jpa table主键生成策略
Posted generalwake
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了jpa table主键生成策略相关的知识,希望对你有一定的参考价值。
用 table 来生成主键详解
它是在不影响性能情况下,通用性最强的 JPA 主键生成器。这种方法生成主键的策略可以适用于任何数据库,不必担心不同数据库不兼容造成的问题。
initialValue不起作用?
Hibernate 从 3.2.3 之后引入了两个新的主键生成器 TableGenerator 和 SequenceStyleGenerator。为了保持与旧版本的兼容,这两个新主键生成器在默认情况下不会被启用,而不启用新 TableGenerator 的 Hibernate 在提供 JPA 的 @TableGenerator 注解时会有 Bug。
这个bug是什么呢?我们将上一节中的Customer.java的getId方法做如下下 List_1 的修改:
List_1. Id的生成策略为TABLE

@TableGenerator(name="ID_GENERATOR",
table="t_id_generator",
pkColumnName="PK_NAME",
pkColumnValue="seed_t_customer_id",
valueColumnName="PK_VALUE",
allocationSize=20,
initialValue=10
)
@GeneratedValue(strategy=GenerationType.TABLE, generator="ID_GENERATOR")
@Id
public Integer getId() {
return id;
}
上面的@TableGenerator配置指定了initialValue=10,指定了主键生成列的初始值为10,这在 @TableGenerator 的 API 文档中写得很清楚。现在 initialValue 值设置为 10, 那么在单元测试中用 JPA 添加新的 Customer 记录时,新记录的主键会从 11 开始。但是,实际上保存到数据库中的主键值确实1 !!!
也就是说,在@TableGenerator中配置的initialValue根本不起作用!!!
这实在令人困惑。其实问题出在程序所用的 JPA 提供者(Hibernate)上面。如果改用其他 JPA 提供者,估计不会出现上面的问题(未验证)。Hibernate 之所以会出现这种情况,并非是不尊重标准,而有它自身的原因。现在,为了把问题讲清楚, 有必要先谈谈 JPA 主键生成器选型的问题,了解一下 @TableGenerator 在 JPA 中的特殊地位。
JPA 主键生成器选型
JPA 提供了四种主键生成器,参看表 1:
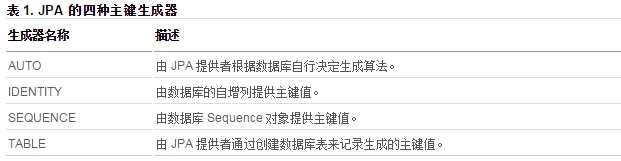
一般来说,支持 IDENTITY 的数据库,如 mysql、SQL Server、DB2 等,AUTO 的效果与 IDENTITY 相同。IDENTITY 主键生成器最大的特点是:在表中插入记录以后主键才会生成。这意味着,实体对象只有在保存到数据库以后,才能得到主键值。用 EntityManager 的 persist 方法来保存实体时必须在数据库中插入纪录,这种主键生成机制大大限制了 JPA 提供者优化性能的可能性。在 Hibernate 中通过设置 FlushMode 为 MANUAL,可以将记录的插入延迟到长事务提交时再执行,从而减少对数据库的访问频率。实施这种系统性能提升方案的前提就是不能使用 IDENTITY 主键生成器。
SEQUENCE 主键生成器主要用在 PostgreSQL、Oracle 等自带 Sequence 对象的数据库管理系统中,它每次从数据库 Sequence 对象中取出一段数值分配给新生成的实体对象,实体对象在写入数据库之前就会分配到相应的主键。
上面的分析中,我们把现实世界中的关系数据库分成了两大类:一是支持 IDENTITY 的数据库,二是支持 SEQUENCE 的数据库。对支持 IDENTITY 的数据库来说,使用 JPA 时变得有点麻烦:出于性能考虑,它们在选用主键生成策略时应当避免使用 IDENTITY 和 AUTO,同时,他们不支持 SEQUENCE。看起来,四个主键生成器里面排除了三个,剩下唯一的选择就是 TABLE。由此可见,TABLE 主键生成机制在 JPA 中地位特殊。它是在不影响性能情况下,通用性最强的 JPA 主键生成器。

TableGenerator 有新旧之分?
