机器学习算法汇总大梳理
Posted simpledi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习算法汇总大梳理相关的知识,希望对你有一定的参考价值。
多分类问题优先选择SVM,随机森林,其次是逻辑回归。
朴素贝叶斯和线性回归都是比较简单的模型,对于数据的要求比较高,功能不是特别强大。
1、决策树
不需要对数据做任何预处理,
2、随机森林
3、数据预处理与特征工程
(1)数据预处理:只需要X
- 数据无量钢化:标准化(转化为正态分布)、归一化(不改变数据原始分布,改变范围,默认(0-1))
- 处理缺失值:可用均值、众数、中位数、其他字符型或者数值型值填补
- 处理分类型变量:使用编码处理字符型变量。一般对于有序变量或者有距变量可使用普通的编码方式;对于名义变量采用独热编码方式将其转化为哑变量。
- 处理连续型变量:二值化、分箱。
另外还有去除重复值、处理异常值,样本不均衡等问题。
预处理中大部分功能都是为了使数据满足模型的需求,但是数据的无量纲化有着特殊的功能:在梯度和矩阵为核心的算法中,譬如逻辑回归,支持向量机,神经网络,无量纲化可以加快求解速度;而在距离类模型,譬如K近邻,K-Means聚类中,无量纲化可以帮我们提升模型精度,避免某一个取值范围特别大的特征对距离计算造成影响。
(2)特征选择:
- 方差过滤:去除区分度较低的特征。(只需要X)
- 相关性检验:去除与标签y相关性较低的特征,卡方检验、F检验、互信息法。(需要X和Y)
- Embedded嵌入法:利用 SelectFromModel和真正所需模型,以及X,Y
- Wrapper包装法:利用RFE,结合任意一种模型,以及X,Y
(3)一般我们是先分训练集和测试集,再进行数据预处理或者特征选择。
- 处理训练集时:只用训练集,因为我们不能够把测试集数据的任何信息带入到模型中,如果在填补缺失值的时候用所有数据的均值来进行填补,就相当于把测试集的数据带入到了模型中。
- 处理测试集时:只用训练集,有些时候测试集非常小甚至只有一条数据,这时候就无法计算它的统计量信息,我们可以用训练集fit模型,然后用该模型处理测试集。或者对于fit模型不需要Y数据的数据预处理和特征选择方法也可以使用全数据fit,然后应用于测试数据。
4、降维算法
(1)PCA是一种无监督学习算法,是将较多维的特征映射到较少维空间的方法。
(2)PCA通过特征值分解得到对角矩阵∑(对角元素是方差)来找出空间V,PCA使用方差作为信息量的衡量指标。
(3)SVD使用奇异值分解得到对角矩阵∑(对角元素是奇异值)来找出空间V,SVD中用奇异值来衡量特征上的信息量的指标
(4)无论是PCA和SVD都需要遍历所有的特征和样本来计算信息量指标,因此计算缓慢。
(5) sklearn将降维流程拆成了两部分:一部分是计算特征空间V,由奇异值分解完成,另一部分是映射数据和求解新特征矩阵(衡量指标是方差),由主成分分析完成,实现了用SVD的性质减少计算量,却让信息量的评估指标是方差。
5、逻辑回归(基于概率,最大似然,梯度下降求参数)
(1)逻辑回归是基于概率的模型,对于每一个样本有函数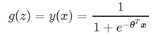 该函数是对样本的预测结果。原理为:通过引入联系函数(Sigmoid函数)将线性回归的结果映射至(0,1)之间,且当g(z)接近0时样本的标签为类别0,当g(z)接近1时样本的标签为类别1,这样就得到了一个分类模型。且逻辑回归可以不仅可以得到分类结果还可以计算得分,可用于制作评分卡。
该函数是对样本的预测结果。原理为:通过引入联系函数(Sigmoid函数)将线性回归的结果映射至(0,1)之间,且当g(z)接近0时样本的标签为类别0,当g(z)接近1时样本的标签为类别1,这样就得到了一个分类模型。且逻辑回归可以不仅可以得到分类结果还可以计算得分,可用于制作评分卡。
(2)利用二元逻辑回归的一般形式Yθ(x),使用最大似然法(即是使得所有样本都预测正确)和推倒出逻辑回归的损失函数: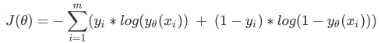
