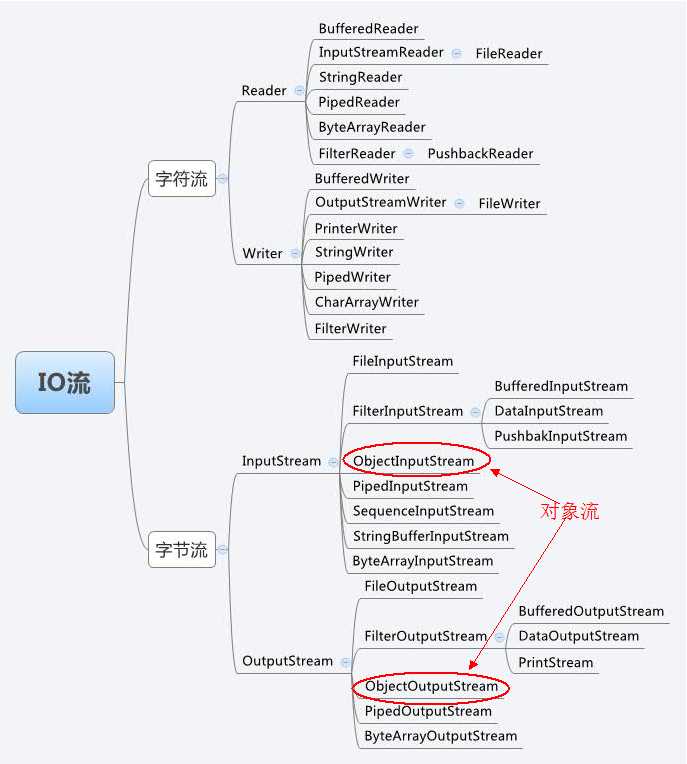
1、序列化
File 类的介绍:http://www.cnblogs.com/ysocean/p/6851878.html
Java IO 流的分类介绍:http://www.cnblogs.com/ysocean/p/6854098.html
Java IO 字节输入输出流:http://www.cnblogs.com/ysocean/p/6854541.html
Java IO 字符输入输出流:https://i.cnblogs.com/EditPosts.aspx?postid=6859242
Java IO 包装流:http://www.cnblogs.com/ysocean/p/6864080.html
1、什么是序列化与反序列化?
序列化:指把堆内存中的 Java 对象数据,通过某种方式把对象存储到磁盘文件中或者传递给其他网络节点(在网络上传输)。这个过程称为序列化。通俗来说就是将数据结构或对象转换成二进制串的过程
反序列化:把磁盘文件中的对象数据或者把网络节点上的对象数据,恢复成Java对象模型的过程。也就是将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程
2、为什么要做序列化?
①、在分布式系统中,此时需要把对象在网络上传输,就得把对象数据转换为二进制形式,需要共享的数据的 JavaBean 对象,都得做序列化。
②、服务器钝化:如果服务器发现某些对象好久没活动了,那么服务器就会把这些内存中的对象持久化在本地磁盘文件中(Java对象转换为二进制文件);如果服务器发现某些对象需要活动时,先去内存中寻找,找不到再去磁盘文件中反序列化我们的对象数据,恢复成 Java 对象。这样能节省服务器内存。
3、Java 怎么进行序列化?
