Adaboost
Posted wqbin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Adaboost相关的知识,希望对你有一定的参考价值。
前言
集成学习按照个体学习器之间是否存在依赖关系可以分为两类:
第一个是个体学习器之间存在强依赖关系,一系列个体学习器基本都需要串行生成。代表算法是boosting系列算法。在boosting系列算法中, Adaboost是最著名的算法之一。
第二类是个体学习器之间不存在强依赖关系,一系列个体学习器可以并行生成,代表算法是bagging和随机森林(Random Forest)系列算法。。
Adaboost既可以用作分类,也可以用作回归。
正题
简介
AdaBoost是集成学习算法boosting的一种实现,它用弱分类器的线性组合来构造强分类器,用于二分类问题。
与随机森林进行样本抽样来训练多个分类器不同,Adaboost算法在训练时样本具有权重,并且会在训练过程中动态调整,被前面的弱分类器错分的样本会加大权重,因此算法会更加关注上个分类器错分的样本。
计算流程:
我们以分类问题作为案例
(1)初始化样本权重值,所有样本的初始权重相等:
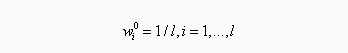
2)循环,对依次训练每个弱分类器:
1.
训练一个弱分类器,并计算它对训练样本集的错误率:
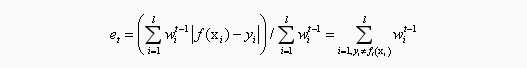
学习器权重系数,对于二元分类问题,第t个弱分类器f(x)的权重系数为
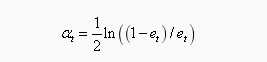
上面公式可以看到分类误差率et越大,则对应的弱分类器权重系数αt越小。也就是说,误差率小的弱分类器权重系数越大。
2.
更新所有样本的权重:
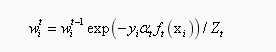
其中 为归一化因子,它是所有样本的权重之和:
为归一化因子,它是所有样本的权重之和:
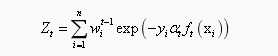
结束循环
3)最后得到强分类器(Adaboost分类采用的是加权表决法)
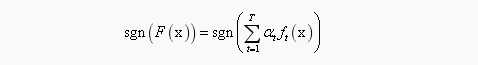
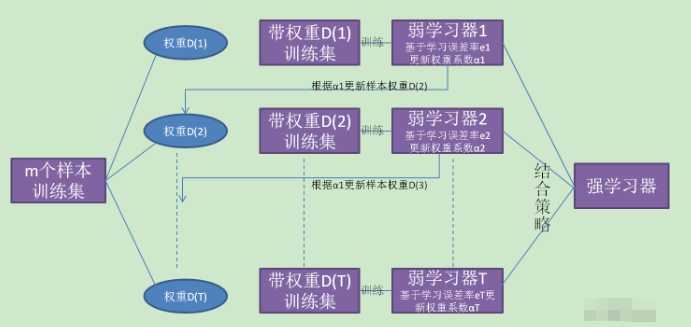
全部流程如图所示:
---------------------------------------------------------------------------------------------------------------------------------------------------
挖坑未完待续
以上是关于Adaboost的主要内容,如果未能解决你的问题,请参考以下文章