AAAI2021-Hierarchical Reinforcement Learning for Integrated Recommendation
Posted 吾仄lo咚锵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AAAI2021-Hierarchical Reinforcement Learning for Integrated Recommendation相关的知识,希望对你有一定的参考价值。
文章目录
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。
介绍
Xie R, Zhang S, Wang R, et al. Hierarchical reinforcement learning for integrated recommendation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(5): 4521-4528.
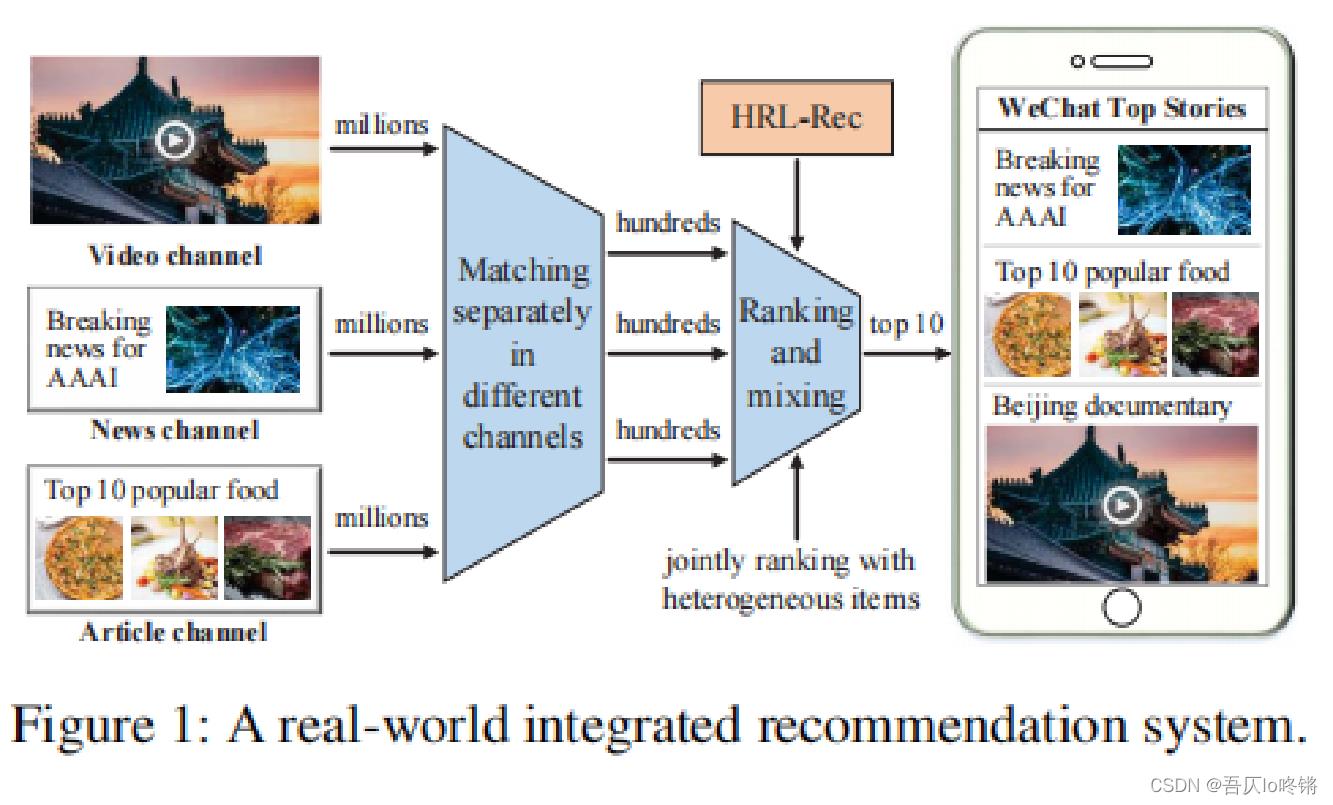
如图1是一个真实世界中综合的推荐系统,它首先从不同的频道中集成了不同的项目(比如视频、新闻、文章),然后对这些项目进行排序并完成综合推荐。
综合推荐中面临着许多挑战:
- 不同的项目有不同的特征,对应着不同的排序策略。
- 如何学习用户在频道和项目两个层面上的偏好。
- 如何保证在线模型的稳定性?也就是随着数据的更新,模型应保持个频道占比的相对稳定。
而本文所提出的方法解决了上述挑战,并具有如下优势:
- 有效的找到最优解。
- 多种奖励来确保推荐的准确性、多样性和新颖性。
- 对频道和项目进行了解耦合。
本文贡献如下:
- 提出了一个新的HRL-Rec(基于分层强化学习的推荐)模型。
- 提出了一个新的HRL(分层强化学习)框架。
