做rl_abs过程中遇到的问题
Posted www-caiyin-com
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了做rl_abs过程中遇到的问题相关的知识,希望对你有一定的参考价值。
问题一
运行
train_abstractor.py就出现这个问题
nohup: ignoring input
start training with the following hyper-parameters:
{‘net‘: ‘base_abstractor‘, ‘net_args‘: {‘vocab_size‘: 30004, ‘emb_dim‘: 128, ‘n_hidden‘: 256, ‘bidirectional‘: True, ‘n_layer‘: 1}, ‘traing_params‘: {‘optimizer‘: (‘adam‘, {‘lr‘: 0.001}), ‘clip_grad_norm‘: 2.0, ‘batch_size‘: 32, ‘lr_decay‘: 0.5}}
Start training
/root/anaconda3/envs/jjenv_pytorch/lib/python3.6/site-packages/torch/nn/functional.py:52: UserWarning: size_average and reduce args will be deprecated, please use reduction=‘none‘ instead.
warnings.warn(warning.format(ret))
Traceback (most recent call last):
File "train_abstractor.py", line 220, in <module>
main(args)
File "train_abstractor.py", line 166, in main
trainer.train()
File "/data/rl_abs_other/fast_abs_rl/training.py", line 211, in train
log_dict = self._pipeline.train_step()
File "/data/rl_abs_other/fast_abs_rl/training.py", line 107, in train_step
log_dict.update(self._grad_fn())
File "/data/rl_abs_other/fast_abs_rl/training.py", line 20, in f
grad_norm = grad_norm.item()
AttributeError: ‘float‘ object has no attribute ‘item‘
然后把pytorch0.4.1换为0.4.0版本后就解决了如上的问题.
问题二
运行
train_full_rl.py的过程中出现如下问题,
train step: 6993, reward: 0.4023
train step: 6994, reward: 0.4021
train step: 6995, reward: 0.4025
train step: 6996, reward: 0.4023
train step: 6997, reward: 0.4024
train step: 6998, reward: 0.4025
train step: 6999, reward: 0.4024
train step: 7000, reward: 0.4024
start running validation...Traceback (most recent call last):
File "train_full_rl.py", line 228, in <module>
train(args)
File "train_full_rl.py", line 182, in train
trainer.train()
File "/data/rl_abs_other/fast_abs_rl/training.py", line 216, in train
stop = self.checkpoint()
File "/data/rl_abs_other/fast_abs_rl/training.py", line 185, in checkpoint
val_metric = self.validate()
File "/data/rl_abs_other/fast_abs_rl/training.py", line 171, in validate
val_log = self._pipeline.validate()
File "/data/rl_abs_other/fast_abs_rl/rl.py", line 178, in validate
return a2c_validate(self._net, self._abstractor, self._val_batcher)
File "/data/rl_abs_other/fast_abs_rl/rl.py", line 26, in a2c_validate
for art_batch, abs_batch in loader:
File "/root/anaconda3/envs/jjenv_pytorch040/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 451, in __iter__
return _DataLoaderIter(self)
File "/root/anaconda3/envs/jjenv_pytorch040/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 239, in __init__
w.start()
File "/root/anaconda3/envs/jjenv_pytorch040/lib/python3.6/multiprocessing/process.py", line 105, in start
self._popen = self._Popen(self)
File "/root/anaconda3/envs/jjenv_pytorch040/lib/python3.6/multiprocessing/context.py", line 223, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "/root/anaconda3/envs/jjenv_pytorch040/lib/python3.6/multiprocessing/context.py", line 277, in _Popen
return Popen(process_obj)
File "/root/anaconda3/envs/jjenv_pytorch040/lib/python3.6/multiprocessing/popen_fork.py", line 19, in __init__
self._launch(process_obj)
File "/root/anaconda3/envs/jjenv_pytorch040/lib/python3.6/multiprocessing/popen_fork.py", line 66, in _launch
self.pid = os.fork()
OSError: [Errno 12] Cannot allocate memory
nohup: ignoring input
Warning: METEOR is not configured
loading checkpoint ckpt-2.530862-102000...
loading checkpoint ckpt-2.498729-24000...
loading checkpoint ckpt-2.530862-102000...
