elasticsearch补全功能之只补全筛选后的部分数据context suggester
Posted alxps
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了elasticsearch补全功能之只补全筛选后的部分数据context suggester相关的知识,希望对你有一定的参考价值。
官方文档https://www.elastic.co/guide/en/elasticsearch/reference/5.0/suggester-context.html
下面所有演示基于elasticsearch5.x和Python3.x
最近项目使用elasticsearch的补全功能时,需要对于所有文章(article)的作者名字(author)的搜索做补全,文章的mapping大致如下
ARTICLE = {
‘properties‘: {
‘id‘: {
‘type‘: ‘integer‘,
‘index‘: ‘not_analyzed‘,
},
‘author‘: {
‘type‘: ‘text‘,
},
‘author_completion‘: {
‘type‘: ‘completion‘,
},
‘removed‘: {
‘type‘: ‘boolean‘,
}
}
}
MAPPINGS = {
‘mappings‘: {
‘article‘: ARTICLE,
}
}
现在的需求是,针对于下架状态removed为True的不做补全提示。
作为演示先插入部分数据,代码如下
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from elasticsearch.helpers import bulk
from elasticsearch import Elasticsearch
ES_HOSTS = [{‘host‘: ‘localhost‘, ‘port‘: 9200}, ]
ES = Elasticsearch(hosts=ES_HOSTS)
INDEX = ‘test_article‘
TYPE = ‘article‘
ARTICLE = {
‘properties‘: {
‘id‘: {
‘type‘: ‘integer‘,
‘index‘: ‘not_analyzed‘,
},
‘author‘: {
‘type‘: ‘text‘,
},
‘author_completion‘: {
‘type‘: ‘completion‘,
},
‘removed‘: {
‘type‘: ‘boolean‘,
}
}
}
MAPPINGS = {
‘mappings‘: {
‘article‘: ARTICLE,
}
}
def create_index():
"""
插入数据前创建对应的index
"""
ES.indices.delete(index=INDEX, ignore=404)
ES.indices.create(index=INDEX, body=MAPPINGS)
def insert_data():
"""
添加测试数据
:return:
"""
test_datas = [
{
‘id‘: 1,
‘author‘: ‘tom‘,
‘author_completion‘: ‘tom‘,
‘removed‘: False
},
{
‘id‘: 2,
‘author‘: ‘tom_cat‘,
‘author_completion‘: ‘tom_cat‘,
‘removed‘: True
},
{
‘id‘: 3,
‘author‘: ‘kitty‘,
‘author_completion‘: ‘kitty‘,
‘removed‘: False
},
{
‘id‘: 4,
‘author‘: ‘tomato‘,
‘author_completion‘: ‘tomato‘,
‘removed‘: False
},
]
bulk_data = []
for data in test_datas:
action = {
‘_index‘: INDEX,
‘_type‘: TYPE,
‘_id‘: data.get(‘id‘),
‘_source‘: data
}
bulk_data.append(action)
success, failed = bulk(client=ES, actions=bulk_data, stats_only=True)
print(‘success‘, success, ‘failed‘, failed)
if __name__ == ‘__main__‘:
create_index()
insert_data()
成功插入4条测试数据,下面测试获取作者名称补全建议,代码如下
def get_suggestions(keywords):
body = {
# ‘size‘: 0, # 这里是不返回相关搜索结果的字段,如author,id等,作为测试这里返回
‘_source‘: ‘suggest‘,
‘suggest‘: {
‘author_prefix_suggest‘: {
‘prefix‘: keywords,
‘completion‘: {
‘field‘: ‘author_completion‘,
‘size‘: 10,
}
}
},