- 通过实验验证了该模型的有效性和稳定性。
相关工作
-
推荐系统
一些经典方法:Logistic regression(LR)、Factorization machine(FM)
LR+DNN:Wide&Deep
FM+DNN:DeepFM、NFM、AFM
更好提取特征:AutoInt、AFN、AutoFIS
更好建模用户行为:BERT4Rec、DFN -
强化学习
基于策略的:Policy gradient(PG)
基于价值的:Deep Q-network(DQN)、Double、Dueling
基于策略和价值的:A3C、DDPG -
用于推荐的强化学习
相关方法有:
DQN+用户活跃度
神经网络来模拟奖励
对抗训练
RL+监督方法
PG+top-k off policy
基于模板的Q学习
其中,本文主要参考了DDPG(Deep Deterministic Policy Gradient),主要思想是通过两个网络分别学习产生动作和价值,即:
Actor Network -> action
Critic Network -> value(Q)
方法论
问题定义和模型概览
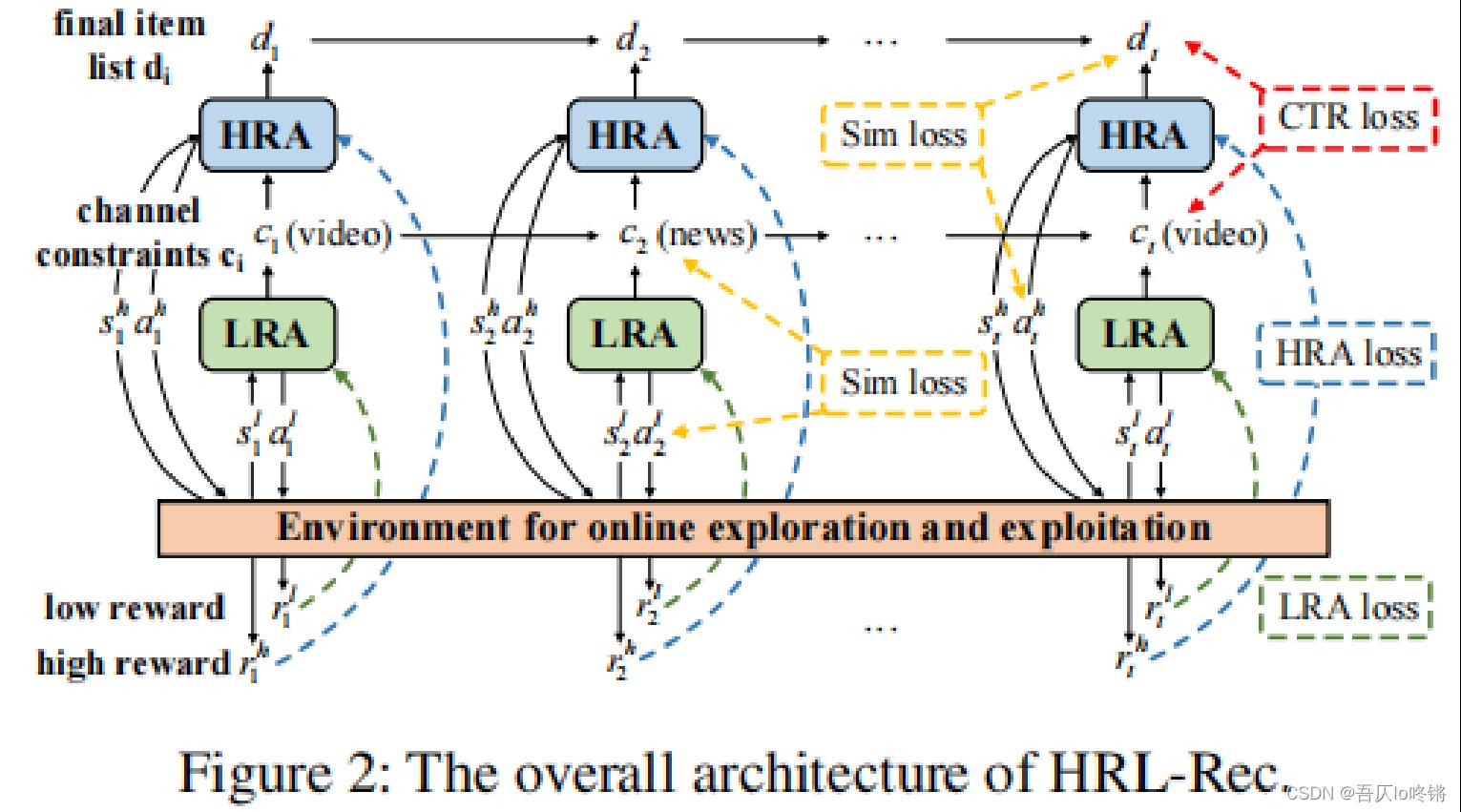
图2是HRL-Rec模型的整体概览,首先介绍相关符号:
低级状态:
s
l
s^l
sl
低级动作:
a
l
a^l
al
低级奖励:
r
l
r^l
rl
低级状态:
s
h
s^h
sh
低级动作:
a
h
a^h
ah
低级奖励:
r
h
r^h
rh
衰减系数: γ ∈ [ 0 , 1 ] \\gamma \\in [0,1] γ∈[0,1]
模型产生推荐的流程大致如下:
- LRA(低级学习代理)在第 t t t个位置根据状态 s t l s^l_t stl生成动作 a t l a^l_t atl来推荐一个频道 c t c_t ct。