JPA 的 @TableGenerator 只是通用的注解,具体的功能要由 JPA 提供者来实现。Hibernate 中实现该注解的类有两个:
一是原有的 TableGenerator,类名为 org.hibernate.id.TableGenerator,这是默认的 TableGenerator。
二是新 TableGenerator,指的是 org.hibernate.id.enhanced.TableGenerator。
当用 Hibernate 来提供 JPA 时,需要通过配置参数指定使用何种 TableGenerator 来提供相应功能。
在 4.3 版本的 Hibernate Reference Manual 关于配置参数的章节中(网址可从参考资源中找到)可以找到如下说明:
我们建议所有使用 @GeneratedValue 的新工程都配置 hibernate.id.new_generator_mappings=true 。因为新的生成器更加高效,也更符合 JPA2 的规范。不过,要是已经使用了 table 或 sequence 生成器,新生成器与之不相兼容。


综合这些资源,可以得到如下结论(重要):
- 如果不配置 hibernate.id.new_generator_mappings=true,使用 Hibernate 来提供 TableGenerator 时,JPA 中 @TableGenerator 注解的 initialValue 参数是无效的。
- Hibernate 开发人员原本希望用新 TableGenerator 替换掉原有的 TableGenerator,但这么做会导致已经使用旧 TableGenerator 的 Hibernate 工程在升级 Hibernate 后,新生成的主键值可能会与原有的主键冲突,导致不可预料的结果。为保持兼容,Hibernate 默认情况下使用旧 TableGenerator 机制。
- 没有历史负担的新 Hibernate 工程都应该使用 hibernate.id.new_generator_mappings=true 配置选项。
提出几个疑问
现在回到上面的问题,要解决这个问题只需在 persistence.xml 文件中添加如下一行配置即可List_2:
List_2. 配置文件persistence.xml中添加一个属性
<!-- Setting is relevant when using @GeneratedValue. It indicates whether or not the new
IdentifierGenerator implementations are used for javax.persistence.GenerationType.AUTO,
javax.persistence.GenerationType.TABLE and javax.persistence.GenerationType.SEQUENCE. Default to false to keep backward compatibility. --> <property name="hibernate.id.new_generator_mappings" value="true"/>
Customer.java的代码只修改了getId方法的注解:
List_3. 实体Customer的主键生成策略采用TABLE
1 package com.magicode.jpa.helloworld;
2
3 import java.util.Date;
4
5 import javax.persistence.Column;
6 import javax.persistence.Entity;
7 import javax.persistence.GeneratedValue;
8 import javax.persistence.GenerationType;
9 import javax.persistence.Id;
10 import javax.persistence.Table;
11 import javax.persistence.TableGenerator;
12 //import javax.persistence.TableGenerator;
13 import javax.persistence.Temporal;
14 import javax.persistence.TemporalType;
15 import javax.persistence.Transient;
16
17 /**
18 * @Entity 用于注明该类是一个实体类
19 * @Table(name="t_customer") 表明该实体类映射到数据库的 t_customer 表
20 */
21 @Table(name="t_customer")
22 @Entity
23 public class Customer {
24
25 private Integer id;
26 private String lastName;
27
28 private String email;
29 private int age;
30
31 private Date birthday;
32
33 private Date createdTime;
34
35 /**
36 * @TableGenerator 标签的属性解释:
37 *
38 * ①、allocationSize 属性需要赋一个整数值。表示了bucket的容量。其默认值为50。
39 * ②、table 属性用于指定辅助表的表名。这里指定为t_id_generator数据表
40 *
41 * 其基本思想就是:从table指定的辅助表中读取一个bucket段id号范围内的第一个数值,记为first_id。在后面持久化过程中的id号是从first_id开始依次递增1得到
42 * 当递增到first_id + allocationSize 的时候,就会再一次从辅助表中读取一个first_id开始新一轮的id生成过程。
43 *
44 * 我们知道,要从数据库中确定一个值,则必须确定其“行”和“列”。JPA自动产生的t_id_generator只有两列。当然,如果该表
45 * 为n个表产生id,则会在t_id_generator表中保存“n行2列”。
46 * 那么,如何从数据表t_id_generator中确定出seed_id用于为Customer实体计算id呢??JPA会依据Customer实体的
47 * @TableGenerator 属性值来依据下面的规则的到seed_id:
48 * ③、valueColumnName 属性指定了seed_id的列名。valueColumnName="PK_VALUE"也就是指定了
49 * seed_id位于PK_VALUE列中。同时,规定了这一列必须是数值型(int,long等)。
50 * 剩下的任务就是如何从n行中确定出是哪一行??
