JVM采用解释器和编译器并存的架构
Posted 写Bug的渣渣高
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JVM采用解释器和编译器并存的架构相关的知识,希望对你有一定的参考价值。
本文概述:
编译型语言和解释型语言分别是什么, 形象理解其特点
JVM 为什么需要解释器和编译器并存的架构
编译型语言和解释型语言
使用专门的编译器,针对特定的平台,将高级语言源代码一次性的编译成可被该平台硬件执行的执行文件,然后就可以直接执行了
- 特点: 总体效率高: 第一次可能会比解释器慢, 但是之后因为执行的是可执行文件, 之后执行可执行文件会快一些.
- 针对不同平台, 就需要使用不同的编译器和可执行文件, 而解释器相对只需要换一种方式直接解释成机器码.
解释型语言
使用专门的解释器对源程序进行逐行解释成特定平台的机器码并立即执行。
代码在每次执行之前被解释器一行一行动态翻译和执行,而不是执行之前就完成翻译
- 特点:总体效率低: 第一次可能会比编译型快, 因为解释型不需要生成可执行文件.
思维提升:
虽然你可能了解到了, 有些代码, 是解释执行更快. 但是如果举例子, 会更清楚:
比如说有些代码只会执行一次: 例如
- 类的构造器
- 生命周期方法, 例如 spring 中 bean 的 init-Method 方法等.
只执行一次的代码, 却要对其进行编译, 还要保存可执行文件, 肯定是不靠谱的.
JVM 采用解释器和编译器并存架构
JVM 采用的是混合模式, 总和解释执行和即时编译两者有点, 先解释执行字节码, 然后将其中反复执行的热点代码, 以方法为单位即时编译
- 即: 大部分不常用代码, 不编译成机器码, 而是直接解释执行
- 小部分热点代码, 编译成机器码, 达到理想的运行速度
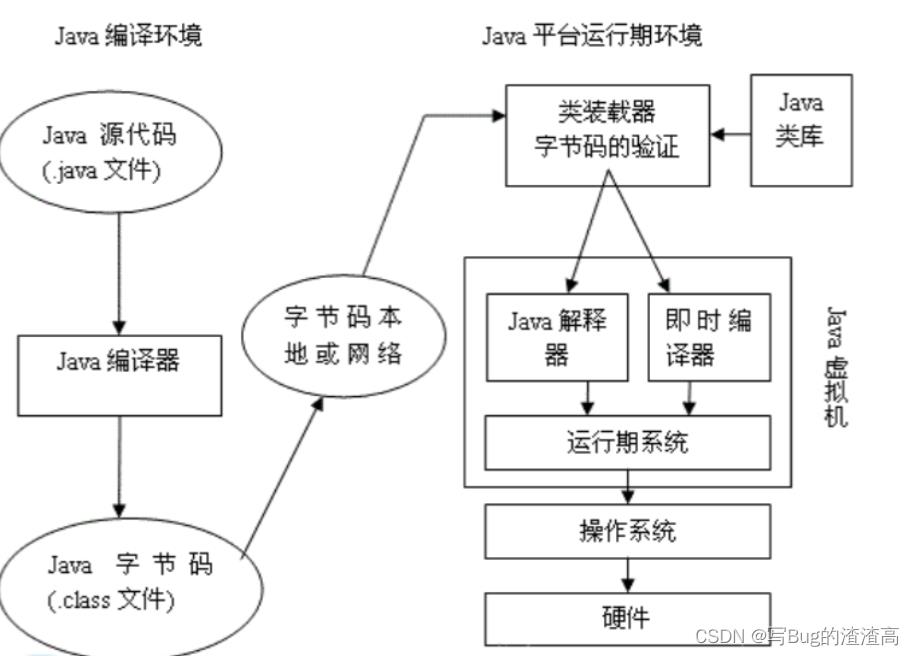
注意, 第一部分必须通过 Java 编译器编译成字节码, 字节码是 JVM 的核心.
而对于字节码到机器码, 则是可能有两种方式: 一种是 Java 解释器, 一种是即时编译器.
来看看解释器执行的流程:
代码 —> [解释器解释执行] —>执行结果
如果是 JIT 即时编译
第一次编译如下
代码 —> [编译器编译] --> 编译后代码 —> [执行] —> 执行结果.
第二次:
编译后代码 —> [执行] —> 执行结果
并且因为编译后的代码, 肯定是更接近底层的, 运行更快.
网上很多博主在这里, 可能是只讲了对于热点代码使用 JIT, 下面来看看哪些可能是热点代码.
- 被多次调用的代码
- 被多次执行的循环体
热点代码检测:
-
基于采样的热点检测
如果一个方法经常出现在栈顶, 那么就是热点方法. 这个方法比较简单高效. -
计数器
统计方法被调用的次数, 每次执行, 计数器加 1, 当方法调用次数超过阈值, 那么就通过 JIT 即时编译.
编译型和解释型回顾
- 当程序需要迅速启动, 那么解释器是可以起作用的, 因为其不需要保存文件, 直接运行
- 时间长了之后, 很多代码都会重复执行很多次, 每一次都重新来, 那不是很耗费性能
- 编译型语言总体效率高一些, 但是解释器相比说也会更节省内存
- 注意: 我们平时说的编译型语言更快,其实指的是总体的效率更高
- 注意: 我们平时说的 JIT 比解释型语言更快, 一般说的是执行编译后的代码比解释器解释执行更快. 对于编译这个行为, 如果只执行一次, 真不一定比解释要快
其实 Java 的解释器+编译器并存的架构, 其实还有些需要注意的地方
这里的编译器+解释器, 指的是 Java 解释器以及即时编译器. 这对应的是将字节码转换成底层代码的两种方式.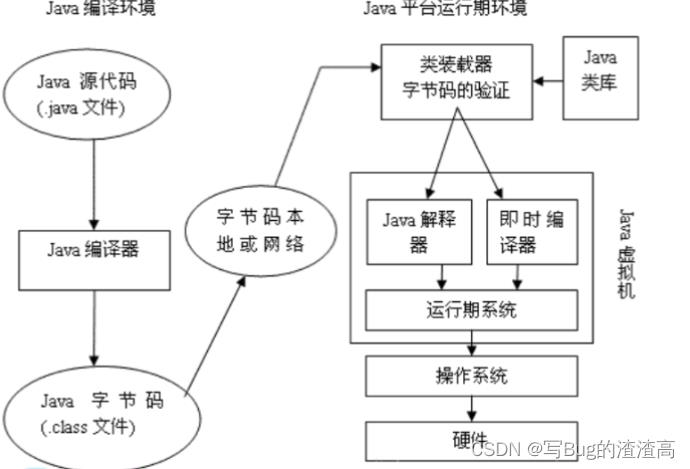
一定不要理解成生成字节码有两种形式
以上是关于JVM采用解释器和编译器并存的架构的主要内容,如果未能解决你的问题,请参考以下文章