- HRA(高级学习代理)在频道 c t c_t ct的约束下,根据状态 s t h s^h_t sth生成动作 a t h a^h_t ath,得到对应项目 d t d_t dt。
- 环境接收到频道 c t c_t ct和项目 d t d_t dt,然后返回对应的奖励( r t l r_t^l rtl和 r t h r_t^h rth)给到对应的代理器。
- 最后更新状态,重复循环。
对于LRA、HRA以及图中相关损失后面会介绍。
频道选择器(LRA)
低级强化学习代理是一个频道选择器,由以下3部分组成:
-
低级状态编码器
也就是对数据进行建模,提取特征。使用a)用户长期档案、b)推荐上下文、c)当前频道特征、d)累计频道特征,这四方面构建特征矩阵 f i l f^l_i fil。
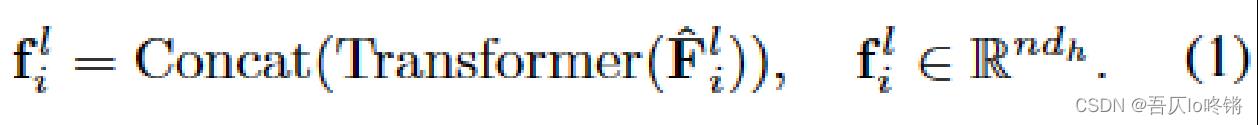
使用GRU和self-attention对若干 f f f序列进行建模,得到低级状态 s t l s_t^l stl:
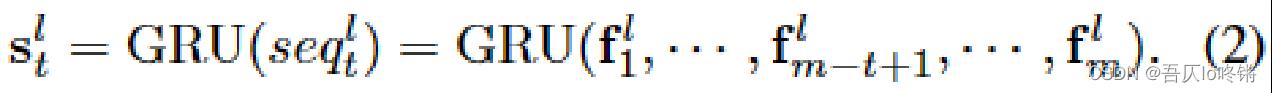
具体细节可查看原文及对应参考文献。 -
低级编码器
使用了一个全连接层作为编码器,通过低级状态 s t l s_t^l stl得到低级动作 a t l a_t^l atl:
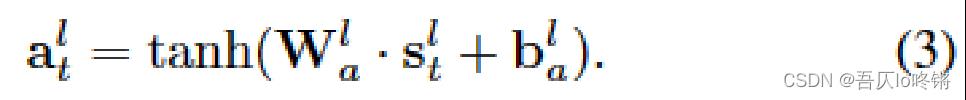
具体使用的是tanh作为激活函数,并且添加了高斯噪音。
得到若干低级动作 a l a^l al后,后面用过相似度损失sim loss,选择与目标最相似的一个低级动作作为输出,即选择的频道,即 a t l − − s i m l o s s − − > c t a_t^l --sim loss-->c_t atl−−simloss−−>ct。 -
低级评估器