①、需要做序列化的对象的类,必须实现序列化接口:Java.lang.Serializable 接口(这是一个标志接口,没有任何抽象方法),Java 中大多数类都实现了该接口,比如:String,Integer
②、底层会判断,如果当前对象是 Serializable 的实例,才允许做序列化,Java对象 instanceof Serializable 来判断。
③、在 Java 中使用对象流来完成序列化和反序列化
ObjectOutputStream:通过 writeObject()方法做序列化操作
ObjectInputStream:通过 readObject() 方法做反序列化操作
第一步:创建一个 JavaBean 对象
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
public class Person implements Serializable{ private String name; private int age; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Person [name=" + name + ", age=" + age + "]"; } public Person(String name, int age) { super(); this.name = name; this.age = age; }} |
第二步:使用 ObjectOutputStream 对象实现序列化
|
1
2
3
4
5
6
|
//在根目录下新建一个 io 的文件夹 OutputStream op = new FileOutputStream("io"+File.separator+"a.txt"); ObjectOutputStream ops = new ObjectOutputStream(op); ops.writeObject(new Person("vae",1)); ops.close(); |
我们打开 a.txt 文件,发现里面的内容乱码,注意这不需要我们来看懂,这是二进制文件,计算机能读懂就行了。
错误一:如果新建的 Person 对象没有实现 Serializable 接口,那么上面的操作会报错:

第三步:使用ObjectInputStream 对象实现反序列化
反序列化的对象必须要提供该对象的字节码文件.class
|
1
2
3
4
5
6
7
|
InputStream in = new FileInputStream("io"+File.separator+"a.txt"); ObjectInputStream os = new ObjectInputStream(in); byte[] buffer = new byte[10]; int len = -1; Person p = (Person) os.readObject(); System.out.println(p); //Person [name=vae, age=1] os.close(); |
问题1:如果某些数据不需要做序列化,比如密码,比如上面的年龄?
解决办法:在字段面前加上 transient
|
1
2
|
private String name;//需要序列化 transient private int age;//不需要序列化 |
那么我们在反序列化的时候,打印出来的就是Person [name=vae, age=0],整型数据默认值为 0
问题2:序列化版本问题,在完成序列化操作后,由于项目的升级或修改,可能我们会对序列化对象进行修改,比如增加某个字段,那么我们在进行反序列化就会报错:
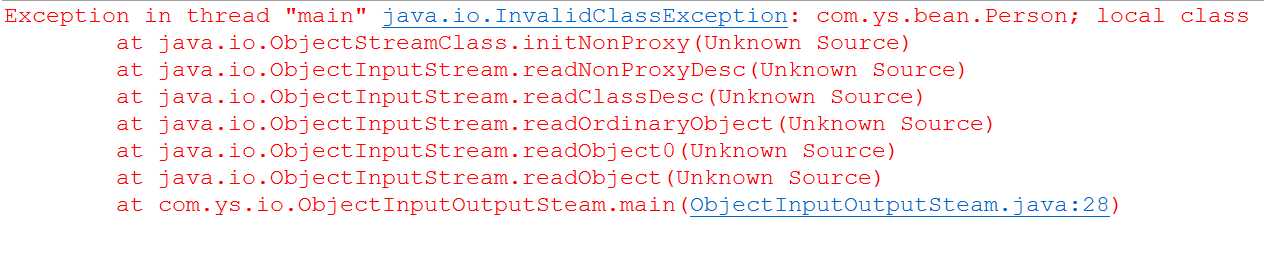
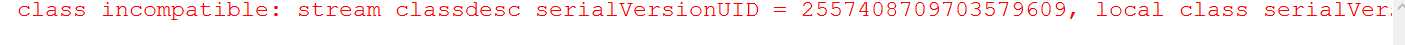
解决办法:在 JavaBean 对象中增加一个 serialVersionUID 字段,用来固定这个版本,无论我们怎么修改,版本都是一致的,就能进行反序列化了
|
1
|
private static final long serialVersionUID = 8656128222714547171L; |
====2、反射====
要想理解反射的原理,首先要了解什么是类型信息。Java让我们在运行时识别对象和类的信息,主要有2种方式:一种是传统的RTTI,它假定我们在编译时已经知道了所有的类型信息;另一种是反射机制,它允许我们在运行时发现和使用类的信息。
1、Class对象
理解RTTI在Java中的工作原理,首先需要知道类型信息在运行时是如何表示的,这是由Class对象来完成的,它包含了与类有关的信息。Class对象就是用来创建所有“常规”对象的,Java使用Class对象来执行RTTI,即使你正在执行的是类似类型转换这样的操作。
每个类都会产生一个对应的Class对象,也就是保存在.class文件。所有类都是在对其第一次使用时,动态加载到JVM的,当程序创建一个对类的静态成员的引用时,就会加载这个类。Class对象仅在需要的时候才会加载,static初始化是在类加载时进行的。

public class TestMain {
public static void main(String[] args) {
System.out.println(XYZ.name);
}
}
class XYZ {
public static String name = "luoxn28";
static {
System.out.println("xyz静态块");
}
public XYZ() {
System.out.println("xyz构造了");
}
}
输出结果为:

类加载器首先会检查这个类的Class对象是否已被加载过,如果尚未加载,默认的类加载器就会根据类名查找对应的.class文件。
想在运行时使用类型信息,必须获取对象(比如类Base对象)的Class对象的引用,使用功能Class.forName(“Base”)可以实现该目的,或者使用base.class。注意,有一点很有趣,使用功能”.class”来创建Class对象的引用时,不会自动初始化该Class对象,使用forName()会自动初始化该Class对象。为了使用类而做的准备工作一般有以下3个步骤:
- 加载:由类加载器完成,找到对应的字节码,创建一个Class对象