# 对于下架数据,我单纯的以为加上下面的筛选就行了
‘query‘: {
‘term‘: {
‘removed‘: False
}
}
}
suggest_data = ES.search(index=INDEX, doc_type=TYPE, body=body)
return suggest_data
if __name__ == ‘__main__‘:
# create_index()
# insert_data()
suggestions = get_suggestions(‘t‘)
print(suggestions)
"""
suggestions = {
‘took‘: 0,
‘timed_out‘: False,
‘_shards‘: {
‘total‘: 5,
‘successful‘: 5,
‘skipped‘: 0,
‘failed‘: 0
},
‘hits‘: {
‘total‘: 3,
‘max_score‘: 0.6931472,
‘hits‘: [
{‘_index‘: ‘test_article‘, ‘_type‘: ‘article‘, ‘_id‘: ‘4‘, ‘_score‘: 0.6931472,
‘_source‘: {}},
{‘_index‘: ‘test_article‘, ‘_type‘: ‘article‘, ‘_id‘: ‘1‘, ‘_score‘: 0.2876821,
‘_source‘: {}},
{‘_index‘: ‘test_article‘, ‘_type‘: ‘article‘, ‘_id‘: ‘3‘, ‘_score‘: 0.2876821,
‘_source‘: {}}]},
‘suggest‘: {
‘author_prefix_suggest‘: [{‘text‘: ‘t‘, ‘offset‘: 0, ‘length‘: 1, ‘options‘: [
{‘text‘: ‘tom‘, ‘_index‘: ‘test_article‘, ‘_type‘: ‘article‘, ‘_id‘: ‘1‘, ‘_score‘: 1.0,
‘_source‘: {}},
{‘text‘: ‘tom_cat‘, ‘_index‘: ‘test_article‘, ‘_type‘: ‘article‘, ‘_id‘: ‘2‘, ‘_score‘: 1.0,
‘_source‘: {}},
{‘text‘: ‘tomato‘, ‘_index‘: ‘test_article‘, ‘_type‘: ‘article‘, ‘_id‘: ‘4‘, ‘_score‘: 1.0,
‘_source‘: {}}]}]
}
}
"""
发现,removed为True的tom_cat赫然在列,明明加了
‘query‘: {
‘term‘: {
‘removed‘: False
}
}
却没有起作用,难道elasticsearch不支持这种需求!?怎么可能……
查阅文档发现解决方法为https://www.elastic.co/guide/en/elasticsearch/reference/5.0/suggester-context.html
找到问题所在,首先改造mapping,并重新录入测试数据如下
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from elasticsearch.helpers import bulk
from elasticsearch import Elasticsearch
ES_HOSTS = [{‘host‘: ‘localhost‘, ‘port‘: 9200}, ]
ES = Elasticsearch(hosts=ES_HOSTS)
INDEX = ‘test_article‘
TYPE = ‘article‘
ARTICLE = {
‘properties‘: {
‘id‘: {
‘type‘: ‘integer‘,
‘index‘: ‘not_analyzed‘
},
‘author‘: {
‘type‘: ‘text‘,
},
‘author_completion‘: {
‘type‘: ‘completion‘,
‘contexts‘: [ # 这里是关键所在
{
‘name‘: ‘removed_tab‘,
‘type‘: ‘category‘,
‘path‘: ‘removed‘
}
]
},
‘removed‘: {
‘type‘: ‘boolean‘,
}
}
}
MAPPINGS = {
‘mappings‘: {
‘article‘: ARTICLE,
}
}
def create_index():
"""
插入数据前创建对应的index
"""
ES.indices.delete(index=INDEX, ignore=404)
ES.indices.create(index=INDEX, body=MAPPINGS)
def insert_data():
"""
添加测试数据
:return:
"""
test_datas = [
{
‘id‘: 1,
‘author‘: ‘tom‘,
‘author_completion‘: ‘tom‘,
‘removed‘: False
},
{
‘id‘: 2,
‘author‘: ‘tom_cat‘,
‘author_completion‘: ‘tom_cat‘,
