对PBFT算法的理解
Posted gexin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对PBFT算法的理解相关的知识,希望对你有一定的参考价值。
PBFT论文断断续续读了几遍,每次读或多或少都会有新的理解,结合最近的项目代码,对于共识的原理有了更清晰的认识。虽然之前写过一篇整理PBFT论文的博客,但是当时只是知道了怎么做,却不理解为什么。现在整理下思路,写一篇关于PBFT的理解。
1. 前提假定
1.1 同步模型
在分布式系统中谈论共识,首先需要明确系统同步模型是synchrony,asynchrony还是partial synchrony?
- synchrony: 节点所发出的消息,在一个确定的时间内,肯定会到达目标节点;
- asynchrony: 节点所发出的消息,不能确定一定会到达目标节点;
- partial synchrony: 节点发出的消息,虽然会有延迟,但是最终会到达目标节点。
synchrony是十分理想的情况,如果假设分布式系统是一个同步系统,那么共识算法的设计可以简化很多,在同步系统中只要超时没收到消息就可以认为节点除了问题。asynchrony是更为贴近实际的模型,但是根据FLP Impossibility原理,在asynchrony假定下,共识算法不可能同时满足safety和liveness。为了设计能够符合实际场景的共识算法,目前的BFT类共识算法多是基于partial synchrony假定,这在PBFT论文中被称为"weak synchrony"。
PBFT假设系统是异步的,节点通过网络连接,消息会被延迟,但是不会被无限延迟。
1.2 容错类型
PBFT假定错误可以是拜占庭类型的,也就是说可以使任意类型的错误,比如节点作恶、说谎等。这有别于crash-down类型的错误,raft、paxos这类共识算法只能允许crash-down类型错误,节点只能crash而不能产生假消息。
| 错误类型 | 总节点数 |
|---|---|
| Byzantine fault | (3f+1) |
| Crash-down fault | (2f+1) |
对于拜占庭类错误,总节点数为n,假设系统可能存在f个拜占庭节点,假如需要根据节点发送过来的消息做判断。为了共识正常进行,在收到n-f个消息时,就应该进行处理,因为可能有f个节点根本不发送消息。现在我们根据收到的n-f个消息做判断,判断的原则至少f+1个相同结果。但是,在收到的n-f个消息中,不能确定其中没有错误节点过来的消息,其中也可能存在f个假消息。应该保证n-f-f > f,即n>3f。
系统模型
一组节点构成状态机复制系统,一个节点作为主节点(privary),其他节点作为备份节点(back-ups)。某个节点作为主节点时,这称为系统的一个view。当节点出了问题,就进行view更新,切换到下一个节点担任主节点。主节点更替不需要选举过程,而是采用round-robin方式。
[ privary = view % N ]
在系统的主节点接收client发来的请求,并产生pre-prepare消息,进入共识流程。
我们需要系统满足如下两个条件
+deterministic: 在一个给定状态上的操作,产生一样的执行结果
+ 每个节点都有一样的起始状态
要保证non-fault节点对于执行请求的全局顺序达成一致。
1.3 safety & liveness
- safety: 坏的事情不会发生,即共识系统不能产生错误的结果,比如一部分节点说yes,另一部分说no。在区块链的语义下,指的是不会分叉。
- liveness: 好的事情一定会发生,即系统一直有回应,在区块链的语义下,指的是共识会持续进行,不会卡住。假如一个区块链系统的共识卡在了某个高度,那么新的交易是没有回应的,也就是不满足liveness。
2. Normal process
正常状态下的共识流程可以用论文中的配图清晰表示,如下所示。
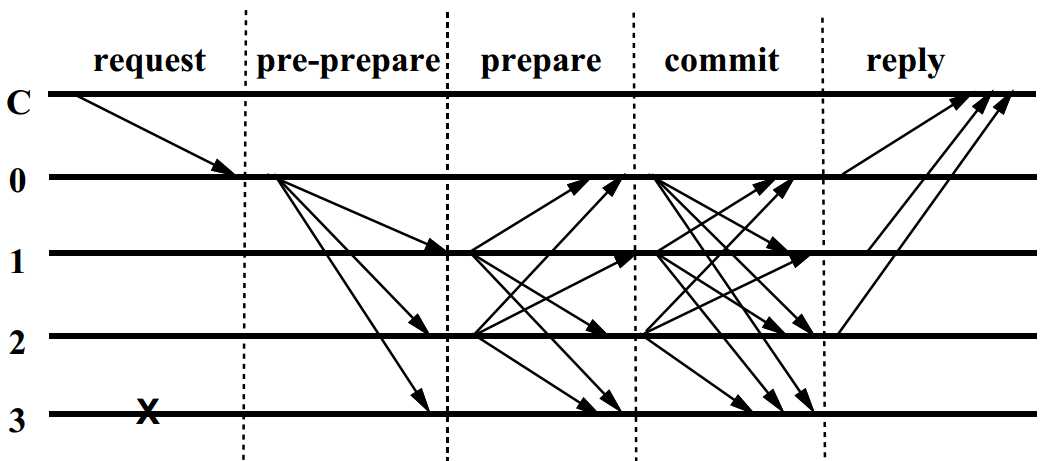
共识过程由三个阶段构成,pre-prepare阶段和prepare阶段确保了在同一个view下,正常节点对于消息m达成了全局一致的顺序,用(Order<v, m, n>)表示,在view = v下,正常节点都会对消息m,确认一个序号n。接下来的commit投票,再配合上viewchange的设计,实现了即使view切换,也可以保证对于m的全局一致顺序,即(Order<v+1, m, n>),视图切换到v+1, 依然会对消息m,确认序号n。