51 * ④、pkColumnName="PK_NAME",pkColumnValue="seed_t_customer_id" 两个一起来确定具体的行:
52 * 在PK_NAME列中,值为seed_t_customer_id的那一行。
53 * ⑤、由上面③和④中确定出来的“行”和“列”就可以得到一个int型的整数值。这个值就是first_id。
54 *
55 * 注意:我们的数据库中可以没有t_id_generator这张表,JPA会自动帮助我们完成该表的创建工作。自动创建的表只有两列:
56 * PK_NAME(VARCHAR)和PK_VALUE(int)。同时会自动添加一条记录(seed_t_customer_id, 51) 依据优化策略的不同,辅助表中记录的数值有区别
57 */
58 @TableGenerator(name="ID_GENERATOR",
59 table="t_id_generator",
60 pkColumnName="PK_NAME",
61 pkColumnValue="seed_t_customer_id",
62 valueColumnName="PK_VALUE",
63 allocationSize=20,
64 initialValue=10
65 )
66 @GeneratedValue(strategy=GenerationType.TABLE, generator="ID_GENERATOR")
67 @Id
68 public Integer getId() {
69 return id;
70 }
71
72 /**
73 * @Column 指明lastName属性映射到表的 LAST_NAME 列中
74 * 同时还可以指定其长度、能否为null等数据限定条件
75 */
76 @Column(name="LAST_NAME", length=50, nullable=false)
77 public String getLastName() {
78 return lastName;
79 }
80
81 /**
82 * 利用 @Temporal 来限定birthday为DATE型
83 */
84 @Column(name="birthday")
85 @Temporal(TemporalType.DATE)
86 public Date getBirthday() {
87 return birthday;
88 }
89
90 /*
91 * 通过 @Column 的 columnDefinition 属性将CREATED_TIME列
92 * 映射为“DATE”类型
93 */
94 @Column(name="CREATED_TIME", columnDefinition="DATE")
95 public Date getCreatedTime() {
96 return createdTime;
97 }
98
99 /*
100 * 通过 @Column 的 columnDefinition 属性将email列
101 * 映射为“TEXT”类型
102 */
103 @Column(columnDefinition="TEXT")
104 public String getEmail() {
105 return email;
106 }
107
108 /*
109 * 工具方法,不需要映射为数据表的一列
110 */
111 @Transient
112 public String getInfo(){
113 return "lastName: " + lastName + " email: " + email;
114 }
115
116 public int getAge() {
117 return age;
118 }
119
120 public void setId(Integer id) {
121 this.id = id;
122 }
123
124 public void setLastName(String lastName) {
125 this.lastName = lastName;
126 }
127
128 public void setEmail(String email) {
129 this.email = email;
130 }
131
132 public void setAge(int age) {
133 this.age = age;
134 }
135
136 public void setBirthday(Date birthday) {
137 this.birthday = birthday;
138 }
139
140 public void setCreatedTime(Date createdTime) {
141 this.createdTime = createdTime;
142 }
143
144 }
main方法如下,每次只需会连续保存两条记录。代码如下:
List_4. 测试main方法
1 package com.magicode.jpa.helloworld;
2
3 import java.util.Date;
4
5 import javax.persistence.EntityManager;
6 import javax.persistence.EntityManagerFactory;
7 import javax.persistence.EntityTransaction;
8 import javax.persistence.Persistence;
9
10 public class Main {
11
12 public static void main(String[] args) {
13
14 /*
15 * 1、获取EntityManagerFactory实例
16 * 利用Persistence类的静态方法,结合persistence.xml中
17 * persistence-unit标签的name属性值得到
18 */
19 EntityManagerFactory emf =
