一文读懂胜者树与败者树
Posted 恋喵大鲤鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文读懂胜者树与败者树相关的知识,希望对你有一定的参考价值。
文章目录
胜者树和败者树是在排序和归并排序算法中常用的两种数据结构,它们在大规模数据排序中具有高效性和良好的稳定性。本篇博客将详细介绍这两种数据结构。
1.为什么要使用外部排序?
外部排序是用于对超出计算机内存容量的大型数据集进行排序的一种算法。在排序过程中,需要将数据集分成多个较小的子集,并在内存中对每个子集进行排序,然后再将排序后的子集合并起来。这种算法通常会利用硬盘等外部存储设备来协助处理数据,因此被称为“外部排序”。
以下是一些使用外部排序算法的理由:
-
大规模数据集:当数据集太大,无法在计算机的内存中完全装入时,外部排序算法是一个很好的选择。例如,在处理大型数据库或超大规模文件时,通常需要使用外部排序算法。
-
节约内存:当内存受限时,外部排序算法也是很有用的。例如,在移动设备等资源受限的计算机上运行排序操作时,使用外部排序算法可以避免占用过多的内存。
-
并行处理:外部排序算法还可以通过将数据集分成多个块并对每个块进行并行处理来进一步提高性能。这意味着可以使用多个处理器或计算机来同时处理数据集,从而加快排序速度。
2.外部排序如何合并子集?
在外部排序算法中,合并子集是一个关键的步骤,这个过程通常是通过多路归并算法来实现的。
多路归并算法通常使用一个优先队列(也称为最小堆)来保存各个子集中的数据。在合并过程中,首先从各个子集中读取一个元素,并将它们插入到优先队列中。队列会自动将它们排序,因此队列顶端的元素是当前最小的元素。我们将队列顶端的元素取出,并将它插入到磁盘文件中。然后我们从该元素所在的子集中读取下一个元素,并将它插入到队列中,这样队列中的元素数保持不变。这个过程一直重复,直到所有元素都被读取出来,合并完成。
具体而言,合并子集的过程如下:
1.从每个子集中读取第一个元素,并将它们插入到一个优先队列中,以便从中选取最小元素。
2.从队列中取出最小的元素,并将它添加到一个磁盘文件中。
3.从包含该最小元素的子集中读取下一个元素,并将它插入到队列中。
4.重复步骤2和3,直到队列为空,所有元素都被读取出来。
这个算法保证了所有元素都会按照从小到大的顺序被写入到磁盘文件。虽然每个子集中的元素数量可能很大,但是每次只需要读取一个元素到内存中,并且优先队列的大小通常比每个子集要小得多,因此该算法能够处理非常大的数据集。
3.优先队列使用什么数据结构?
外部排序多路归并时,常用的数据结构有:
- 堆
- 胜者树
- 败者树
面对这三个数据结构,应该选择哪一个呢?
4.堆
堆(Heap)是一种高效的优先级队列。
堆满足下列性质:
- 堆是一棵完全二叉树。
- 堆中某个结点的值总是不大于或不小于其父结点的值。
当堆中某个结点的值总是不小于父结点的值,为小顶堆,根结点最小。
当堆中某个结点的值总是不大于父结点的值,为大顶堆,根结点最大。
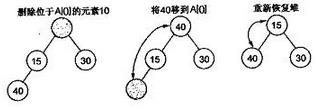
取出一个元素总是发生在堆顶,因为堆顶的元素是最小的(小顶堆中)。
然后使用堆中最后一个元素来填补空缺位置,然后对顶部元素进行下沉,如果左右孩子有比自己小的,则选择选择最小的那个进行交换。重复进行下沉操作,以满足堆的性质。
5.胜者树
胜者树(Winner Tree)是一种常用于排序和归并排序算法中的数据结构。
胜者树满足下列性质:
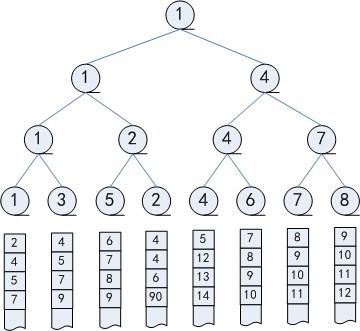
- 胜者树一棵完全二叉树。其中的叶结点是要排序的元素,非叶结点是两个子结点中胜者的代表。
- 根节点代表着所有元素中的胜者。
每个叶子节点相当于一个选手,每个中间节点相当于一场比赛,每一层相当于一轮比赛。
胜者树的一个优点是,如果一个选手的值改变了,可以很容易地修改这棵胜者树。只需要沿着从该结点到根结点的路径修改这棵二叉树,而不必改变其他比赛的结果。
下面是选择一个最小的数字为胜利者。
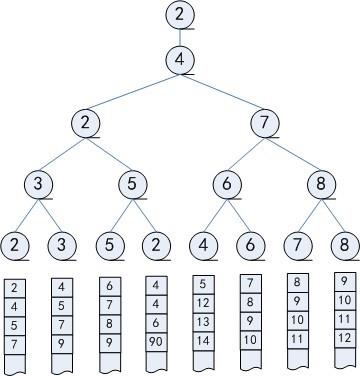
在下一次输出第二小的数字时候,只需要把 1 所在的数组里面的元素加进去,然后从叶子节点到根节点一直比较得出第二小的值,这样就减少了很多次无用的比较。

6.败者树
败者树(Loser Tree)是一种常用于排序和归并排序算法中的数据结构。
胜者树满足下列性质:
- 胜者树一棵完全二叉树。其中的叶结点是要排序的元素,非叶结点是两个子结点中败者的代表。
- 根节点代表着所有元素中的败者。
败者树是胜者树的一种变体,它也是一棵完全二叉树。和胜者树不同的是,败者树的节点存储的是败者。
在败者树中,用父结点记录其左右子结点进行比赛的败者,而让胜者参加下一轮的比赛。败者树的根结点记录的是败者,需要加一个结点来记录整个比赛的胜利者。
7.为什么要选择败者树
采用败者树可以简化重构的过程。
在用胜者树的时候,每个新元素上升时,首先需要获得父节点,然后再获得兄弟节点,然后再比较。
在使用败者树的时候,每个新元素上升时,只需要获得父节点并比较即可。
所以总的来说,减少了访存的时间。
其实现在程序的主要瓶颈在于访存了,计算倒几乎可以忽略不计了。
所以,外部排序多路归并时,优先队列应该使用败者树。
参考文献
OpenAI ChatGPT
数据结构- 堆的原理和常见算法问题 - 春水煎茶
数据结构:胜者树与败者树 - CSDN博客
堆,赢者树,败者树的区别与联系 - CSDN博客
以上是关于一文读懂胜者树与败者树的主要内容,如果未能解决你的问题,请参考以下文章