Hadoop架构的初略总结(1)
Hadoop是一个开源的分布式系统基础架构,此架构可以帮助用户可以在不了解分布式底层细节的情况下开发分布式程序。
首先我们要理清楚几个问题。
1.我们为什么需要Hadoop?
解:
简单来说,我们每天上网浏览,上街购物,都会产生数据。我们处于一个数据量呈爆发式增长的时代。我们需要对这些数据进行分析处理,以获得更多有价值的东西。而Hadoop应时代而生。其次我们应该比较了解传统型关系数据库跟Hadoop之间有何区别。这些在前面的Hadoop第二课我们都有所提到。
2.不难知道,现阶段有Hadoop1.0和Hadoop2.0,那Hadoop2.0生态系统是有哪些组成的呢?
Hadoop2.0作为Hadoop1.0的升级版本,可以先大致了解下。
解:
用百度脑图画了个图,便于更直观的记忆了解。
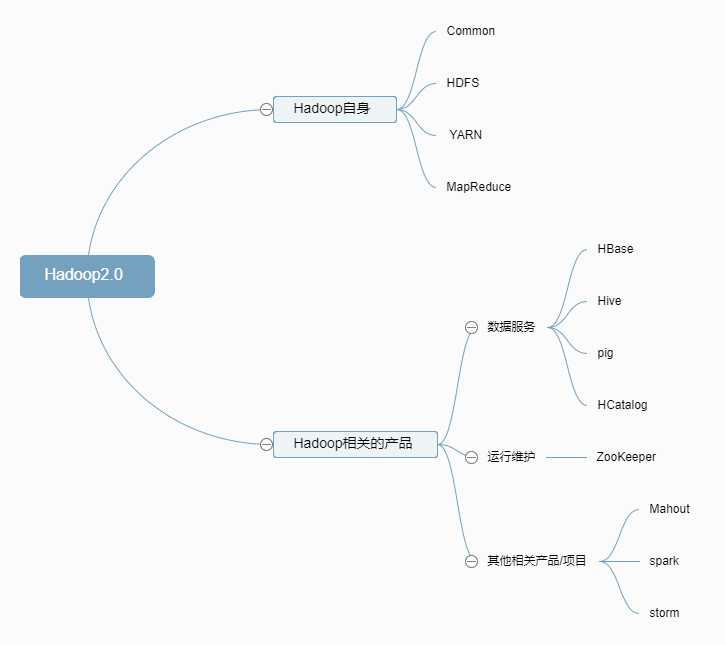
3.在前面的问题中,我们了解了Hadoop2.0大致是由哪些组成的,那么我们由此作为铺垫来探究Hadoop1.0的大致工作流程。
解:
用ppt绘画了个流程图,如图所示:
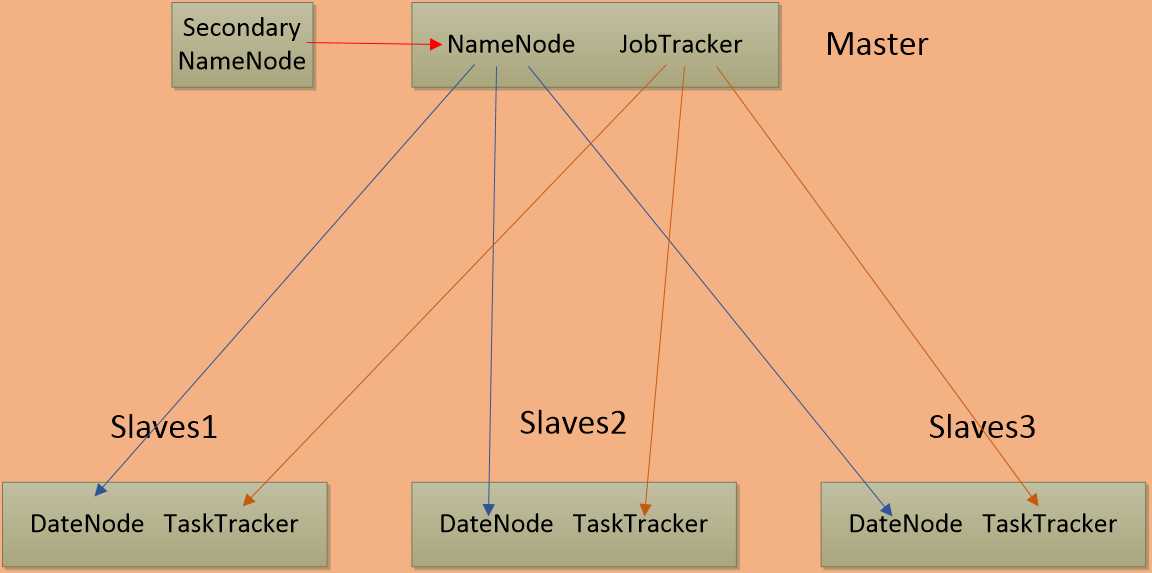
通过观察流程图,我们不难知道以下三点:
? 第一代Hadoop,由分布式文件系统HDFS和分布式计算框架MapReduce组成
? HDFS由一个NameNode和多个DataNode 组成
? MapReduce由一个JobTracker和多个TaskTracker组成
引用某位前辈博客中的话。即Hadoop通过HDFS既能够存储海量的数据,又能够通过MapReduce实现分布式的一个计算,用一句话来概括Hadoop就是:Hadoop是适合大数据的分布式存储与计算的一个平台。
有了对整体结构的大致了解。下面介绍一下HDFS的体系结构。首先我们要知道HDFS采用了主从(Master/Slave)结构模型。何为主从结构?经查阅资料,有以下解释:
HDFS采用的是基于Master/Slave主从架构的分布式文件系统,一个HDFS集群包含一个单独的Master节点和多个Slave节点服务器。这里的一个单独的Master节点的含义是HDFS系统中只存在一个逻辑上的Master组件。一个逻辑的Master节点可以包括两台物理主机,即两台Master服务器、多台Slave服务器。一台Master服务器组成单NameNode集群,两台Master服务器组成双NameNode集群,并且同时被多个客户端访问,所有的这些机器通常都是普通的Linux机器,运行着用户级别(user-level)的服务进程。
这里需要提到的是 集群的概念在Hadoop第二课中有所解释。我的理解就是一个集群是由若干计算机通过某种方式成为了一个整体!