‘removed‘: True
},
{
‘id‘: 3,
‘author‘: ‘kitty‘,
‘author_completion‘: ‘kitty‘,
‘removed‘: False
},
{
‘id‘: 4,
‘author‘: ‘tomato‘,
‘author_completion‘: ‘tomato‘,
‘removed‘: False
},
]
bulk_data = []
for data in test_datas:
action = {
‘_index‘: INDEX,
‘_type‘: TYPE,
‘_id‘: data.get(‘id‘),
‘_source‘: data
}
bulk_data.append(action)
success, failed = bulk(client=ES, actions=bulk_data, stats_only=True)
print(‘success‘, success, ‘failed‘, failed)
if __name__ == ‘__main__‘:
create_index()
insert_data()
Duang!意想不到的问题出现了
elasticsearch.helpers.BulkIndexError: (‘4 document(s) failed to index.‘, [{‘index‘: {‘_index‘: ‘test_article‘, ‘_type‘: ‘article‘, ‘_id‘: ‘1‘, ‘status‘: 400, ‘error‘: {‘type‘: ‘illegal_argument_exception‘, ‘reason‘: ‘Failed to parse context field [removed], only keyword and text fields are accepted‘}, ‘data‘: {‘id‘: 1, ‘author‘: ‘tom‘, ‘author_completion‘: ‘tom‘, ‘removed‘: False}}}, {‘index‘: {‘_index‘: ‘test_article‘, ‘_type‘: ‘article‘, ‘_id‘: ‘2‘, ‘status‘: 400, ‘error‘: {‘type‘: ‘illegal_argument_exception‘, ‘reason‘: ‘Failed to parse context field [removed], only keyword and text fields are accepted‘}, ‘data‘: {‘id‘: 2, ‘author‘: ‘tom_cat‘, ‘author_completion‘: ‘tom_cat‘, ‘removed‘: True}}}, {‘index‘: {‘_index‘: ‘test_article‘, ‘_type‘: ‘article‘, ‘_id‘: ‘3‘, ‘status‘: 400, ‘error‘: {‘type‘: ‘illegal_argument_exception‘, ‘reason‘: ‘Failed to parse context field [removed], only keyword and text fields are accepted‘}, ‘data‘: {‘id‘: 3, ‘author‘: ‘kitty‘, ‘author_completion‘: ‘kitty‘, ‘removed‘: False}}}, {‘index‘: {‘_index‘: ‘test_article‘, ‘_type‘: ‘article‘, ‘_id‘: ‘4‘, ‘status‘: 400, ‘error‘: {‘type‘: ‘illegal_argument_exception‘, ‘reason‘: ‘Failed to parse context field [removed], only keyword and text fields are accepted‘}, ‘data‘: {‘id‘: 4, ‘author‘: ‘tomato‘, ‘author_completion‘: ‘tomato‘, ‘removed‘: False}}}])
意思是context只支持keyword和text类型,而上面removed类型为boolean,好吧,再改造mapping,将mapping的removed改为keyword类型……
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from elasticsearch.helpers import bulk
from elasticsearch import Elasticsearch
ES_HOSTS = [{‘host‘: ‘localhost‘, ‘port‘: 9200}, ]
ES = Elasticsearch(hosts=ES_HOSTS)
INDEX = ‘test_article‘
TYPE = ‘article‘
ARTICLE = {
‘properties‘: {
‘id‘: {
‘type‘: ‘integer‘,
‘index‘: ‘not_analyzed‘
},
‘author‘: {