- 链接:验证类中的字节码,为静态域分配空间
- 初始化:如果该类有超类,则对其初始化,执行静态初始化器和静态初始化块
public class Base {
static int num = 1;
static {
System.out.println("Base " + num);
}
}
public class Main {
public static void main(String[] args) {
// 不会初始化静态块
Class clazz1 = Base.class;
System.out.println("------");
// 会初始化
Class clazz2 = Class.forName("zzz.Base");
}
}
2、类型转换前先做检查
编译器将检查类型向下转型是否合法,如果不合法将抛出异常。向下转换类型前,可以使用instanceof判断。
class Base { }
class Derived extends Base { }
public class Main {
public static void main(String[] args) {
Base base = new Derived();
if (base instanceof Derived) {
// 这里可以向下转换了
System.out.println("ok");
}
else {
System.out.println("not ok");
}
}
}
3、反射:运行时类信息
如果不知道某个对象的确切类型,RTTI可以告诉你,但是有一个前提:这个类型在编译时必须已知,这样才能使用RTTI来识别它。Class类与java.lang.reflect类库一起对反射进行了支持,该类库包含Field、Method和Constructor类,这些类的对象由JVM在启动时创建,用以表示未知类里对应的成员。这样的话就可以使用Contructor创建新的对象,用get()和set()方法获取和修改类中与Field对象关联的字段,用invoke()方法调用与Method对象关联的方法。另外,还可以调用getFields()、getMethods()和getConstructors()等许多便利的方法,以返回表示字段、方法、以及构造器对象的数组,这样,对象信息可以在运行时被完全确定下来,而在编译时不需要知道关于类的任何事情。
反射机制并没有什么神奇之处,当通过反射与一个未知类型的对象打交道时,JVM只是简单地检查这个对象,看它属于哪个特定的类。因此,那个类的.class对于JVM来说必须是可获取的,要么在本地机器上,要么从网络获取。所以对于RTTI和反射之间的真正区别只在于:
- RTTI,编译器在编译时打开和检查.class文件
- 反射,运行时打开和检查.class文件
public class Person implements Serializable {
private String name;
private int age;
// get/set方法
}
public static void main(String[] args) {
Person person = new Person("luoxn28", 23);
Class clazz = person.getClass();
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) {
String key = field.getName();
PropertyDescriptor descriptor = new PropertyDescriptor(key, clazz);
Method method = descriptor.getReadMethod();
Object value = method.invoke(person);
System.out.println(key + ":" + value);
}
}
以上通过getReadMethod()方法调用类的get函数,可以通过getWriteMethod()方法来调用类的set方法。通常来说,我们不需要使用反射工具,但是它们在创建动态代码会更有用,反射在Java中用来支持其他特性的,例如对象的序列化和JavaBean等。
4、动态代理
代理模式是为了提供额外或不同的操作,而插入的用来替代”实际”对象的对象,这些操作涉及到与”实际”对象的通信,因此代理通常充当中间人角色。Java的动态代理比代理的思想更前进了一步,它可以动态地创建并代理并动态地处理对所代理方法的调用。在动态代理上所做的所有调用都会被重定向到单一的调用处理器上,它的工作是揭示调用的类型并确定相应的策略。以下是一个动态代理示例:
接口和实现类:
public interface Interface {
void doSomething();
void somethingElse(String arg);
}
public class RealObject implements Interface {
public void doSomething() {
System.out.println("doSomething.");
}
public void somethingElse(String arg) {
System.out.println("somethingElse " + arg);
}
}
动态代理对象处理器:
public class DynamicProxyHandler implements InvocationHandler {
private Object proxyed;
public DynamicProxyHandler(Object proxyed) {
this.proxyed = proxyed;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws IllegalAccessException, IllegalArgumentException, InvocationTargetException {
System.out.println("代理工作了.");
return method.invoke(proxyed, args);
}
}
测试类:
public class Main {
public static void main(String[] args) {
