强化学习---TRPO/DPPO/PPO/PPO2
Posted zle1992
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习---TRPO/DPPO/PPO/PPO2相关的知识,希望对你有一定的参考价值。
时间线:
OpenAI 发表的 Trust Region Policy Optimization,
Google DeepMind 看过 OpenAI 关于 TRPO后, 2017年7月7号,抢在 OpenAI 前面 把 Distributed PPO给先发布了.
OpenAI 还是在 2017年7月20号 发表了一份拿得出手的 PPO 论文 。(ppo+ppo2)
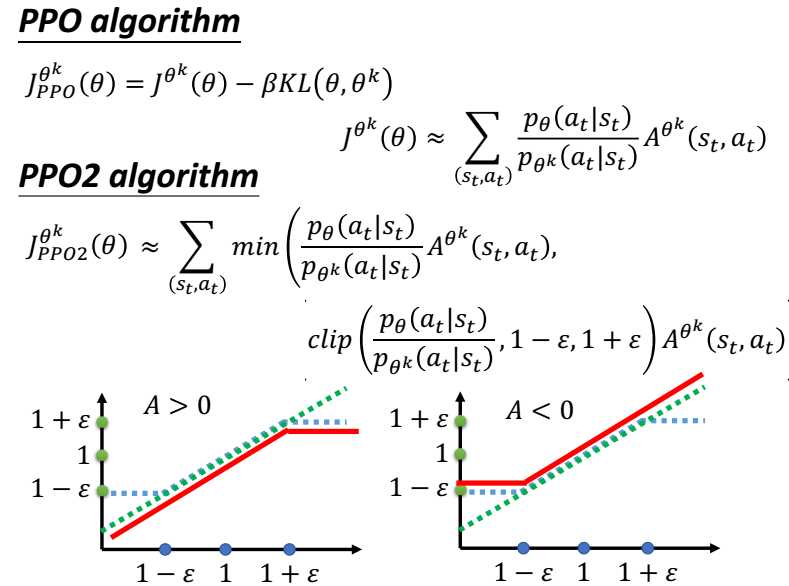
Proximal Policy Optimization
PPO是off-policy的方法。
跟环境互动的agent与用来学习得agent 不是同一个agent,可以理解为PPO 是一套 Actor-Critic 结构, Actor 想最大化 J_PPO, Critic 想最小化 L_BL.

利用importance sampling


通过KL散度加一个惩罚,使梯度更新的时候幅度不要太大。

总的来说 PPO 是一套 Actor-Critic 结构, Actor 想最大化 J_PPO, Critic 想最小化 L_BL. Critic 的 loss 好说, 就是减小 TD error. 而 Actor 的就是在 old Policy 上根据 Advantage (TD error) 修改 new Policy, advantage 大的时候, 修改幅度大, 让 new Policy 更可能发生. 而且他们附加了一个 KL Penalty (惩罚项, 不懂的同学搜一下 KL divergence), 简单来说, 如果 new Policy 和 old Policy 差太多, 那 KL divergence 也越大, 我们不希望 new Policy 比 old Policy 差太多, 如果会差太多, 就相当于用了一个大的 Learning rate, 这样是不好的, 难收敛.

Trust Region Policy Optimization
ppo是吧惩罚项放在了目标函数中,而TRPO 是以 constrain的形式。不好求解。

PPO2
看图,横坐标是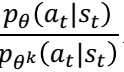 ,当A>0时候,奖励是正的,更新的幅度越大越好,但是为了
,当A>0时候,奖励是正的,更新的幅度越大越好,但是为了
加入惩罚,所以更新的幅度在横坐标大于 时候,就不增加同一个幅度,所以是一条横线,不会无限制增大。
时候,就不增加同一个幅度,所以是一条横线,不会无限制增大。
同理,当A<0时候,横坐标是更新的幅度,因为奖励是负数,正常应该 更新是越小越好,但是不能无限小啊,所以假如
惩罚就是不能无限小。
Distributed Proximal Policy Optimization
摘自:https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/6-4-DPPO/
Google DeepMind 提出来了一套和 A3C 类似的并行 PPO 算法. paper
取而代之, 我觉得如果采用 OpenAI 的思路, 用他那个 “简陋” 伪代码, 但是弄成并行计算倒是好弄点. 所以我就结合了 DeepMind 和 OpenAI, 取他们的精华, 写下了这份 DPPO 的代码.
总结一下我是怎么写的.
- 用 OpenAI 提出的
Clipped Surrogate Objective - 使用多个线程 (workers) 平行在不同的环境中收集数据
- workers 共享一个 Global PPO
- workers 不会自己算 PPO 的 gradients, 不会像 A3C 那样推送 Gradients 给 Global net
- workers 只推送自己采集的数据给 Global PPO
- Global PPO 拿到多个 workers 一定批量的数据后进行更新 (更新时 worker 停止采集)
- 更新完后, workers 用最新的 Policy 采集数据
以上是关于强化学习---TRPO/DPPO/PPO/PPO2的主要内容,如果未能解决你的问题,请参考以下文章