搜狗新闻原始数据处理
Posted strangewx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搜狗新闻原始数据处理相关的知识,希望对你有一定的参考价值。
简介:
下载的是搜狗新闻一个月版本的SogouCS.reduced,大约698M,包含128个txt文件
主要处理包括:转码,提取content和URL
处理之前:
每个文件中每条内容如下xml格式:
<doc> <url>http://sports.sohu.com/20080627/n257795172_4.shtml</url> <docno>215799a267c29427-71013306c0bb3300</docno> <contenttitle>组图:蕊蕊拦网薛明暴扣 陈忠和发布会笑逐颜开</contenttitle> <content>跳转至:R常担26N依此盗骄潺1本┦奔洌对拢玻啡眨2008年世界女排大奖赛第二周比赛继续进行,在中国香港站的一场焦点大战中,中国女排苦战五局,以3-2(25-18、25-27、21-25、25-21、15-13)击败了不久前在瑞士女排精英赛3-1战胜过自己的古巴女排,赢得中国香港站开门红。图为比赛精彩画面。#ㄔ鹑伪嗉:王燕芳)>彩图片</content> </doc>
处理之后:
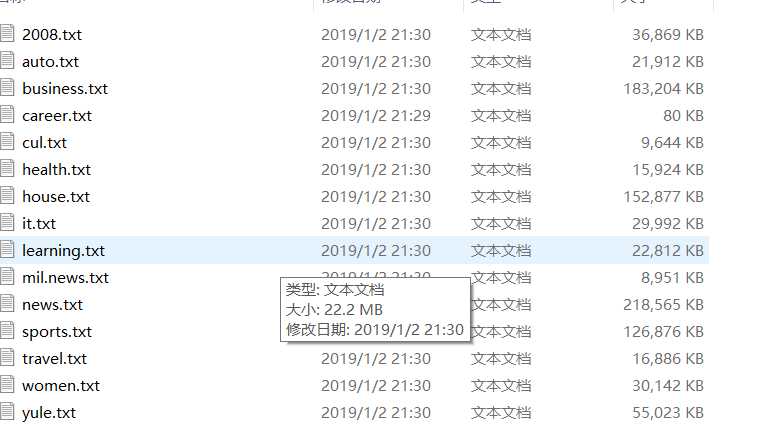
共:15类别。数据分布不均匀,猜测和各类新闻热度有关。
后续分析:
待补充
代码如下:
(1)包括转码和提取数据
# -*- coding: utf-8 -*- ‘‘‘ 该脚本用于将搜狗语料库新闻语料 转化为按照URL作为类别名、 content作为内容的txt文件存储 ‘‘‘ import os import re ‘‘‘字符数小于这个数目的content将不被保存‘‘‘ threh = 30 ‘‘‘获取原始语料文件夹下文件列表‘‘‘ def listdir_get(path, list_name): """ :desc: get data of raw data :input: data of dir, list of slice data path """ for file in os.listdir(path): file_path = os.path.join(path, file) if os.path.isdir(file_path): listdir_get(file_path, list_name) else: list_name.append(file_path) ‘‘‘ #修改文件编码为utf-8 from chardet import detect def code_transfer(list_name): for fn in list_name: with open(fn, ‘rb+‘) as fp: content = fp.read() codeType = detect(content)[‘encoding‘] content = content.decode(codeType, "ignore").encode("utf8") fp.seek(0) fp.write(content) print(fn, ":已修改为utf8编码") ‘‘‘ def processing(list_name): ‘‘‘对每个语料‘‘‘ for path in list_name: print(path+‘---start---‘) file = open(path, ‘rb‘).read().decode("utf8") ‘‘‘ 正则匹配出url和content ‘‘‘ patternURL = re.compile(r‘<url>(.*?)</url>‘, re.S) patternCtt = re.compile(r‘<content>(.*?)</content>‘, re.S) classes = patternURL.findall(file) contents = patternCtt.findall(file) ‘‘‘将内容小于30的去除‘‘‘ for i in reversed(range(contents.__len__())): #如果是reversed (len(range(5))),这种索引是按从大到小的顺序排列, #列表不要随便删除,python会自动增补,导致索引变少 if len(contents[i]) < threh: contents.pop(i) classes.pop(i) ‘‘‘进一步取出URL作为样本标签‘‘‘ for i in range(classes.__len__()): patterClass = re.compile(r‘http://(.*?).sohu.com/‘, re.S) classi = patterClass.findall(classes[i]) classes[i] = classi[0] ‘‘‘按照URL作为类别存储到处理后文件夹‘‘‘ for i in range(len(classes)): file = data_original_path + ‘\\processed\\‘ + classes[i] + ‘.txt‘ with open(file, ‘a+‘, encoding=‘utf-8‘)as f: f.write(contents[i]+‘ ‘) print(path+‘---success---‘) if __name__==‘__main__‘: print("----tast start----") #原始语料路径 data_original_path = "D:\\software_study\\nlp_data\\SogouCS.reduced\\" #data_original_path = ‘./SogouCS.reduced/‘ #获取文件路径 list_name = [] listdir_get(data_original_path,list_name) #修改编码 #code_transfer(listname) processing(list_name) print(‘----task success----‘)
(2)主要是转码,本人在实际中分开进行的
#-*- coding:utf-8 -*- import os from chardet import detect data_original_path = "D:\\software_study\\nlp_data\\SogouCS.reduced" ‘‘‘生成原始语料文件夹下文件列表‘‘‘ def listdir(path, list_name): """ :desc: get data of raw data :input: data of dir, list of slice data path """ for file in os.listdir(path): file_path = os.path.join(path, file) if os.path.isdir(file_path): listdir(file_path, list_name) else: list_name.append(file_path) ‘‘‘获取所有语料‘‘‘ list_name = [] listdir(‘D:\\software_study\\nlp_data\\SogouCS.reduced\\‘,list_name) print(list_name) for fn in list_name: with open(fn, ‘rb+‘) as fp: content = fp.read() codeType = detect(content)[‘encoding‘] content = content.decode(codeType, "ignore").encode("utf8") fp.seek(0) fp.write(content) print(fn, ":已修改为utf8编码")
以上是关于搜狗新闻原始数据处理的主要内容,如果未能解决你的问题,请参考以下文章
《java精品毕设》基于javaweb宠物领养平台管理系统(源码+毕设论文+sql):主要实现:个人中心,信息修改,填写领养信息,交流论坛,新闻,寄养信息,公告,宠物领养信息,我的寄养信息等(代码片段