20 Persistence.createEntityManagerFactory("jpa-1");
21
22 // 2、获取EntityManager实例
23 EntityManager em = emf.createEntityManager();
24
25 // 3、开启事物
26 EntityTransaction transaction = em.getTransaction();
27 transaction.begin();
28
29 // 4、调用EntityManager的persist方法完成持久化过程
30 //保存第1条记录
31 Customer customer = new Customer();
32 customer.setAge(9);
33 customer.setEmail("[email protected]");
34 customer.setLastName("Tom");
35 customer.setBirthday(new Date());
36 customer.setCreatedTime(new Date());
37 em.persist(customer);
38
39 //保存第2条记录
40 customer = new Customer();
41 customer.setAge(10);
42 customer.setEmail("[email protected]");
43 customer.setLastName("Jerry");
44 customer.setBirthday(new Date());
45 customer.setCreatedTime(new Date());
46 em.persist(customer);
47
48 // 5、提交事物
49 transaction.commit();
50 // 6、关闭EntityManager
51 em.close();
52 // 7、关闭EntityManagerFactory
53 emf.close();
54
55 }
56 }
现在看执行效果,会发现一个问题。
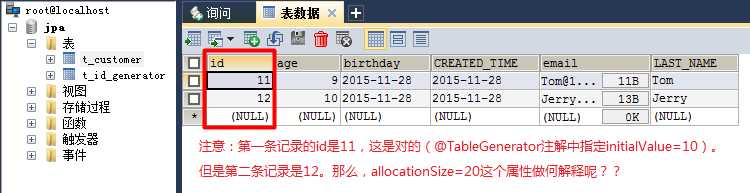
执行第一次以后两个数据表的状态如下:
Figure_1. 数据表t_customer:
Figure_2. 数据表 t_id_generator:
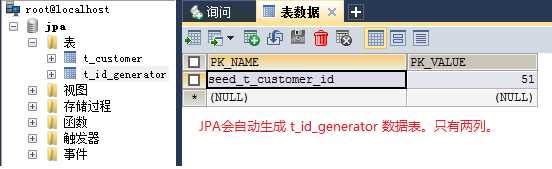
从Figure_1我们似乎能看出某些地方和我们最初想的不一样:@TableGenerator中指定了allocationSize=20,那么不应该是第一条记录为11,第二条记录为11+20=31才对吗?现在为什么是12呢??如果说这里的12是正确的,那么allocationSize=20的作用在哪里体现呢??还有一个就是figure2中的PK_VALUE的值为什么为51,有什么讲究吗??
带着上面的这些疑问我们在第一次运行的基础之上将main方法运行第二次得到结果如下:
Figure_3. 数据表t_customer:
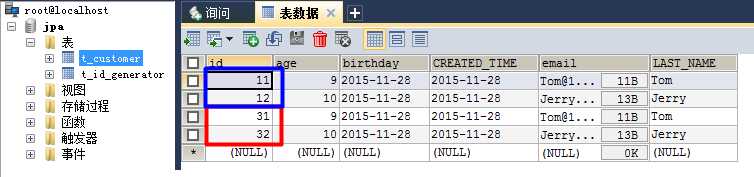
figure 4. 数据表t_id_generator:
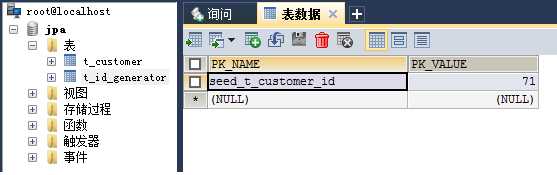
这一次有意思了!!我们从 Figure_3 中看到第二次运行中持久化的第一条记录的id为11+20=31,这么说来allocationSize=20的作用是在这里体现的不成?? Figure_3 难道是在告诉我们,allocationSize=20的意思是后一次EntityManagerFactory(确实是EntityManagerFactory,而不是。后面会有一个简单的验证过程)生命周期会在上一次生命周期的第一个id值上增加20,是这样的吗??还有一个问题就是,Figure_4的值是51+20=71。
上面的问题归根到底是一个问题:@TableGenerator 注解的 allocationSize 属性值的作用是什么??
上面讲到Hibernate引入了新的TableGenerator实现类。下面先看看有哪些新的用法,然后再讲解关于allocationSize 的问题:
新 TableGenerator 的更多用法
新 TableGenerator 除了实现 JPA TableGenerator 注解的全部功能外,还有其他 JPA 注解没有包含的功能,其配置参数共有 8 项。新 TableGenerator 的 API 文档详细解释了这 8 项参数的含义,但很奇怪的是,Hibernate API 文档中给出的是 Java 常量的名字,在实际使用时还需要通过这些常量名找到对应的字符串,非常不方便。用对应字符串替换常量后,可以得到下面的配置参数表:

在描述各个参数的含义时,表中多次提到了“序列”,在这个表里的意思相当于 sequence,也相当于 segment。这里反映出术语的混乱,如果在 Hibernate 文档中把两个英文单词统一起来,阅读的时候会更加清楚。新 TableGenerator 的 8 个参数可分为两组,前 5 个参数描述的是辅助表的结构,后 3 个参数用于配置主键生成算法。
先来看前 5 个参数,下图是本文示例程序用于主键生成的辅助表,把图中的元素和新 TableGenerator 前 4 个配置参数一一对应起来,它们的含义一目了然。
Figure 5. 辅助表
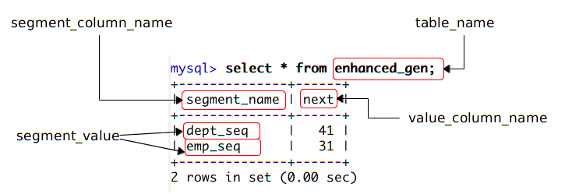
第 5 个参数 segment_value_length 是用来确定segment_value的长度,即序列名所能使用的最大字符数。从这 5 个参数的含义可以看出,新 TableGenerator 支持在同一个表中放下多个主键生成器,从而避免数据库中为生成主键而创建大量的辅助表。
后面 3 个参数用于描述主键生成算法。第 6 个参数指定初始值。第 7 个参数 increment_size 确定了步长。最关键的是第 8 个参数 optimizer。optimizer 的默认值一栏写的是“依 increment_size 的取值而定”,到底如何确定呢?
