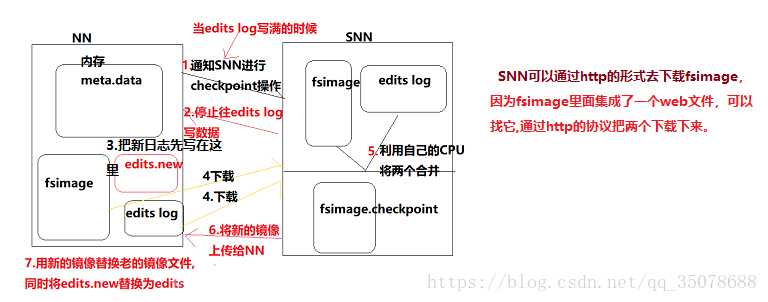
2..NN + SN
作者:哪有天生的学霸,一切都是厚积薄发
来源:CSDN
原文:https://blog.csdn.net/qq_35078688/article/details/82987275
版权声明:本文为博主原创文章,转载请附上博文链接!
以上是关于NN元数据工作机制的主要内容,如果未能解决你的问题,请参考以下文章
HDFSNameNode 和 SecondaryNameNode 详解