pre-prepare
privary节点收到请求m时,会做两件事,首先需要讲这个请求m广播给其他节点;然后是给请求m分配一个序号n,并广播给其他节点。广播之后会将消息保存在本地log中。
pre-prepare阶段的消息格式(<<PRE-PREPARE, v, n, d>_p, m>),其中v表示当前view编号,n表示给m分配的序号,d为m的哈希,以及m的原文。
其他节点收到pre-prepare消息时,会依次做如下几步操作:
- 签名验证
- 消息是本本节点所在view的消息
- 本节点在v视图下,还没有收到序号n的其他消息
- 收到的消息序号n,在当前接收窗口内(h, H)
- 以上几部都通过,则接受该消息,并广播prepare消息进入prepare阶段
一旦节点接受(langle langle PRE-PREPARE, v, n, d angle_p, m angle),则该节点进入到prepare阶段,然后节点广播prepare消息(langle PREPARE, v, n, d, i angle_i)。之后,节点将消息加入到本地的log中。
prepare
节点收到prepare消息时,会验签并检查是否是当前view的消息,同时检查消息序号n在当前的接收窗口内,验证通过则接受该消息,保存到本地log中。
当节点达成以下3点时,则表明节点达成了prepared状态,记为prepared(m,v,n,i)。
- 在log中存在消息m
- 在log中存在m的pre-prepare消息,pre-prepare(m,v,n)
- 在log中存在2f个来自其他节点的prepare消息,prepare(m,v,n,i)
至此,可以确保在view不发生切换的情况下,对于消息m有全局一致的顺序。
也就是说,在view不变的情况的下:
- (1) 一个正常节点i,不能对两个及以上的不同消息,达成相同序号n的prepared状态。即不能同时存在prepared(m,v,n,i)和prepared(m‘,v,n,i)
- (2) 两个正常节点i、j,必须对相同的消息m,达成相同序号n的prepared状态。prepared(m,v,n,i) && prepared(m,v,n,j)
简要的证明:
(1) 假如正常节点i, 对于消息m达成了prepared(m,v,n,i),同时存在一个m‘,也达成了prepared(m‘,v,n,i)。
首先对于prepared(m,v,n,i),肯定有2m+1个节点发出了<prepare,m,v,n>消息。
对于prepared(m‘,v,n,i),肯定也有2m+1个节点发出了<prepare,m‘,v,n>。
2*(2f+1) - (3f+1) = f+1
所以至少有f+1个节点,既发出了<prepare,m,v,n>,又发出了<prepare,m‘,v,n>,这明显是拜占庭行为。也就是说,至少有f+1个拜占庭节点,而这与容错条件相矛盾。
(2) 假如两个正常节点i、j,分别对不同的消息m、m‘,达成序号n的prepared状态,prepared(m,v,n,i)和prepared(m‘,v,n,j)
首先对于prepared(m,v,n,i),肯定有2m+1个节点发出了<prepare,m,v,n>消息。
对于prepared(m‘,v,n,j),肯定也有2m+1个节点发出了<prepare,m‘,v,n>。
2*(2f+1) - (3f+1) = f+1
所以至少有f+1个节点,既发出了<prepare,m,v,n>,又发出了<prepare,m‘,v,n>,这明显是拜占庭行为。也就是说,至少有f+1个拜占庭节点,而这与容错条件相矛盾。prepared状态是十分重要的,当涉及到view转换时,为了保证view切换前后的safety特性,需要将上一轮view的信息传递到新的view,而在pbft中就是将prepared状态信息传递到新的view。可以这么理解,新的view中需要在上一轮view的prepared信息基础上,继续进行共识。
在tendermin共识算法中,同样是采用与pbft类似的三个阶段(两轮投票),但是在round切换时,并没有传递prepared状态信息。为了保证safety特性,tendermint中新的轮次中,根据本地节点是否有锁定的信息来进行,而锁定的信息就是prepared状态。所以,tendermint也是在本节点上一轮prepared信息的基础上继续进行共识。
达成prepared状态以后,节点会广播commit消息(langle COMMIT, v, n, d, i angle_i).