Q值表示当前步的期望奖励,需要一点强化学习背景,也就是当前奖励 r t l r_t^l rtl+下一步奖励(衰减系数* Q t + 1 Q_t+1 Qt+1)的期望。此处的奖励 r t l r_t^l rtl表示的是点击频道 c t c_t ct的次数。
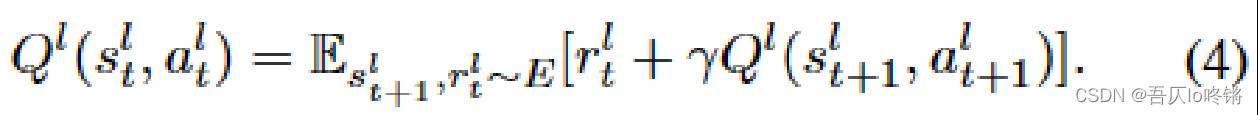
使用一个全连接层,用小q来估计大Q:
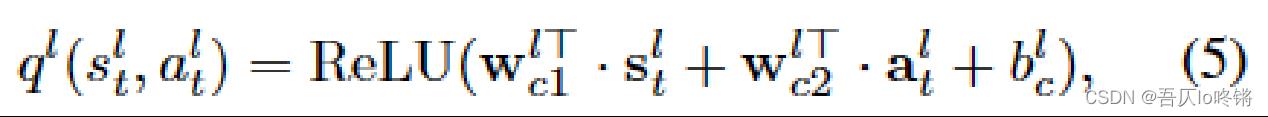
就是对状态和动作分别乘以权重参数后再加上偏置参数,最后使用ReLu激活函数。
项目推荐器(HRA)
高级强化学习代理是一个项目推荐器,与LRA很相似,也由3部分组成:
-
高级状态编码器
与LRA相似,只是将频道特征换成了项目特征。 -
高级编码器
也是一个全连接层:
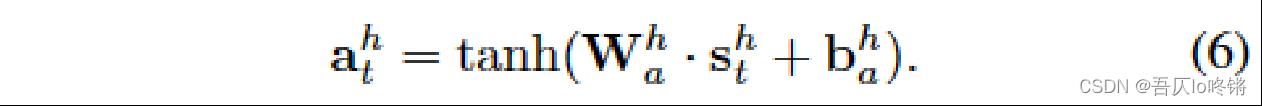
使用相似度损失,在若干高级代理中,得到最相似的作为推荐的项目 d t d_t dt,即 a h l − − s i m l o s s − − > d t a_h^l --sim loss-->d_t ahl−−simloss−−>dt。 -
高级评估器
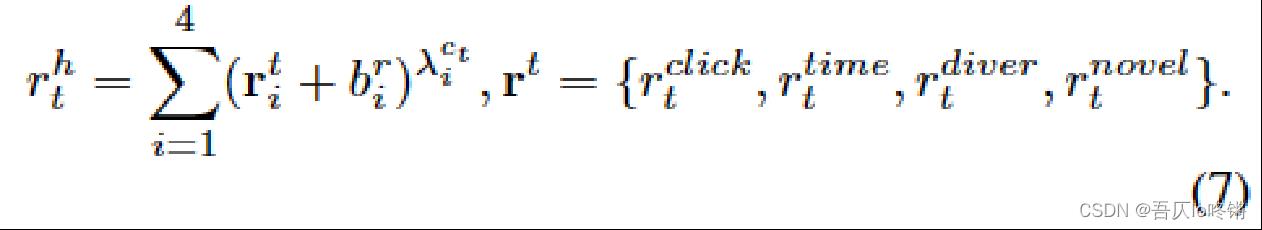
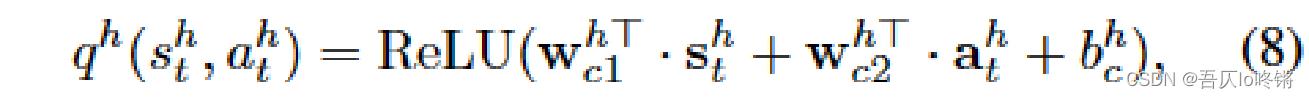
与LRA相似,不再赘述,只是将奖励换了下,其中:
r t c l i c k r_t^click rtclick表示用户点击项目 d t d_t dt的次数;
r t t i m e r_t^time rttime表示在项目 d t d_t dt上的停留时间;
r t d i v e r r_t^diver rtdiver表示标签/类别的增量;
r t n o v e l r_t^novel rtnovel表示新标签/类别的数量;