(3)我们只要追求损失函数的最小值,就能让模型在训练数据上的拟合效果最好,预测损失最低。用梯度下降法求损失函数的最小值(小球的例子),对其中的参数θ求导得到梯度向量: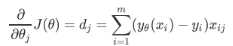
梯度向量的反方向即是损失函数下降最快的方向,有关于θ的迭代函数: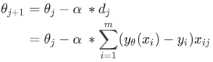
其中α是步长,α*d代表自变量θ每次迭代移动的距离,-d的方向代表其移 动的方向。迭代得到使得损失函数最小的θ就是要求的参数。
(4)正则化:虽然逻辑回归和线性回归是天生欠拟合的模型,但我们还是需要控制过拟合的技术来帮助我们调整模型,对逻辑回归中过拟合的控制,通过正则化来实现。
(5)逻辑回归数学原理理解较为复杂,且它原理中的类概率并不是真正意义上的概率,但是由于计算速度快,对线性关系的拟合非常好,所以还是受到了青睐。
6、聚类算法—Kmeans(基于距离,内聚外远,迭代)
(1)对于无监督学习算法,我们无法通过真实值与预测值的比较来衡量模型的好坏。因为无监督学习本身是对数据的一种探索,我们需要根据实际的业务需求来选取聚类结果。
(2) Inertia,簇内距离平方和。是衡量聚类的一个指标,我们可以近似将其看作损失函数。这是因为对于求参的模型(例如逻辑回归-梯度下降、线性回归-最小二乘(or梯度下降),SVM-梯度下降等)我们可以通过最小化损失函数的方法来得到好的模型参数,而在KMeans中,我们在一个固定的簇数K下,最小化总体平方和来求解最佳质心,并基于质心的存在去进行聚类。(虽然在聚类迭代的过程没有计算inertia,但是在质心不断变化不断迭代的过程中,总体平方和是越来越小的,我们可以使用数学来证明,当整体平方和最小的时候,质心就不再发生变化了)
(3)但是inertia作为聚类的衡量指标但是其有许多缺点,例如没有范围,会随着k的增大而减小(不是客观的衡量指标)、对于数据分布有假设等缺点,所以引入了轮廓系数(范围-1~1之间)作为Kmeans的衡量指标。
7、SVM(基于距离,最大化边际)
(1) 支持向量机原理:
用一个n-1维的超平面将数据分隔开,这个超平面叫做决策边界,所有的样本点不仅分布在超平面两侧,而且分布在两侧的虚线外侧,两个虚线超平面之间的距离叫做边际。
决策边界: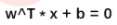
分类函数: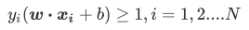
损失函数和约束条件: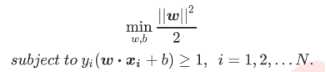
为了求得在约束条件下,损失函数得到最小值时候的w和b,我们采用拉格朗日乘子法(在满足KKT条件的前提下)和对偶函数将 损失函数和约束条件转化为: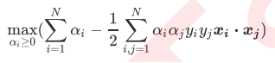
此时新的决策边界: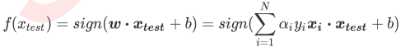
具体方法为:对拉格朗日函数的w和b分为求导,得到结果带入对偶函数。
然后对目标函数利用梯度下降法或者SMO或者二次规划等方法求得α,结合上面的式子也可以得到w和b。
(2) SVM四种核函数选择:
通过实践进行选择,直接上各种核跑数据,看得分。
1. 线性核,尤其是多项式核函数在高次项时计算非常缓慢(SVM是基于距离的)
2. rbf和多项式核函数都不擅长处理量纲不统一的数据集
这两点都可以通过数据标准化来解决,(无量纲化数据既可以提升有关梯度下降类模型的求解速度,又可以提升有关距离类模型的精度)
(3)SVM调参
|
核函数 |
可调参数 |
调参方法 |
|
Liner |
无 |
无 |
|
Rbf |
Gamma |
学习曲线 |
|
Sigmoid |
Gamma、coef0 |
网格搜索 |
|
Poly |
Gamma、coef0、degree |
网格搜索 |
(4)SVM的软间隔