简单来说,一个HDFS集群是有由一个NameNode和若干个DateNode组成,其中NameNode是主节点(Master节点),DateNode是从节点(Slave节点),每一个节点都是一台普通的计算机。只不过在Hadoop2.0中,一个逻辑的Master节点是包含上面跑NameNode进程的两台服务器。
这里引入Client(客户端),顾名思义,就是为客户提供本地服务的程序。具体的我也不清楚。而HDFS是通过三个重要的角色来进行文件系统的管理,NameNode,DateNode,Client。
接下来我们先进一步了解HDFS中NameNode,DateNode,SecondearyNameNode的作用。
(在Hadoop第二课中有相关讲解,这里进行一定归纳补充)
NameNode:
作为主服务器,可以看作是分布式文件系统中的管理者。
1) 主要负责管理文件的命名空间操作,比如打开、关闭、重命名文件或目录。集群配置信息和存储块的复制和客户端对文件的访问操作等;
2) 它会将文件系统的Metadata存储到内存中,这些信息包括文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode中的信息等,也可以说,它负责文件块到具体DateNode的映射。
Ps:也就是说,NameNode管理着整个文件系统的Metadata(元数据),所谓元数据信息指定是除了数据本身之外涉及到文件自身的相关信息 ;其次,NameNode保管着文件与Block块(文件块)序列之间的对应关系以及Block块与DataNode节点之间的对应关系 。文件块后面会进行解释。
DateNode:
HDFS允许用户以文件的形式存储数据。而文件在HDFS底层被分割成了Block。DataNode是文件存储的基本单位,它将被分割的文件块存储到本地文件系统中,保留了所有Block的Metadata,同时周期性地将所有存在的Block信息发送给NameNode(心跳检测 有问题的话用数据备份的方式来保证数据的安全性)。
值得注意的一点:在HDFS中,我们真实的数据是由DataNode来负责来存储的,但是数据具体被存储到了哪个DataNode节点等元数据信息则是由我们的NameNode来存储的。
SecondearyNameNode:不是太了解,就是一个冷备份。具体的我相信后面的博客中我会写到。
最后,我们通过三个具体的操作来说明一下HDFS对数据是如何进行管理的。文件写入,文件读取,文件块复制。(吐槽一下这部分是书上的内容,有了前面知识点的铺垫,可以有个理解。好难得打字…)
(1) 文件写入
1) Client向NameNode发送文件写入的请求
2) NameNode根据文件大小和文件块配置情况,返回给Client所管理的DateNode的信息
3) Client将文件划分为多个Block,根据DataNode的地址信息,按顺序将其写入到一个DataNode中
(2) 文件读取
1) Client向NameNode发起文件读取请求
2) NameNode返回文件存储的DataNode信息
3) Client读取文件信息
(3) 文件块复制
1) NameNode发现部分文件的Block不符合最小复制数这一要求,或部分DataNode失效
2) 通知DataNode相互复制Block
3) DataNode开始直接相互复制
值得一提的是,文件在内部被分为多个文件块,这些Block分散存储在不同的DateNode上,每个Block还可以进行复制,一个Block会有三个备份,进而达到容错容灾的目的。
总结完HDFS后,我们下面介绍一下MapReduce的体系结构。
MapReduce的体系结构也是一个主从式的结构,主节点JobTracker只有一个,从节点TaskTracker有很多个。也就是说,MapReduce在Hadoop体系中,这一简单易用的软件框架(Map/Reduce框架)是有一个单独运行在主节点的JobTracker和运行在每个集群从节点的TackTracker共同组成的。
那么JobTracker和TackTracker这两个进程有何作用呢?
Hadoop中有一个作为主控的JobTracker,负责调度构成一个作业的所有任务。当一个Job被提交时,JobTracker接收到提交作业和其配置信息后,就会将Map任务和Reduce任务分发给空闲的TaskTracker,让这些任务并发运行,并负责监控任务的运行情况。而TaskTracker它必须运行于DataNode上,也就是说DataNode即是数据存储点,也是计算节点。如果某一个TaskTracker出了故障,JobTracker会将其负责的任务交给另一个空闲的TaskTracker重新运行。
最后,我们来说说MapReduce编程模型的原理(先了解一下,有个印象):利用一个key/value对集合产生一个输出的key/value对集合。MapReduce库的用户用两个函数来表达这个计算:Map和Reduce。
好了,不早了。Hadoop架构的初略总结(2)会讲解Hadoop2.0的框架,1.0和2.0的区别,尽可能的学习下YARN.YARN上课时听得我一脸懵逼。
参考文献: