一提mesos,很多人知道双层调度,但是大多数理解都在表面,不然试一下下面五个问题。
问题一:如果有两个framework,一万个节点,按说应该平均分配给两个framework,怎么个分法?一人一台这样分,还是前五千给一人,后五千给第二个人,还是随机分,随机分怎么个分法?
问题二:在没有reserved情况下,每个节点是只能得给一个framework,还是可以分给多个framework?
问题三:如果两个framework的权重比例为1比2,是如何保证资源分配是这个比例?
问题四:如果两个framework的权重比例为1比2,当第二个用完了三分之二,在第一个没有任务运行的时候,第二个能多用一些么?如何平衡别人不用多用,别人要用保持比例呢?
问题五:将资源提供给多个framework的时候,是一个节点的资源给第一个framework,第一个framework说我不用,然后再给第二个framework么?
好了,接下来我们来看Mesos双层调度的基本原理。
一、入门级理解Mesos双层调度
Mesos的调度过程如图所示:
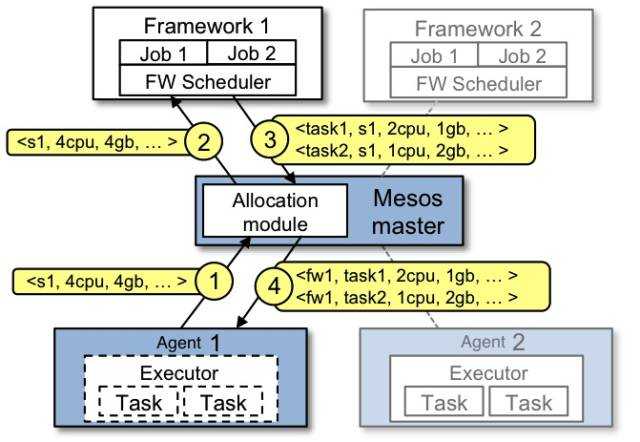
Mesos有Framework, Master, Agent, Executor, Task几部分组成。这里面有两层的Scheduler,一层在Master里面,allocator会将资源公平的分给每一个Framework,二层在Framework里面,Framework的scheduler将资源按规则分配给Task。
二、进阶级理解Mesos双层调度
Mesos采用了DRF(主导资源公平算法 Dominant Resource Fairness),Framework拥有的全部资源类型份额中占最高百分比的就是Framework的主导份额。DRF算法会使用所有已注册的Framework来计算主导份额,以确保每个Framework能接收到其主导资源的公平份额。
举个例子
考虑一个9CPU,18GBRAM的系统,拥有两个用户,其中用户A运行的任务的需求向量为{1CPU, 4GB},用户B运行的任务的需求向量为{3CPU,1GB},用户可以执行尽量多的任务来使用系统的资源。
在上述方案中,A的每个任务消耗总cpu的1/9和总内存的2/9,所以A的dominant resource是内存;B的每个任务消耗总cpu的1/3和总内存的1/18,所以B的dominant resource为CPU。DRF会均衡用户的dominant shares,执行3个用户A的任务,执行2个用户B的任务。三个用户A的任务总共消耗了{3CPU,12GB},两个用户B的任务总共消耗了{6CPU,2GB};在这个分配中,每一个用户的dominant share是相等的,用户A获得了2/3的RAM,而用户B获得了2/3的CPU。
以上的这个分配可以用如下方式计算出来:x和y分别是用户A和用户B的分配任务的数目,那么用户A消耗了{xCPU,4xGB},用户B消耗了{3yCPU,yGB},在图三中用户A和用户B消耗了同等dominant resource;用户A的dominant share为4x/18,用户B的dominant share为3y/9。所以DRF分配可以通过求解以下的优化问题来得到:
max(x,y) #(Maximize allocations)
subject to
x + 3y <= 9 #(CPU constraint)
4x + y <= 18 #(Memory Constraint)
2x/9 = y/3 #(Equalize dominant shares)
最后解出x=3以及y=2,因而用户A获得{3CPU,12GB},B得到{6CPU, 2GB}。
三、代码级理解Mesos双层调度
首先理解几个概念容易混淆:Quota, Reservation, Role, Weight
-
每个Framework可以有Role,既用于权限,也用于资源分配
-
可以给某个role在offerResources的时候回复Offer::Operation::RESERVE,来预订某台slave上面的资源。Reservation是很具体的,具体到哪台机器的多少资源属于哪个Role
-
Quota是每个Role的最小保证量,但是不具体到某个节点,而是在整个集群中保证有这么多就行了。
-
Reserved资源也算在Quota里面。
-
不同的Role之间可以有Weight
Mesos的代码实现中,不是用原生的DRF,而是使用HierarchicalDR,也即分层的DRF.
