对seq2seq的粗浅认识
Posted jtay
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对seq2seq的粗浅认识相关的知识,希望对你有一定的参考价值。
本文从三个方面进行展开:
第一部分,介绍seq2seq在整个RNN体系中的情况。
第二部分,介绍seq2seq结构的基本原理。
第三部分,介绍seq2seq的缺点,和由此引出的Attention机制。
第一部分:
RNNs:Recurrent neural network 翻译成循环神经网络
Bidirectional RNNs: 双向RNNs
Deep Bidirectional RNNs:深度双向RNNs
LSTM:Long short term memory
GRU:Gated Recurrent Unit
解释:
传统的神经网络很难解决基于先前事件推断后续事件的问题。
RNNs是包含循环的网络,允许信息的持久化,解决了以上问题。
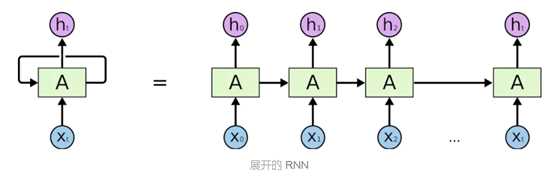
裸RNNs无法利用当前词语的下文辅助分类决策,解决方法是使用一些更复杂的RNN变种,如Bidirectional RNNs,Deep Bidirectional RNNs,使每个时刻不但接受上个时刻的特征向量,还接受来自下层的特征表示。
RNNs存在的问题:在相关信息和当前预测位置之间的间隔相当长时,训练RNN变得相当困难。
LSTM,作为一种特殊的RNN,可以学习长期依赖信息,避免了RNNs存在的问题。
GRU是LSTM的简化版。
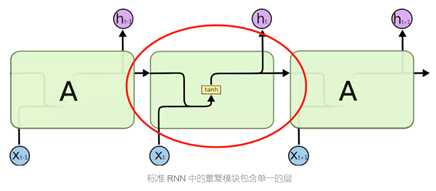
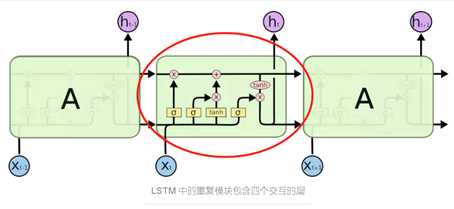
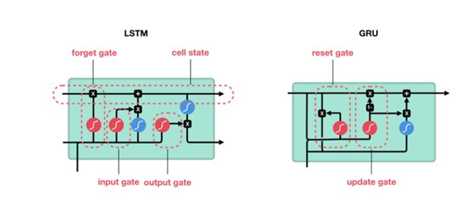
关于LSTM网络和GRU网络的详细信息
基于上面5种,建立模型,实现应用。
Seq2seq:Sequence to sequence
应用可以采用的结构有Encoder–Decoder 结构。用来处理输入的叫encoder,生成输出的叫decoder。而seq2seq就是一种输入和输出序列不等长的encoder-decoder结构,seq2seq任务的首选模型就是LSTM。这种结构可用于翻译或聊天对话场景,对输入的文本转换成另外一些列文本。如下图所示:
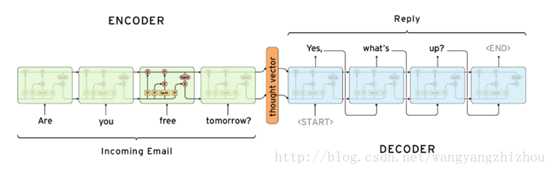
当然,seq2seq也不是完美的,距离decoder的第一个cell越近的输入单词,对decoder的影响越大。但这并不符合常理,这时就提出了attention机制,对于输出的每一个cell,都检测输入的sequence里每个单词的重要性。
Attention是基于seq2seq的改进模型再进行改进的机制。
NMT:Neural Machine Translation 神经翻译模型
用一个大型神经网络建模整个翻译过程的系统。抽象的架构就是一个encoder一个decoder。