Traceback (most recent call last):
File "train_full_rl.py", line 228, in <module>
train(args)
File "train_full_rl.py", line 148, in train
os.makedirs(join(abs_dir, ‘ckpt‘))
File "/root/anaconda3/envs/jjenv_pytorch040/lib/python3.6/os.py", line 220, in makedirs
mkdir(name, mode)
FileExistsError: [Errno 17] File exists: ‘/data/rl_abs_other/fast_abs_rl/full_rl_model/abstractor/ckpt‘
经过google后,说是线程开太多导致的,然后我就train_full_rl.py把其中的
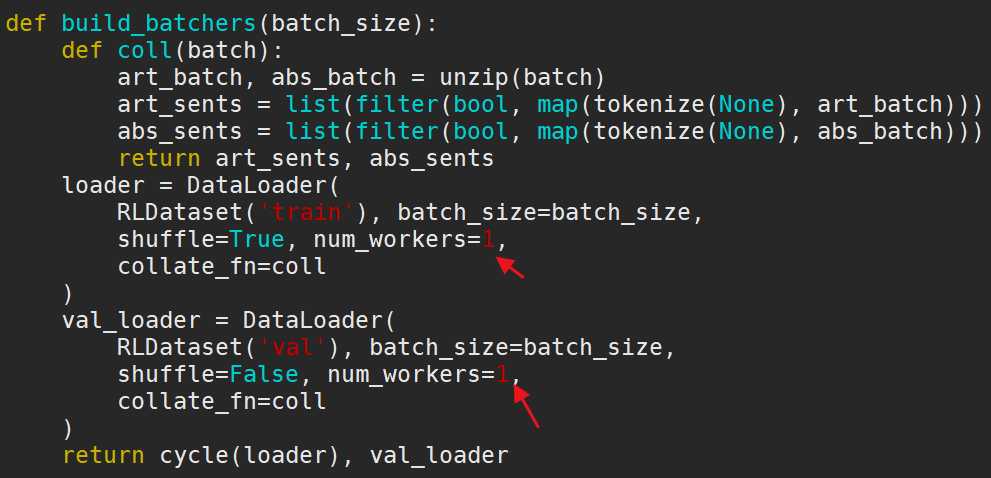
从4改为1. 这样再次运行就可以了。
问题三
nohup: ignoring input
THCudaCheck FAIL file=/opt/conda/conda-bld/pytorch_1524586445097/work/aten/src/THC/generic/THCStorage.cu line=58 error=2 : out of memory
Warning: METEOR is not configured
loading checkpoint ckpt-2.530862-102000...
loading checkpoint ckpt-2.498729-24000...
loading checkpoint ckpt-2.530862-102000...
start training with the following hyper-parameters:
{‘net‘: ‘rnn-ext_abs_rl‘, ‘net_args‘: {‘abstractor‘: {‘net‘: ‘base_abstractor‘, ‘net_args‘: {‘vocab_size‘: 30004, ‘emb_dim‘: 128, ‘n_hidden‘: 256, ‘bidirectional‘: True, ‘n_layer‘: 1}, ‘traing_params‘: {‘optimizer‘: [‘adam‘, {‘lr‘: 0.001}], ‘clip_grad_norm‘: 2.0, ‘batch_size‘: 32, ‘lr_decay‘: 0.5}}, ‘extractor‘: {‘net‘: ‘ml_rnn_extractor‘, ‘net_args‘: {‘vocab_size‘: 30004, ‘emb_dim‘: 128, ‘conv_hidden‘: 100, ‘lstm_hidden‘: 256, ‘lstm_layer‘: 1, ‘bidirectional‘: True}, ‘traing_params‘: {‘optimizer‘: [‘adam‘, {‘lr‘: 0.001}], ‘clip_grad_norm‘: 2.0, ‘batch_size‘: 32, ‘lr_decay‘: 0.5}}}, ‘train_params‘: {‘optimizer‘: (‘adam‘, {‘lr‘: 0.0001}), ‘clip_grad_norm‘: 2.0, ‘batch_size‘: 32, ‘lr_decay‘: 0.5, ‘gamma‘: 0.95, ‘reward‘: ‘rouge-l‘, ‘stop_coeff‘: 1.0, ‘stop_reward‘: ‘rouge-1‘}}
Start training
train step: 1, reward: 0.1918^MTraceback (most recent call last):
File "train_full_rl.py", line 228, in <module>
train(args)
File "train_full_rl.py", line 182, in train
trainer.train()
File "/data/rl_abs_other/fast_abs_rl/training.py", line 211, in train
log_dict = self._pipeline.train_step()
File "/data/rl_abs_other/fast_abs_rl/rl.py", line 173, in train_step
self._stop_reward_fn, self._stop_coeff
File "/data/rl_abs_other/fast_abs_rl/rl.py", line 64, in a2c_train_step
summaries = abstractor(ext_sents)
File "/data/rl_abs_other/fast_abs_rl/decoding.py", line 94, in __call__
decs, attns = self._net.batch_decode(*dec_args)
File "/data/rl_abs_other/fast_abs_rl/model/copy_summ.py", line 63, in batch_decode
attention, init_dec_states = self.encode(article, art_lens)
File "/data/rl_abs_other/fast_abs_rl/model/summ.py", line 81, in encode
init_enc_states, self._embedding
File "/data/rl_abs_other/fast_abs_rl/model/rnn.py", line 41, in lstm_encoder
lstm_out = reorder_sequence(lstm_out, reorder_ind, lstm.batch_first)
File "/data/rl_abs_other/fast_abs_rl/model/util.py", line 58, in reorder_sequence
sorted_ = sequence_emb.index_select(index=order, dim=batch_dim)
RuntimeError: cuda runtime error (2) : out of memory at /opt/conda/conda-bld/pytorch_1524586445097/work/aten/src/THC/generic/THCStorage.cu:58
应该是显存不够了。之前上一次运行都行,不可能这一次就突然显存不够了,于是重启云GPU。然后重新运行。问题消失,程序跑出正确结果。
以上是关于做rl_abs过程中遇到的问题的主要内容,如果未能解决你的问题,请参考以下文章