Hashtable介绍
Posted jameszheng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hashtable介绍相关的知识,希望对你有一定的参考价值。
前面我们介绍了HashMap的结构和原理,这里介绍一个跟它类似的Hashtable。
和HashMap一样,Hashtable 也是一个散列表,它存储的内容是键值对(key-value)映射。
Hashtable 继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口。
Hashtable 的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。此外,Hashtable中的映射不是有序的。
Hashtable 的实例有两个参数影响其性能:初始容量 和 加载因子。容量 是哈希表中桶 的数量,初始容量 就是哈希表创建时的容量。注意,哈希表的状态为 open:在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。加载因子 是对哈希表在其容量自动增加之前可以达到多满的一个尺度。初始容量和加载因子这两个参数只是对该实现的提示。关于何时以及是否调用 rehash 方法的具体细节则依赖于该实现。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查找某个条目的时间。
Hashtable的结构图:
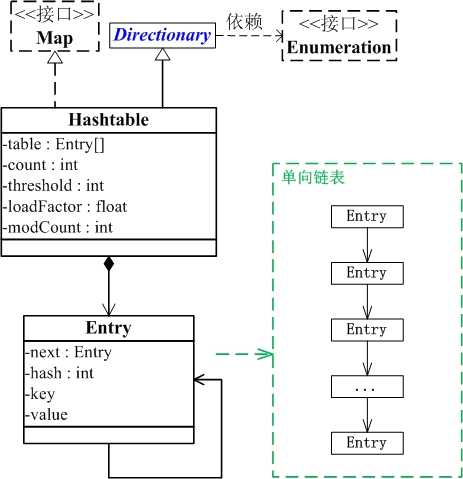
和HashMap类似,Hashtable里面是Entry[],每个entry都是一个链表,只是HashMap会多一个二叉树的结构。
构造方法:
1 public Hashtable(int initialCapacity, float loadFactor) { 2 if (initialCapacity < 0) 3 throw new IllegalArgumentException("Illegal Capacity: "+ 4 initialCapacity); 5 if (loadFactor <= 0 || Float.isNaN(loadFactor)) 6 throw new IllegalArgumentException("Illegal Load: "+loadFactor); 7 8 if (initialCapacity==0) 9 initialCapacity = 1; 10 this.loadFactor = loadFactor; 11 table = new Entry<?,?>[initialCapacity]; 12 threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1); 13 } 14 15 16 public Hashtable(int initialCapacity) { 17 this(initialCapacity, 0.75f); 18 } 19 20 21 public Hashtable() { 22 this(11, 0.75f); 23 } 24 25 26 public Hashtable(Map<? extends K, ? extends V> t) { 27 this(Math.max(2*t.size(), 11), 0.75f); 28 putAll(t); 29 }
其他的方法源码就不一一列举出来了,都是带同步的。
HashMap与Hashtable的比较:
相同点:
HashMap和Hashtable都是存储“键值对(key-value)”的散列表,而且都是采用拉链法实现的。
存储的思想都是:通过table数组存储,数组的每一个元素都是一个Entry;而一个Entry就是一个单向链表,Entry链表中的每一个节点就保存了key-value键值对数据。
添加key-value键值对:首先,根据key值计算出哈希值,再计算出数组索引(即,该key-value在table中的索引)。然后,根据数组索引找到Entry(即,单向链表),再遍历单向链表,将key和链表中的每一个节点的key进行对比。若key已经存在Entry链表中,则用该value值取代旧的value值;若key不存在Entry链表中,则新建一个key-value节点,并将该节点插入Entry链表的表头位置。
删除key-value键值对:删除键值对,相比于“添加键值对”来说,简单很多。首先,还是根据key计算出哈希值,再计算出数组索引(即,该key-value在table中的索引)。然后,根据索引找出Entry(即,单向链表)。若节点key-value存在与链表Entry中,则删除链表中的节点即可。
不同点:
1 继承和实现方式不同
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
Hashtable 继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口。
2 线程安全不同
Hashtable的几乎所有函数都是同步的,即它是线程安全的,支持多线程。
而HashMap的函数则是非同步的,它不是线程安全的。
3 对null值的处理不同
HashMap的key、value都可以为null。
Hashtable的key、value都不可以为null。
4 遍历方式不同
HashMap只支持Iterator(迭代器)遍历。此种迭代方式,HashMap是“从前向后”的遍历数组;Hashtabl是“从后往前”的遍历数组;
而Hashtable支持Iterator(迭代器)和Enumeration(枚举器)两种方式遍历。
5 添加元素时的hash值算法不同
HashMap添加元素时,是使用自定义的哈希算法。
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
Hashtable没有自定义哈希算法,而直接采用的key的hashCode()。
public synchronized V put(K key, V value) { // Make sure the value is not null if (value == null) { throw new NullPointerException(); } // Makes sure the key is not already in the hashtable. Entry<?,?> tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; @SuppressWarnings("unchecked") Entry<K,V> entry = (Entry<K,V>)tab[index]; for(; entry != null ; entry = entry.next) { if ((entry.hash == hash) && entry.key.equals(key)) { V old = entry.value; entry.value = value; return old; } } addEntry(hash, key, value, index); return null; }
6 容量的初始值和增加方式不一样
HashMap默认的“加载因子”是0.75,默认的容量大小是16;增加容量时,每次将容量变为“原始容量x2”。
Hashtable默认的“加载因子”是0.75,默认的容量大小是11;增加容量时,每次将容量变为“原始容量x2 + 1”。
Hashtable就介绍到这里,后面会介绍ConcurrentHashMap。
以上是关于Hashtable介绍的主要内容,如果未能解决你的问题,请参考以下文章