为搞清楚这个问题,需要先来了解一下 Hibernate 自带的 Optimizer。
Hibernate 自带的 Optimizer
Optimizer 可以翻译成优化器,使用优化器是为了避免每次生成主键时都会访问数据库。从 Hibernate 官方文档中找不到优化器的说明,需要查阅源码,在org.hibernate.id.enhanced.OptimizerFactory 类中可以找到这些优化器的名字及对应的实现类,其中优化器的名字就是新 TableGenerator 中 optimizer 参数中能够使用的值:
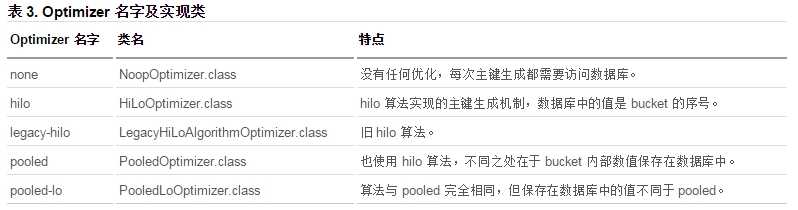
Hibernate 自带了 5 种优化器,那么现在就可以加到上一节提到的问题了:默认情况下,新 TableGenerator 会选择哪个优化器呢?
又一次,在 Hibernate 文档中找不到答案,还是要去查阅源码。通过分析 TableGenerator,可以看到 optimizer 的选择策略。具体过程可用下图来描述:
Figure 6. 选定优化器的过程
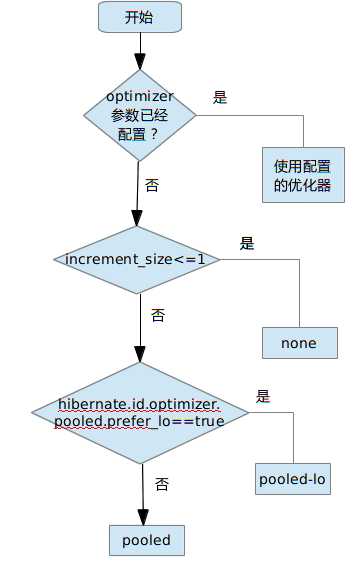

可以看出,hilo 和 legacy-hilo 两种优化器,除非指定,一般不会在实践中出现。接下来很重要的一步就是判断 increment_size 的值,如果 increment_size 不做指定,使用默认的 1,那么最终选择的优化器会是“none”。选中了“none”也就意味着没有任何优化,每次主键的生成都需要访问数据库。这种情况下 TableGenerator 的优势丧失殆尽,如果再用同一张表生成多个实体的主键,构造出来的系统在性能上会是程序员的噩梦。
在 increment_size 值大于 1 的情况下,只有 pooled 和 pooled-lo 两种优化器可供选择,选择条件由布尔型参数 hibernate.id.optimizer.pooled.prefer_lo 确定,该参数默认为 false,这也意味着,大多数情况下选中的优化器会是 pooled。
我们不去讨论 none 和 legacy-hilo,前者不应该使用,后者的名字看上去像是古董。剩下 hilo、pooled 和 pooled-lo 其实是同一种算法,它们的区别在于主键生成辅助表的数值。
Optimizer 究竟在表(辅助表)中记录了什么?
