特殊变量的处理
Posted wqbin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了特殊变量的处理相关的知识,希望对你有一定的参考价值。
表述类目的变量通常,通常没有次序概念,且取值范围有限。例如性别行业信用卡类型。有些模型可以直接读类别变量(例如决策树)。有些模型不能识别类别变量(例如回归模型,神经网络,有距离的度量模型(svn,knn))。
当类别变量无法放入模型的时候,需要做编码处理即以数值的形式替代原有的值:
- onehot编码
- dummy
- 浓度编码
- WOE编码
我们主要用onehot编码,dummy(哑变量)操作,通常会使得我们模型具有较强的非线性能力。
那么这两种编码方式是如何进行的呢?
它们之间是否有联系?
又有什么样的区别?
是如何提升模型的非线性能力的呢?
我们带着这三个疑问进入特殊变量的主题:
这一个迷你数据集,为什么我们用1,2,3,4这样的数据值不行呢,非要用00001,01000这样的才可以?即为什么不直接提供标签编码给模型训练就够了?为什么需要one hot编码?
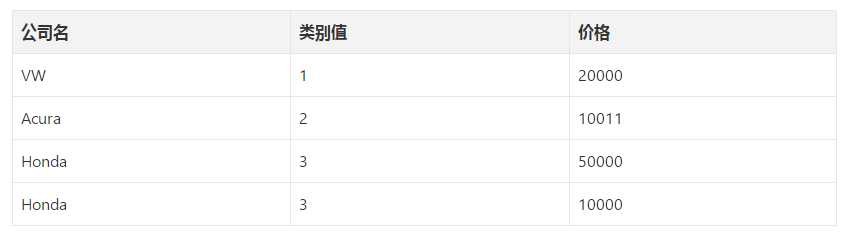
标签编码的问题是它假定类别值越高,该类别更好。
让我解释一下:根据标签编码的类别值,我们的迷你数据集中VW > Acura > Honda。
比方说,假设模型内部计算平均值(神经网络中有大量加权平均运算),那么1 + 3 = 4,4 / 2 = 2.
这意味着:VW和Honda平均一下是Acura。毫无疑问,这是一个糟糕的方案。该模型的预测会有大量误差。
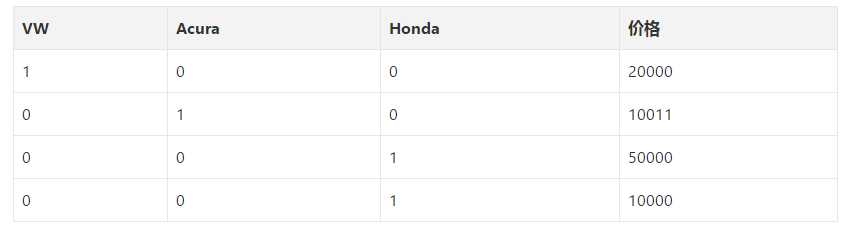
我们使用one hot编码器对类别进行“二进制化”操作,然后将其作为模型训练的特征,原因正在于此。
当然,如果我们在设计网络的时候考虑到这点,对标签编码的类别值进行特别处理,那就没问题。不过,在大多数情况下,使用one hot编码是一个更简单直接的方案。
如果原本的标签编码是有序的,那one hot编码就不合适了——会丢失顺序信息。
转化成二进制编码(如下图所示):
以上是关于特殊变量的处理的主要内容,如果未能解决你的问题,请参考以下文章