损失函数
-
LRA loss
公式9采用均方误差作来衡量低级评估器的损失。其中, y t l y_t^l ytl表示目标Q值; π \\pi π表示目标策略; θ l \\theta^l θl表是一个在线参数,在训练过程中进行更新; θ l ′ \\theta^l' θl′是一个经验参数,在进行优化前固定。
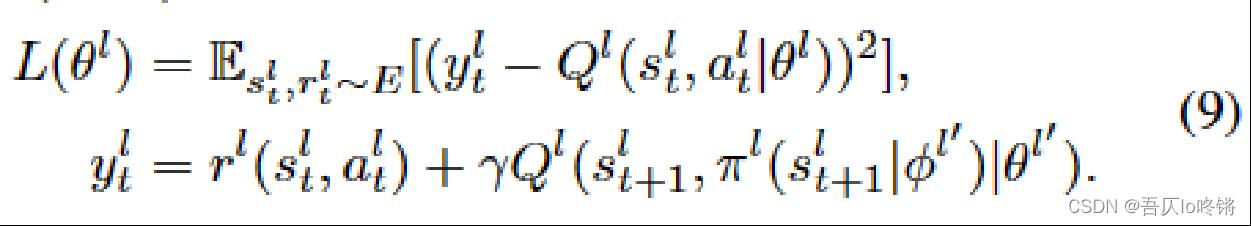
公式10通过学习参数 ϕ h \\phi^h ϕh作为低级动作的损失函数,希望奖励最大化,也就是最小化-Q:
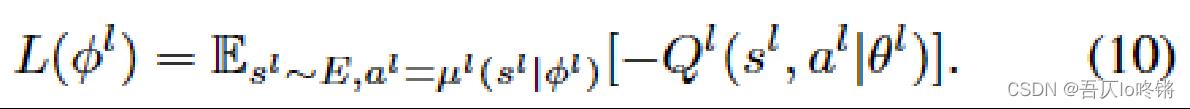
最后通过公式11作为LRA loss,低级强化学习代理的损失函数:
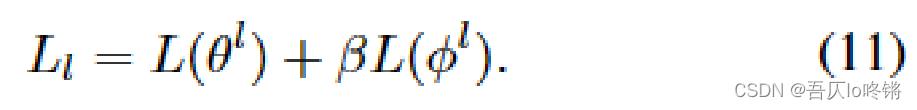
-
HRA loss
HRA loss高级强化学习代理器的损失与LRA loss基本一致,不再赘述:
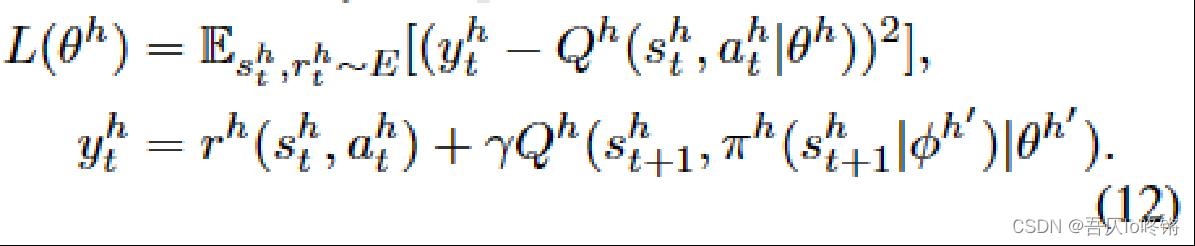
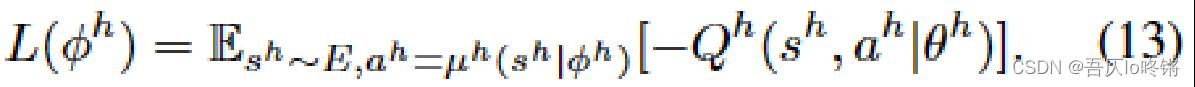
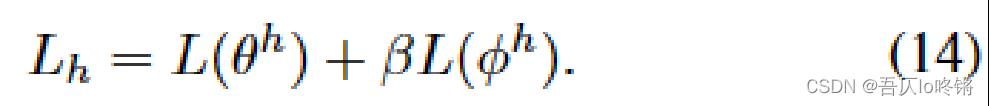
-
CTR-oriented supervised loss
点击通过率监督损失,也就是推荐并展示的项目中,有多少是用户点击了的(推荐成功了的)。
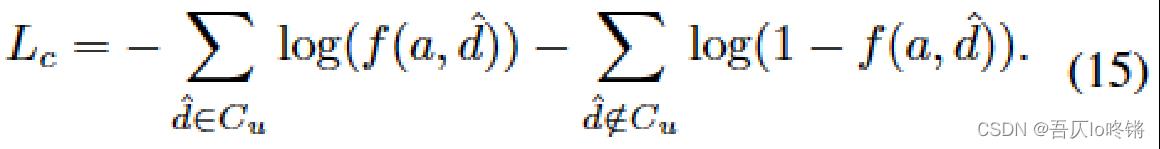

其中, a a a是预测的(推荐的)动作;
d ^ \\hatd d^是展示给用户的真实项目;
d ^ ∈ C u \\hatd\\in C_u d^∈Cu表示被用户 u u u点击的项目 d ^ \\hatd d^;
f ( a , d ^ ) f(a,\\hatd) f(a,