对String类型的认识以及编译器优化
Posted archer-fang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对String类型的认识以及编译器优化相关的知识,希望对你有一定的参考价值。
Java中String不是基本类型,但是有些时候和基本类型差不多,如String b = "tao" ; 可以对变量直接赋值,而不用 new 一个对象(当然也可以用 new)。
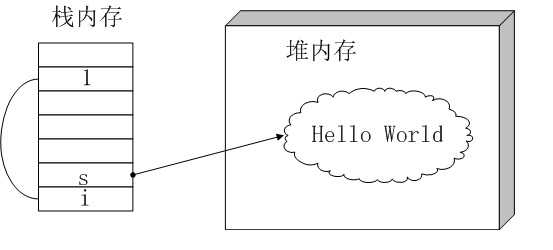
Java中的变量和基本类型的值存放于栈内存,而new出来的对象本身存放于堆内存,指向对象的引用还是存放在栈内存。例如如下的代码:
int i=1;
String s = new String( "Hello World" );
变量i和s以及1存放在栈内存,而s指向的对象”Hello World”存放于堆内存。
栈内存的一个特点是数据共享,这样设计是为了减小内存消耗,前面定义了i=1,i和1都在栈内存内,如果再定义一个j=1,此时将j放入栈内存,然后查找栈内存中是否有1,如果有则j指向1。如果再给j赋值2,则在栈内存中查找是否有2,如果没有就在栈内存中放一个2,然后j指向2。
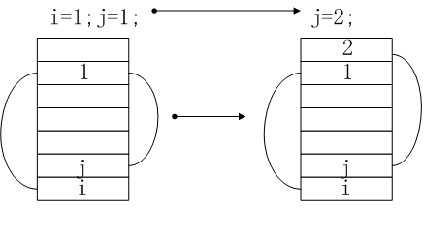
如果j++,这时指向的变量并不会改变,而是在栈内寻找新的常量(比原来的常量大1),如果栈内存有则指向它,如果没有就在栈内存中加入此常量并将j指向它。
这种基本类型之间比较大小和我们逻辑上判断大小是一致的。
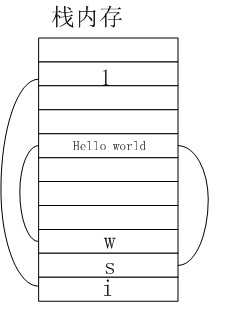
如定义i和j是都赋值1,则i==j结果为true。==用于判断两个变量指向的地址是否一样。i==j就是判断i指向的1和j指向的1是同一个吗?当然是了。对于直接赋值的字符串常量(如String s=“Hello World”;中的Hello World)也是存放在栈内存中,而new出来的字符串对象(即String对象)是存放在堆内存中。如果定义String s=“Hello World”和String w=“Hello World”,s==w吗?肯定是true,因为他们指向的是同一个Hello World。
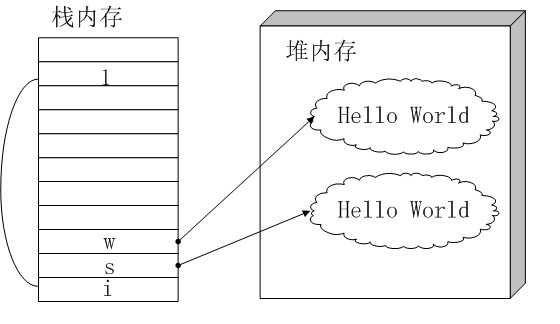
堆内存没有数据共享的特点,前面定义的String s = new String( "Hello World" );后,变量s在栈内存内,Hello World 这个String对象在堆内存内。如果定义String w = new String( "Hello World" );,则会在堆内存创建一个新的String对象,变量w存放在栈内存,w指向这个新的String对象。堆内存中不同对象(指同一类型的不同对象)的比较如果用==则结果肯定都是false,比如s==w?当然不等,s和w指向堆内存中不同的String对象。如果判断两个String对象相等呢?用equals方法。
有如下一段代码,请选择其运行结果()
public class StringDemo{ private static final String MESSAGE="taobao"; public static void main(String [] args) { String a ="tao"+"bao"; String b="tao"; String c="bao"; System.out.println(a==MESSAGE); System.out.println((b+c)==MESSAGE); } }
MESSAGE 成员变量及其指向的字符串常量肯定都是在栈内存里的,变量 a 运算完也是指向一个字符串“ taobao ”啊?是不是同一个呢?这涉及到编译器优化问题。对于字符串常量的相加,在编译时直接将字符串合并,而不是等到运行时再合并。也就是说
String a = "tao" + "bao" ;和String a = "taobao" ;编译出的字节码是一样的。所以等到运行时,根据上面说的栈内存是数据共享原则,a和MESSAGE指向的是同一个字符串。而对于后面的(b+c)又是什么情况呢?b+c只能等到运行时才能判定是什么字符串,编译器不会优化。运行时b+c计算出来的"taobao"和栈内存里已经有的"taobao"是一个吗?不是。b+c计算出来的"taobao"应该是放在堆内存中的String对象。这可以通过System. out .println( (b+c)== MESSAGE );的结果为false来证明这一点。Java对String的相加是通过StringBuffer实现的,先构造一个StringBuffer里面存放”tao”,然后调用append()方法追加”bao”,然后将值为”taobao”的StringBuffer转化成String对象。StringBuffer对象在堆内存中,那转换成的String对象理所应当的也是在堆内存中。
下面改造一下这个语句System. out .println( (b+c).intern()== MESSAGE );结果是true, intern() 方法会先检查 String 池 ( 或者说成栈内存 ) 中是否存在相同的字符串常量,如果有就返回。所以 intern()返回的就是MESSAGE指向的"taobao"。
再把变量b和c的定义改一下,
final String b = "tao" ;
final String c = "bao" ;
System. out .println( (b+c)== MESSAGE );
现在b和c不可能再次赋值了,所以编译器将b+c编译成了”taobao”。因此,这时的结果是true。
在字符串相加中,只要有一个是非final类型的变量,编译器就不会优化,因为这样的变量可能发生改变,所以编译器不可能将这样的变量替换成常量。例如将变量b的final去掉,结果又变成了false。这也就意味着会用到StringBuffer对象,计算的结果在堆内存中。
以上是关于对String类型的认识以及编译器优化的主要内容,如果未能解决你的问题,请参考以下文章