在表 3 中提到 hilo 优化器在辅助表中的数值是 bucket 的序号。这里 bucket 可以翻译成“桶”,也可翻译成“块”,其含义就是一段连续可分配的整数,如:1-10,50-100 等。桶的容量即是 increment_size 的值,假定 increment_size 的值为 50,那么桶的序号和每个桶容纳的整数可参看下表:

hilo 优化器把桶的序号放在了数据库辅助表中,pooled-lo 优化器把下一个桶的第一个整数放在数据库辅助表中,而 pooled 优化器则把下下桶的第一个整数放在数据库辅助表中。
从这里就可以解释Figure 1 和 Figure 2 的现象了:Figure 1中的第一个id号是11,在实体类中设置了allocationSize=20, 而Figure 2的数据库辅助表中记录的数据是51。这里的51=11+20+20,也就是下下桶的第一个整数。说明采用了pooled优化器。
我们可以理解的是:在这种优化策略之下,JPA在生成id的时候每20条记录(由allocationSize这个容量参数来决定,如:11~30,31~50...等)中仅仅需要读取一次辅助表(只需要读取bucket内的第一个数值,它是记录在辅助表中的,如:11,31....等)。这样就极大的降低了辅助表的访问次数。
举个例子,如果 increment_size=50, 当前某实体分到的主键编号为 60,可以推测出各个优化器及对应的数据库辅助表中的值。如下表所示:

一般来说,pooled-lo 比 pooled 更符合人的习惯,没有设置 hibernate.id.optimizer.pooled.prefer_lo 为 true 时,数据库辅助表的值会出乎人的意料。程序员看到英文单词“pooled”,会和连接池这样的概念联系在一起,这里的池不过是一堆可用于主键分配的整数的“池”,其含义与连接池很相似。
新 TableGenerator 实例
最后,演示一下 Hibernate 新 TableGenerator 的完整功能。新 TableGenerator 的一些功能不在 JPA 中,因此不能使用 JPA 的 @TableGenerator 注解,而是要使用Hibernate 自身的 @GenericGenerator 注解。
@GenericGenerator 注解有个 strategy 参数,用来指定主键生成器的名称或类名,类名是容易找到的,不过写起来太不方便了。生成器的名称却不大好找,翻遍 Hibernate 的 manual,devguide,都无法找到这些生成器的名称,最后还得去看源码。可以在 DefaultIdentifierGeneratorFactory 类中找到新 TableGenerator 的名称应是“enhanced-table”。配置新 TableGenerator 的例子参看 List_5 的代码:
List_5. 配置新 TableGenerator 的代码
1 @Entity @Table(name="emp4")
2 public class Employee4 {
3
4 @GenericGenerator( name="id_gen", strategy="enhanced-table",
5 parameters = {
6 @Parameter( name = "table_name", value = "enhanced_gen"),
7 @Parameter( name = "value_column_name", value = "next"),
8 @Parameter( name = "segment_column_name",value = "segment_name"),
9 @Parameter( name = "segment_value", value = "emp_seq"),
10 @Parameter( name = "increment_size", value = "10"),
11 @Parameter( name = "optimizer",value = "pooled-lo")
12 })
13 @GeneratedValue(generator="id_gen")
14 @Id
15 private long id;
16
17 private String firstName; private String lastName;
18 //......
19 }
关于空洞
不管是 hilo、还是 pooled、或者 pooled-lo,在使用过程中不可避免地会产生空洞。比如当前主键编号分到第 60,接下来重启了应用程序(就是在上面mian运行两次的效果,第二次的第一个id是从31开始,这样中间就有很多的id号没有使用)或者更准确的说是在一次新的EntityManagerFactory实例中(后面有一个简单的验证过程),Hibernate 无法记住上一次分配的数值,于是 61-100 之间的整数可能永远都不会用于主键的分配。很多人会对此不适应,觉得像是丢了什么东西,应用程序也因此不够完美。其实,仔细去分析,这种感觉只能算是人的心理不适,对程序来说,只是需要生成唯一而不重复的数值而已,数据库记录之间的主键编号是否连续根本不影响系统的使用。ORM 程序需要适应这些空洞的存在,计算机的世界里不会因为这些空洞而不够完美。
下面有两个示例代码会简单的验证空洞是出现在不同的EntityManagerFactory生命周期中的:
List_6. 证明空洞不会出现在不同的EntityManager生命周期中:1次EntityManagerFactory周期,3次EntityManager周期


1 package com.magicode.jpa.helloworld;
2
3 import java.util.Date;
4
5 import javax.persistence.EntityManager;