上面介绍的几个概念,笔者尝试性画一个自底而上的图如下所示:

这些概念(或方法或模型或机制)一个个的提出,都是为了解决(优化)相应的问题,但这并不是说新的方法提出了,前者就被淘汰了,而是不同的事物的应用情景不同。不知道读者朋友们能不能体会我的感觉(我的说法也不尽全面)。
第二部分,介绍seq2seq
基本原理

基本模型
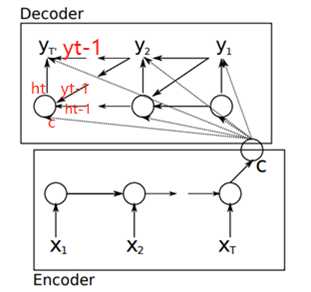
模型包括encoder和decoder两个部分。
将输入传到encoder部分,得到最后一个时间步长t的隐藏状态C。
Decoder的隐藏状态ht就由ht-1,yt-1和C三部分构成。
最后的输出yt从图中可知,由ht(前一时刻的隐藏层),yt-1(前一个预测结果),c(encoder最后一个隐藏层)得到。
基本模型还有一个复杂版,见下图所示
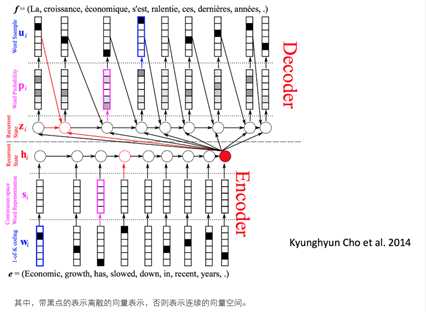
改进模型
可以很容易的看出,改进模型与第一个模型主要的区别在于输入到输出有一条完整的流,且decoder不是每个cell都需要encoder输出隐藏状态C。
Seq2seq模型的问题
只能用固定维度的最后一刻的encoder隐藏层来表示源语言Y,必须将此状态一直传递下去。可以想象,当需要预测的句子相当长时,效果就会相当差。
于是乎引入Attention机制,改善这个问题。
第三部分,介绍attention
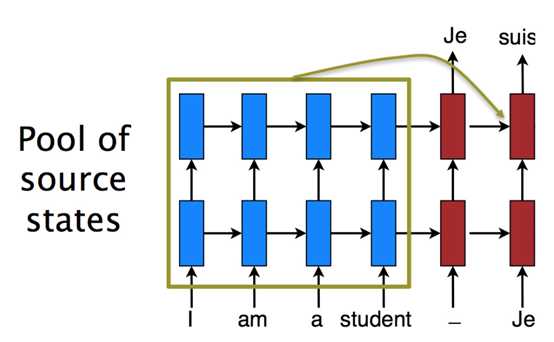
Attention机制,相当于改变从encoder传入到decoder的隐藏状态C。原先的状态C仅仅由最后一个时间步长t的隐藏状态C来决定。加入attention机制的seq2seq模型的状态c由所有输入向量xi共同决定。
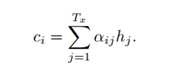
即,对于decoder的时间步长i的隐藏状态si,ci等于Tx个输入向量[1,Tx]的隐藏状态与其权重αij相乘得到。权重的意义在于说明:对于当前输出的词,每一个输入的词给予的注意力是不一样的。
笔者仅仅将理解的部分内容转述出来,而且忽略了排版,存在漏洞在所难免,敬请指正,另附参考的博客内容,便于综合理解。
参考内容:
https://www.jianshu.com/p/9dc9f41f0b29
https://baijiahao.baidu.com/s?id=1613717006522786574&wfr=spider&for=pc
https://www.jianshu.com/p/2f48a252ad80
https://blog.csdn.net/Irving_zhang/article/details/78889364
http://www.hankcs.com/nlp/cs224n-9-nmt-models-with-attention.html
以上是关于对seq2seq的粗浅认识的主要内容,如果未能解决你的问题,请参考以下文章