调用了三个排序器Sorter(quotaRoleSorter, roleSorter, frameworkSorter),对所有的Framework进行排序,哪个先得到资源,哪个后得到资源。
总的来说分两大步:先保证有quota的role,调用quotaRoleSorter,然后其他的资源没有quota的再分,调用roleSorter。
对于每一个大步分两个层次排序:一层是按照role排序,第二层是相同的role的不同Framework排序,调用frameworkSorter。
每一层的排序都是按照计算的share进行排序来先给谁,再给谁。Share的计算就是按照DRF算法。
接下来我们具体分析一下这个资源分配的过程。
1. 生成一个数据结构offerable,用于保存资源分配的结果
hashmap<FrameworkID, hashmap<SlaveID, Resources>> offerable;
这是一个MAP,对于每一个Framework,都会有一个资源的MAP,保存的是每个slave上都有哪些资源。
2. 对于所有的slave打乱默认排序,从而使得资源分配相对均匀
std::random_shuffle(slaveIds.begin(), slaveIds.end());
3. 进行第一次三层循环,对于有quota的Framework进行排序
-
foreach (const SlaveID& slaveId, slaveIds) {
-
foreach (const string& role, quotaRoleSorter->sort()) {
-
foreach (const string& frameworkId_, frameworkSorters[role]->sort()) {
对于每一个slave,首先对role进行排序,对于每一个role,对于Framework进行排序,排序靠前的Framework优先获得这个slave。
排序的算法在DRFSorter里面实现,里面有一个函数calculateShare,里面的关键点在于进行了一个循环,对于每一种资源都计算如下的share值:
share = std::max(share, allocation / _total);
allocation除以total即一种资源占用的百分比,这里之所以求max,就是找资源占用百分比最高的资源,也即主导资源。
但是这个share不是直接进行排序,而是share / weights[name]除以权重进行排序。如果权重越大,这个值越小,这个role会排在前面,分配更多的资源。
排序结束后,对于每一个Framework,将当前slave的资源分配给它。
Resources available = slaves[slaveId].total - slaves[slaveId].allocated;
首先查看这个slave的可用资源,也即总资源减去已经分配的资源。
Resources resources = (available.unreserved() + available.reserved(role)).nonRevocable();
每个slave上没有预留的资源和已经预留给这个Framework的资源都会给这个Framework,当然如果上面有预留给其他Framework的资源是不会给当前的Framework的。
offerable[frameworkId][slaveId] += resources;
slaves[slaveId].allocated += resources;
分配的资源会保存在数据结构offerable中。
4. 进行第二次三层循环,对于没有quota的Framework进行排序
-
foreach (const SlaveID& slaveId, slaveIds) {
-
foreach (const string& role, roleSorter->sort()) {
-
foreach (const string& frameworkId_,frameworkSorters[role]->sort()) {
5. 全部分配结束后,将资源真正提供给各个Framework
-
foreachkey (const FrameworkID& frameworkId, offerable) {
-
offerCallback(frameworkId, offerable[frameworkId]);
-
}
这里的offerCallback是调用Master::Offer,最终调用Framework的Scheduler的resourceOffers,让Framework进行二次调度。
最后,让我们来解答一下这些问题:
问题一:如果有两个framework,一万个节点,按说应该平均分配给两个framework,怎么个分法?一人一台这样分,还是前五千给一人,后五千给第二个人,还是随机分,随机分怎么个分法?
答:是随机分,怎么分呢?是将节点随机排序,但是排好序之后,就不再随机分了,而是开始排序,比如随机后的节点队列中的第一个节点分给了第一个framework,等下次循环再排序的时候,第二个framework由于没有拿到资源,排在了第一个framework的前面,于是第二个节点就分配给了第二个framework,然后for循环到第三个节点的时候(这是外层循环),内层循环对framework排序的时候,第一个framework又排在了第二个前面,于是第三个节点分给了第一个framework。就这样你一个,我一个,实现了平均分配。
问题二:在没有reserved情况下,每个节点是只能得给一个framework,还是可以分给多个framework?
答:是的,在没有reserved的情况下,一个节点是只给一个framework,如果有reserved的情况下,reserved的那部分会给reserve它的那个framework,其他的部分,还是只能给一个framework,不一定是哪一个,看谁排在前面。
问题三:如果两个framework的权重比例为1比2,是如何保证资源分配是这个比例?
答:也是通过排序来的,对节点的for循环是外层循环,对framework的排序和循环是内层循环,第一次排序的时候,权重为2的framework排在前面,于是第一个节点是它的,第二次排序的时候,还是权重为2的framework排在前面,于是第二个节点也是它的,第三次排序的时候,权重为1的framework由于从来没拿到过资源,排在了前面,于是第三个节点是它的。就这样你两个,我一个,你两个,我一个,实现了资源按权重分配。
问题四:如果两个framework的权重比例为1比2,当第二个用完了三分之二,在第一个没有任务运行的时候,第二个能多用一些么?如何平衡别人不用多用,别人要用保持比例呢?
答:能的。如果权重为2的framework用完了三分之二,则每次排序,它都会排在权重为1的但是没有得到资源的framework后面,按说它永远得不到资源。但是算法中会有一个filter机制,当一个节点分给某一个framework之后,如果这个framework不用,退回来,则下次再遇到这个framework的时候,先filter掉,这样另一个framework就有机会得到这个节点了。下次又不会filter掉了。
问题五:将资源提供给多个framework的时候,是一个节点的资源给第一个framework,第一个framework说我不用,然后再给第二个framework么?
答:不是的。统一运行一遍分配算法,把资源都全部分配好,才统一发送给framework,如果需要再次分配,是下次统一计算的时候了。
欢迎关注微信公众号