6 import javax.persistence.EntityManagerFactory;
7 import javax.persistence.EntityTransaction;
8 import javax.persistence.Persistence;
9
10 public class Main {
11
12 /**
13 * 测试:
14 * 1次EntityManagerFactory生命周期,3次EntityManager
15 * 生命周期。id分配上面不会出现空洞。
16 */
17 public static void main(String[] args) {
18
19 /*
20 * 1、获取EntityManagerFactory实例
21 * 利用Persistence类的静态方法,结合persistence.xml中
22 * persistence-unit标签的name属性值得到
23 */
24 EntityManagerFactory emf =
25 Persistence.createEntityManagerFactory("jpa-1");
26
27 // 注意for的位置
28 for(int i = 0; i < 3; i++){
29 // 2、获取EntityManager实例
30 EntityManager em = emf.createEntityManager();
31
32 // 3、开启事物
33 EntityTransaction transaction = em.getTransaction();
34 transaction.begin();
35
36 // 4、调用EntityManager的persist方法完成持久化过程
37 //保存第1条记录
38 Customer customer = new Customer();
39 customer.setAge(9);
40 customer.setEmail("[email protected]");
41 customer.setLastName("Tom");
42 customer.setBirthday(new Date());
43 customer.setCreatedTime(new Date());
44 em.persist(customer);
45
46 //保存第2条记录
47 customer = new Customer();
48 customer.setAge(10);
49 customer.setEmail("[email protected]");
50 customer.setLastName("Jerry");
51 customer.setBirthday(new Date());
52 customer.setCreatedTime(new Date());
53 em.persist(customer);
54
55 // 5、提交事物
56 transaction.commit();
57 // 6、关闭EntityManager
58 em.close();
59 }
60
61 // 7、关闭EntityManagerFactory
62 emf.close();
63
64 }
65 }
执行List_6的示例代码以后数据表的状态如下:
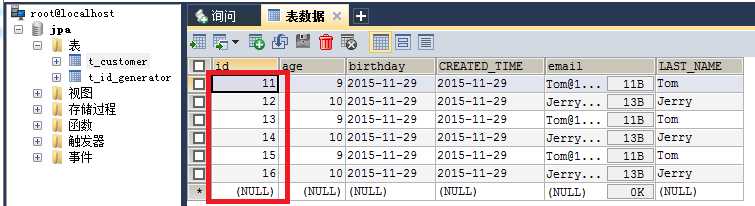
Figure_7. 没有id空洞出现
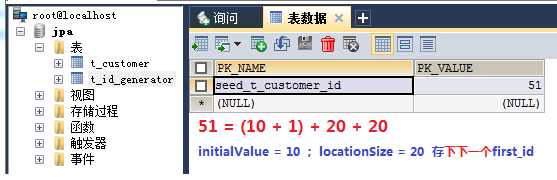
Figure_8. 说明只是读(修改,读的同时就会修改)了一次辅助表
List_7. 证明id空洞会出现在不同的EntityManagerFactory生命周期中:3次EntityManagerFactory周期,3次EntityManager周期
1 package com.magicode.jpa.helloworld;
2
3 import java.util.Date;
4
5 import javax.persistence.EntityManager;
6 import javax.persistence.EntityManagerFactory;
7 import javax.persistence.EntityTransaction;
8 import javax.persistence.Persistence;
9
10 public class Main {
11
12 /**
13 * 测试:
14 * 3次EntityManagerFactory生命周期,3次EntityManager
15 * 生命周期。id分配上面会出现空洞。
16 */
17 public static void main(String[] args) {
18
19 // 注意for的位置
20 for(int i = 0; i < 3; i++){
21 /*
22 * 1、获取EntityManagerFactory实例
23 * 利用Persistence类的静态方法,结合persistence.xml中
24 * persistence-unit标签的name属性值得到
25 */
26 EntityManagerFactory emf =
27 Persistence.createEntityManagerFactory("jpa-1");
28
29 // 2、获取EntityManager实例
30 EntityManager em = emf.createEntityManager();
31
32 // 3、开启事物
33 EntityTransaction transaction = em.getTransaction();
34 transaction.begin();