RealObject real = new RealObject();
Interface proxy = (Interface) Proxy.newProxyInstance(
Interface.class.getClassLoader(), new Class[] {Interface.class},
new DynamicProxyHandler(real));
proxy.doSomething();
proxy.somethingElse("luoxn28");
}
}
输出结果如下:
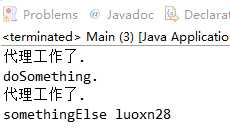
通过调用Proxy静态方法Proxy.newProxyInstance()可以创建动态代理,这个方法需要得到一个类加载器,一个你希望该代理实现的接口列表(不是类或抽象类),以及InvocationHandler的一个实现类。动态代理可以将所有调用重定向到调用处理器,因此通常会调用处理器的构造器传递一个”实际”对象的引用,从而将调用处理器在执行中介任务时,将请求转发。
3、多线程单例(创建一个多线程单例,说出大致代码)
单例模式是23种设计模式中比较常见的设计模式,又因为其代码量精简,所以经常会被用在在面试中测试面试者的能力。
初级的单例模式很简单
实现两个要求
1构造方法私有化
2对外提供静态的,公开的获取对象的方法
所以:初级单例模式如下
public class Singelton {
private Singelton(){}
private static Singelton sin=null;
public static Singelton getSingelton(){
if(sin==null){
sin=new Singelton();
}
return sin;
}
}
----------------------------------------
但是这样就够了吗?
随着学习的深入,我们知道程序大多数在多线程的环境下运行。这就对我们的代码提出了更高质量的要求,要求我们考虑线程安全问题。
仅仅是上面的那段代码无法保证线程的安全。于是:
public class SingletonThread {
private SingletonThread() {}
private static SingletonThread st=null;
public synchronized static SingletonThread getSingletonThread(){
if(st==null){
st=new SingletonThread();
}
return st;
}
}
这段代码考虑到了线程安全,但是,在方法上加锁代价是否太大了?效率与单线程相近,假设这个方法中有上万行代码,在方法上加锁
是很不划算的。
所以,我们有更好的方法
1
public final class SingletonOne {//饿汉式,不能实现按需分配
private SingletonOne(){};
private static SingletonOne sin=new SingletonOne();
public static SingletonOne getSingleton(){
return sin;
}
}
利用静态成员仅在类加载阶段执行一次的性质,得到唯一的对象。
此方法不仅线程安全,而且方法简介。
2我们能否不一开始就创建类的实例呢?做到按需分配
如下:
public final class SingletonTwo {
private SingletonTwo(){};
public static SingletonTwo setsin(){
return singleton.sin;
}
static class singleton{//内部类不会再外部类加载时加载,故此是按需分配。
private singleton() {};
private static final SingletonTwo sin=new SingletonTwo();
}
}
利用内部类不会在外部类加载时被加载的性质,真正实现了按需分配。
---------------------------------------------
以上两种方法是极好的,但是也需要根据实际情况使用,因为类中的方法和属性都是静态的,即使被继承之后也会被隐藏,
不能通过重写来实现多态,已经失去了被继承的意义,故此还有另一种推荐方法:
3
public class SingletonV {
private SingletonV(){}
private volatile SingletonV singleton=null;
public SingletonV getSingleton(){
if(singleton==null){
synchronized (SingletonV.class) {
if(singleton==null){
singleton=new SingletonV();
}
}
}
return singleton;
}
}
这样类还保留了继承的意义,同样要加锁,但是开销小得多。利用了关键字volatile。
具体用法如下
//java内存模型规定所有的变量都是存在主存当中(类似于前面说的物理内存),
//每个线程都有自己的工作内存(类似于前面的高速缓存)。
//线程对变量的所有操作都必须在工作内存中进行,
//而不能直接对主存进行操作。并且每个线程不能访问其他线程的工作内存。
//这就可能造成一个线程在主存中修改了一个变量的值,
//而另外一个线程还继续使用它在自己工作内存中的变量值的拷贝,造成数据的不一致。
//要解决这个问题,把该变量声明为volatile(不稳定的)即可,
//这就指示JVM,这个变量是不稳定的, 每次使用它都到 主存中 进行读取。
//一般说来,多任务环境下各任务间共享的标志都应该加volatile修饰。
//Volatile修饰的成员变量在每次被线程访问时, 都强迫 从共享内存中 重读 该成员变量的值。
//而且,当成员变量发生变化时,强迫 线程将变化值 回写到共享内存。这样在任何时刻,
//两个不同的线程总是看到某个成员变量的同一个值。
4、针对数据查询量过大进行优化操作
最近一段时间由于工作需要,开始关注针对mysql数据库的select查询语句的相关优化方法。