‘type‘: ‘text‘,
},
‘author_completion‘: {
‘type‘: ‘completion‘,
‘contexts‘: [ # 这里是关键所在
{
‘name‘: ‘removed_tab‘,
‘type‘: ‘category‘,
‘path‘: ‘removed‘
}
]
},
‘removed‘: {
‘type‘: ‘keyword‘,
}
}
}
MAPPINGS = {
‘mappings‘: {
‘article‘: ARTICLE,
}
}
def create_index():
"""
插入数据前创建对应的index
"""
ES.indices.delete(index=INDEX, ignore=404)
ES.indices.create(index=INDEX, body=MAPPINGS)
def insert_data():
"""
添加测试数据
:return:
"""
test_datas = [
{
‘id‘: 1,
‘author‘: ‘tom‘,
‘author_completion‘: ‘tom‘,
‘removed‘: ‘False‘
},
{
‘id‘: 2,
‘author‘: ‘tom_cat‘,
‘author_completion‘: ‘tom_cat‘,
‘removed‘: ‘True‘
},
{
‘id‘: 3,
‘author‘: ‘kitty‘,
‘author_completion‘: ‘kitty‘,
‘removed‘: ‘False‘
},
{
‘id‘: 4,
‘author‘: ‘tomato‘,
‘author_completion‘: ‘tomato‘,
‘removed‘: ‘False‘
},
]
bulk_data = []
for data in test_datas:
action = {
‘_index‘: INDEX,
‘_type‘: TYPE,
‘_id‘: data.get(‘id‘),
‘_source‘: data
}
bulk_data.append(action)
success, failed = bulk(client=ES, actions=bulk_data, stats_only=True)
print(‘success‘, success, ‘failed‘, failed)
if __name__ == ‘__main__‘:
create_index()
insert_data()
mission success。看看表结构ok
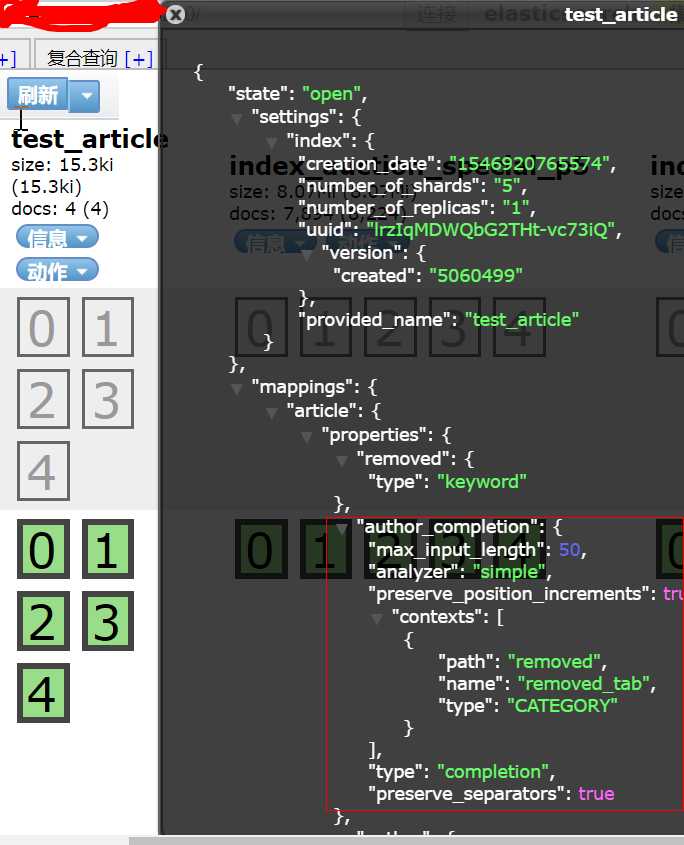
接下来就是获取补全建议
def get_suggestions(keywords):
body = {
‘size‘: 0,
‘_source‘: ‘suggest‘,
‘suggest‘: {
‘author_prefix_suggest‘: {
‘prefix‘: keywords,
‘completion‘: {
‘field‘: ‘author_completion‘,
‘size‘: 10,
‘contexts‘: {
‘removed_tab‘: [‘False‘, ] # 筛选removed为‘False‘的补全
}
}
}
},
}
suggest_data = ES.search(index=INDEX, doc_type=TYPE, body=body)
return suggest_data
if __name__ == ‘__main__‘:
# create_index()
# insert_data()
suggestions = get_suggestions(‘t‘)
print(suggestions)
"""
suggestions = {
‘took‘: 0,
‘timed_out‘: False,
‘_shards‘: {
‘total‘: 5,
‘successful‘: 5,
‘skipped‘: 0, ‘failed‘: 0
},
‘hits‘: {
‘total‘: 0,
‘max_score‘: 0.0,
‘hits‘: []
},
‘suggest‘: {
‘author_prefix_suggest‘: [
{‘text‘: ‘t‘, ‘offset‘: 0, ‘length‘: 1, ‘options‘: [
{‘text‘: ‘tom‘, ‘_index‘: ‘test_article‘, ‘_type‘: ‘article‘, ‘_id‘: ‘1‘, ‘_score‘: 1.0,
‘_source‘: {},
‘contexts‘: {‘removed_tab‘: [‘False‘]}},
{‘text‘: ‘tomato‘, ‘_index‘: ‘test_article‘, ‘_type‘: ‘article‘, ‘_id‘: ‘4‘, ‘_score‘: 1.0,
‘_source‘: {},
‘contexts‘: {‘removed_tab‘: [‘False‘]}}]}]}}
"""
发现,removed为‘True‘的tom_cat被筛选掉了,大功告成!
以上是关于elasticsearch补全功能之只补全筛选后的部分数据context suggester的主要内容,如果未能解决你的问题,请参考以下文章