较大的边际使得模型有更好的泛化性。但是较大的边际又会让部分训练样本出现分类错误,因此引入软间隔,在保证较大边际的前提下,允许部分训练样本出现错分,但是不能错的离谱,让决策边界能够忍受一部分的训练误差。即平衡“最大化边际”(保证较大泛化误差)和“最大化模型准确率”(保证较小训练误差)两者。
C就是调节软间隔程度的参数:C越大,尽量正确分类样本;C越小,尽量最大化边界。
在软间隔中支持向量是αi(yi(wTxi+b)-1+ξi)=0 成立且αi>0(即αi≠0)的样本点(那些αi=0的点就是被正确分类且在yi(w*xi+b)=1内侧的点,也就不是支持向量,对决策超平面没有任何影响),这些点由于各自αi和ζi的不同,可以位于在间隔边界((yi(w*xi+b)=1))上、间隔边界与决策超平面之间、或者在超平面误分的一侧,这些支持向量共同决定决策超平面的位置。
(5) 不平衡样本的评估指标
SVM处理样本不均衡情况比较擅长,因为SVC的参数class_weight和fit接口的参数sample_weight都比较容易调参。对于不平衡样本就不能简单的用score来评价模型的好坏了,因为如果少数样本非常少,那即是模型把所有样本都判断为多数类,模型的分数仍然可以很高,但是存在样本不平衡的场景中,判断错误少数类的代价一般是比较高的。因此引入了很多种类的模型例如:cm,accuracy,precision,recall,F1 score,specificity,FPR,ROC,AUC等。对于逻辑回归,SVM等有置信度这一概念的模型,还可以利用ROC面积求解最佳阈值,微调模型,使其具有更高的recall和更低的FPR。
8、线性回归
(1)手推线性回归使用最小二乘法求解w,但是这涉及到矩阵求逆,运算量大,大多数还是使用梯度下降的方法迭代求w。
(2)对于回归类模型,由于其不像分类型模型那样,只有预测正确预测错误这一评估方式;对于回归类模型我们想让其更好的拟合原始数据,即预测值与真实值相差越少,并且模型能够很好的描绘数据的原始分布以及趋势。
1、是否预测了正确的数值。使用RSS-残差平方和可以衡量对于所有训练样本,预测值与真实值相差多少,但是由于其没有界限,我们没办法根据RSS值直观判断模型好坏,故引入MSE-均方误差,将RSS平分至每一个样本,这样可以将其与样本最大值和最小值分别 进行比较,评判模型好坏。可以使用metrics模块中的MES模块,或者设置cross_val_score中的“neg_mean_squared_error”参数得到MSE分数。
2、是否拟合的足够的信息(数据分布)。使用或者EVS-可解释性方差分数(explained_varience_score)来衡量模型没有已经捕捉到的信息,有三种方式来调用,一种是直接从metrics中导入r2_score,输入真实值和预测值后打分。第二种是直接从线性回归 LinearRegression的接口score来进行调用。第三种是在交叉验证中,输入"r2"来调用。EVS有两种调用方法,可以从metrics中导入explained_varience_score调用,也可以在交叉验证中输入”explained_variance“来调用。
3、其实可以为一个负数,此时说明数据预处理过程或者建模过程伤害了数据本身或者模型效果非常不好需要更换模型。
9、朴素贝叶斯
(1)因为朴素贝叶斯是基于概率的算法,因此需要的样本量较小,因为一个较小的样本基本就可以反映整个数据集的情况。
(2)朴素贝叶斯在计算的时候并不是既计算全概率公式,又计算类概率公式,而是只计算类概率公式的值,因为对于不同的后验概率来说,其公式中的分母的值都是全概率公式,是一样的,只要比较不同类概率的大小就是后验概率的大小了,而且各个类概率之和就是全概率。
(3)朴素贝叶斯是假设各个特征之间是相互独立的,因此计算类概率的时候是各个特征分别计算的。
以上是关于机器学习算法汇总大梳理的主要内容,如果未能解决你的问题,请参考以下文章
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
华为云技术分享Python成长之路机器学习:10+分类算法汇总学习