ElasticSearch容错机制
Posted ql211lin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch容错机制相关的知识,希望对你有一定的参考价值。
一、关于横向扩容
PUT /test_index { "settings" : { "number_of_shards" : 3, "number_of_replicas" : 1 } }
(1)primary&replica自动负载均衡,6个shard,3 primary,3 replica
(2)每个node有更少的shard,IO/CPU/Memory资源给每个shard分配更多,每个shard性能更好
(3)扩容的极限,6个shard(3 primary,3 replica),最多扩容到6台机器,每个shard可以占用单台服务器的所有资源,性能最好
(4)超出扩容极限,动态修改replica数量,9个shard(3primary,6 replica),扩容到9台机器,比3台机器时,拥有3倍的读吞吐量
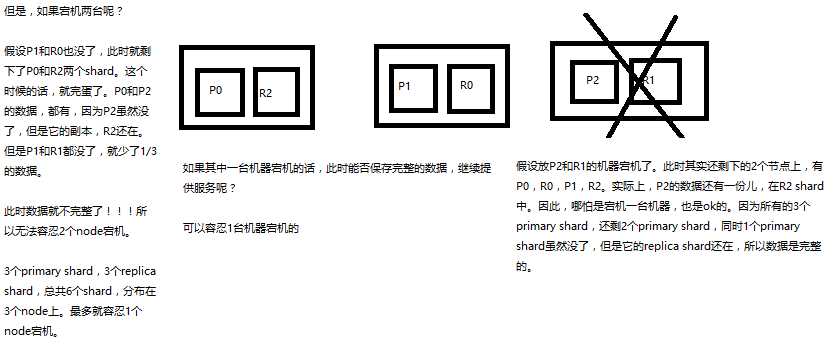
(5)3台机器下,9个shard(3 primary,6 replica),资源更少,但是容错性更好,最多容纳2台机器宕机,6个shard只能容纳1台机器宕机
在3台机器下,6个shard的只能容纳1台机器宕机容错性分析:
二、关于master节点
1.master节点不会承载所有的请求,所以不会是一个单点瓶颈
2.master节点管理es集群的元数据:比如说索引的创建和删除,维护索引的元数据,节点的增加和移除,维护集群的元数据
3.默认情况下,会自动选择出一台节点,作为master节点
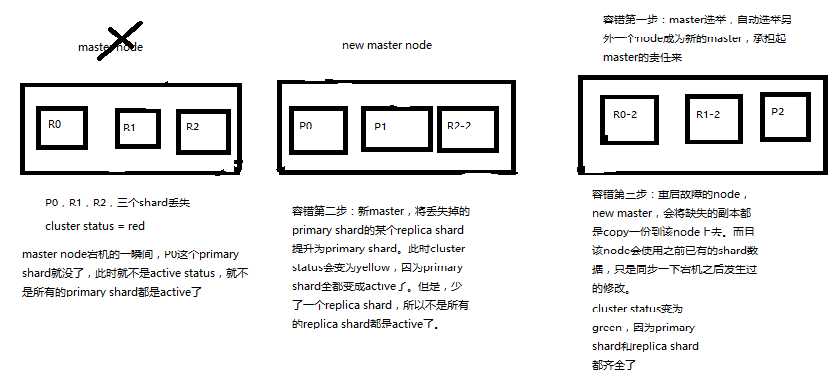
容错性分析:
三、关于纵向扩容
扩容方案:重新购置两台性能更加强大,替换原先旧的2台服务器,但是,服务器的性能越强,成本将会是成倍增加,此方案不推荐,一般用横向扩容。
以上是关于ElasticSearch容错机制的主要内容,如果未能解决你的问题,请参考以下文章