35
36 // 4、调用EntityManager的persist方法完成持久化过程
37 //保存第1条记录
38 Customer customer = new Customer();
39 customer.setAge(9);
40 customer.setEmail("[email protected]");
41 customer.setLastName("Tom");
42 customer.setBirthday(new Date());
43 customer.setCreatedTime(new Date());
44 em.persist(customer);
45
46 //保存第2条记录
47 customer = new Customer();
48 customer.setAge(10);
49 customer.setEmail("[email protected]");
50 customer.setLastName("Jerry");
51 customer.setBirthday(new Date());
52 customer.setCreatedTime(new Date());
53 em.persist(customer);
54
55 // 5、提交事物
56 transaction.commit();
57 // 6、关闭EntityManager
58 em.close();
59
60 // 7、关闭EntityManagerFactory
61 emf.close();
62 }
63 }
64 }
删除上次运行以后的数据表。执行List_7,得到运行后的状态如下:
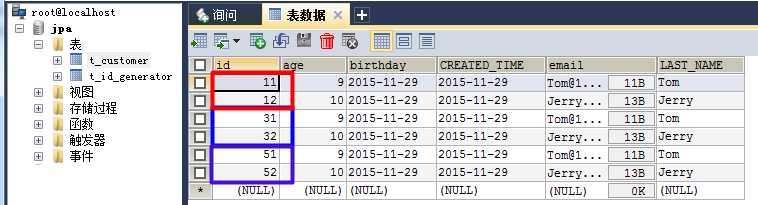
Figure_8. 出现了id空洞,id号分为三段
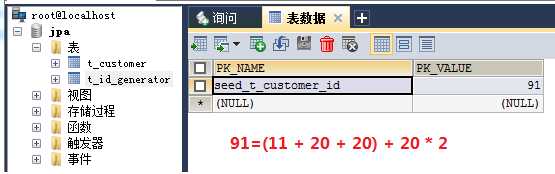
Figure_8. 辅助表的状态,说明辅助表生成之后更新了两次
结果讨论如下:
①、从List_6和List_7的运行状态可以印证id空洞是出现在不同EntityManagerFactory生命周期中的,而不是出现在EntityManager中的。也就是说,辅助表的读取优化是在EntityManagerFactory这个层面上完成的。
②、同时也印证了上面阐述的理论,第一个id分配是从 initialValue + 1 开始的;辅助表记录了下下一个段的first_id(依据不同的策略也可能是下一个段的first_id);
③、每一次EntityManagerFactory生命周期中,当第一次用到某个辅助表的时候,首先会检测指定的辅助表是否存在。如果存在,则读取first_id,同时更新辅助表的数据;如果不存在,则会创建一个辅助表,同时在辅助表中存放数值 initialValue + 1 + locationSize * 2 。
综合上面的介绍,理一下TABLE id生成的过程(重要,上面这么多东西就为了理解这个结论):
1、JPA有4中id的生成策略。TABLE策略只是其中的一种,由于其通用性和对算法的优化,这种策略成为JPA id生成策略中的最优选择。
2、TABLE策略的思想是这样的:
①、TABLE将整数分成若干个段segment;
②、专门用一张数据表(称为“辅助表”)来存放“下一个segment,或者是下下一segment”起始编号,我把它称为first_id;
③、initialValue设置一个初始值,实际上也就是指定了第一个segment的first_id为 initialValue + 1 ;
④、allocationSize设置了segment的长度。
⑤、假如initialValue=10,allocationSize=20,那么会有两个结论, a. 最小的一个id号就是11; b. 分段情况为 11~30,31~50,51~70 ...等;
⑥、如果当前正在使用的是11~30这个id段,那么辅助表中存放的数值会是12、31或51。
保存12的情况:在allocationSize<=1的情况下JPA的实现Hibernate不使用任何的id生成优化策略,辅助表中记录的就是下一个要生成的id号。这样,每次生成id都会访问辅助表,极大的降低了效率;
保存31的情况:设置了hibernate.id.optimizer.pooled.prefer_lo为true,hibernate使用pooled-lo优化器,辅助表中存放的数值是下一个id段的起始值;
保存51的情况:没有设置hibernate.id.optimizer.pooled.prefer_lo为true的时候,hibernate使用pooled优化器,辅助表中保存的数值是下下一个id段的起始值;
⑦、生成id号的时候,每个segment长度仅仅需要访问一次辅助表,极大的降低了访问辅助表的次数:每次生成id号的时候都是在first_id(如,11,31,51...)的基础之上递增得到的。只有当前段内的id号分配完了,才会再一次访问辅助表得到新的first_id,开始新的一轮分配。
⑧、要想分得上述优化红利,则必须在persistence.xml中配置<property name="hibernate.id.new_generator_mappings" value="true"/>使用新的TableGenerator类来实现@TableGenerator注解。也只有使用了该配置,initialValue属性也才会发挥作用。
⑨、所以,allocationSize实际上是一个容量参数,是优化器的优化参数。另外,在不同的EntityManagerFactory生命周期中,持久化对象的id会出现空洞现象。但是,没有关系,我们应该接受这种空洞现象;
以上是关于jpa table主键生成策略的主要内容,如果未能解决你的问题,请参考以下文章