由于在参与的实际项目中发现当mysql表的数据量达到百万级时,普通SQL查询效率呈直线下降,而且如果where中的查询条件较多时,其查询速度简直无法容忍。曾经测试对一个包含400多万条记录(有索引)的表执行一条条件查询,其查询时间竟然高达40几秒,相信这么高的查询延时,任何用户都会抓狂。因此如何提高sql语句查询效率,显得十分重要。以下是网上流传比较广泛的30种SQL查询语句优化方法:
1、应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
2、对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
3、应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=04、尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20可以这样查询:
select id from t where num=10
union all
select id from t where num=205、下面的查询也将导致全表扫描:(不能前置百分号)
select id from t where name like ‘%abc%‘若要提高效率,可以考虑全文检索。
6、in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)对于连续的数值,能用 between 就不要用 in 了:
select id from t where num in(1,2,3)7、如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然 而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
select id from t where num=@num可以改为强制查询使用索引:
select id from t with(index(索引名)) where num=@num8、应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100应改为:
select id from t where num=100*29、应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3)=’abc’–name以abc开头的id
select id from t where datediff(day,createdate,’2005-11-30′)=0–’2005-11-30′生成的id应改为:
select id from t where name like ‘abc%’
select id from t where createdate>=’2005-11-30′ and createdate<’2005-12-1′10、不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
11、在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
12、不要写一些没有意义的查询,如需要生成一个空表结构:
select col1,col2 into #t from t where 1=0这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:
create table #t(…)13、很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)14、并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段 sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
15、索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有 必要。
16.应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
17、尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会 逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
18、尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
19、任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
20、尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。
21、避免频繁创建和删除临时表,以减少系统表资源的消耗。
22、临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使 用导出表。
23、在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
24、如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
25、尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
26、使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
27、与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时 间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。
28、在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。无需在执行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 消息。
29、尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
30、尽量避免大事务操作,提高系统并发能力。