commit
节点接收commit消息后,会像收到prepare消息一样进行几步验证已确定是否接受该消息。
当节点i,达成了prepared(m,v,n,i)状态,并且收到了(2f+1)个commit(v,n,d,i)消息,则该节点达成了commit-local(m,v,n,i)状态。
达成commit-local之后,节点对于消息m就有了一个全局一致的顺序,可以执行该消息并 reply to 客户端了。
commit-local状态说明有2f+1个节点达成了prepared状态.
3. garbage collect
由于实际的消息log不可能无限大,因此需要设定checkpoint,以实现过时消息的清除。
直观的做法就是,每隔一段时间,在序号(n%100 == 0)时,确认每个节点都已经执行完第n个消息了。这样就可以清除掉比n还要早的消息了。
在pbft论文中,这也是通过投票实现的,当一个节点执行完第n个消息后,就广播(langle CHECKPOINT, n, d, i angle) 消息。节点收集到(2f+1) checkpoint消息后,就产生一个本地的checkpoint,然后清除掉比n小的消息。然后将接收消息的窗口调整为(n, n+100).
4. viewchange
个人认为,viewchange是pbft中最为关键的设计,viewchange的设计保证了共识系统的safety和liveness特性。
当节点检测到超时时,会发送viewchange消息,进入viewchange流程,viewchange消息包含如下内容:
- <VIEWCHANGE, n, C, P, i>
- n: 消息序号,本节点最近的一个check-point所确定的序号
- C: 对应于n的check-point 2f+1个CHECKPOINT消息集合
- P: 一个(P_m)组成的集合,m表示消息,m的序号是大于n的,(P_m)表示序号为m的达成prepared状态的消息集合。(P_m)内容包含关于m的(1)个pre-prepare消息和(2f)条prepare消息集合。
- i: 节点ID
由消息结构可以看出,当节点发出viewchange消息时,节点将本地的prepared状态信息打包到了消息中,传递给后续的view。
当view+1所对应的privary收到了2f个有效的view-change消息,它就会广播<NEW-VIEW, v+1, (V), (O)>消息;
+ (V): 是view-change消息集合
+ (O): pre-prepare消息的集合, (O)按照如下的过程计算:
- privary根据收到的view-change消息判断,最低的check-point min-s和最高的check-point max-s
- 对介于 min-s和max-s之间的每个序号n创建pre-prepare消息。这分两种情况:(1) 在P集合存在一个(P_m)其中序号为n; (2) 没有这样的集合(P_m). 对于第一种情况,创建一个pre-prepare消息,<PRE-PREPARE, v+1, n, d>。对于第二种情况,创建新的<PRE-PREPARE, v+1, n, d_null>。
可以这样理解,在新的view中,节点是在上一轮view中各个节点的prepared状态基础上进行共识流程的。
发生view转换时,需要的保证的是:如果视图转换之前的消息m被分配了序号n, 并且达到了prepared状态,那么在视图转换之后,该消息也必须被分配序号n(safety特性)。因为达到prepared状态以后,就有可能存在某个节点commit-local。要保证对于m的commit-local,在视图转换之后,其他节点的commit-local依然是一样的序号。
5. 思考
- 经过两轮投票的BFT共识协议,比如PBFT、tendermint等,轮次切换时,都是在previous轮次中的第一轮投票结果基础上继续共识流程。
- BFT类共识需要保证safty和liveness,safety可以在asynchrony假设下达成,liveness需要弱同步假设
- pbft的核心设计是viewchange,巧妙的在viewchange消息添加prepared信息,实现将previous视图信息传递到下一轮。但是,这样存在的问题是,消息太大了,有些冗余。
6. Reference
[1] Castro, Miguel, and Barbara Liskov. "Practical Byzantine fault tolerance." OSDI. Vol. 99. 1999.
[2] Kwon, Jae. "Tendermint: Consensus without mining." Draft v. 0.6, fall (2014).
以上是关于对PBFT算法的理解的主要内容,如果未能解决你的问题,请参考以下文章