Flume入门
Posted agnes1994
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flume入门相关的知识,希望对你有一定的参考价值。
2018-12-31 15:29:44
Flume 百度百科:
-
flume(日志收集系统)
System Requirements?
- Java Runtime Environment - Java 1.8 or later
- Memory - Sufficient memory for configurations used by sources, channels or sinks
- Disk Space - Sufficient disk space for configurations used by channels or sinks
- Directory Permissions - Read/Write permissions for directories used by agent
Data flow model
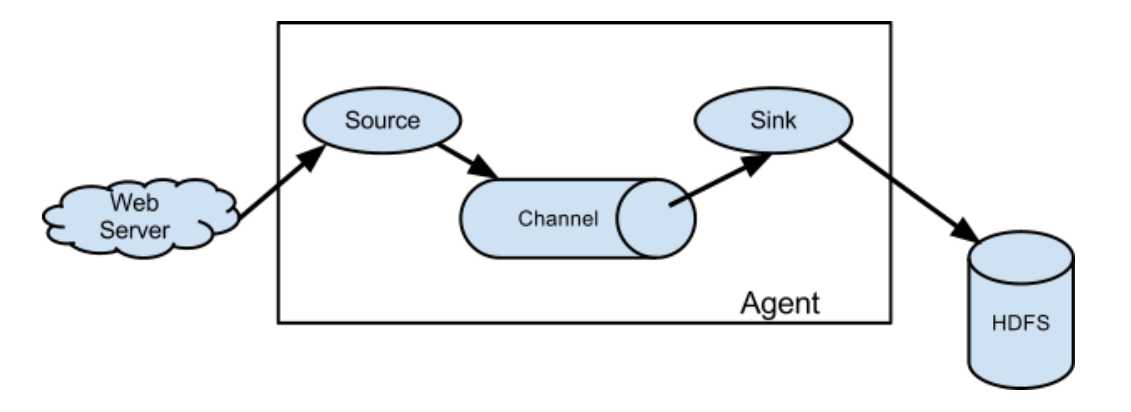
A Flume agent is a (JVM) process that hosts the components through which events flow from an external source to the next destination (hop).
A Flume source consumes events delivered to it by an external source like a web server. The external source sends events to Flume in a format that is recognized by the target Flume source.When a Flume source receives an event, it stores it into one or more channels.
The channel is a passive (被动的)store that keeps the event until it’s consumed by a Flume sink.
The sink removes the event from the channel and puts it into an external repository like HDFS (via Flume HDFS sink) or forwards it to the Flume source of the next Flume agent (next hop) in the flow.
The source and sink within the given agent run asynchronously(异步的)with the events staged in the channel.
Setup
Setting up an agent
Flume agent configuration is stored in a local configuration file. This is a text file that follows the Java properties file format. Configurations for one or more agents can be specified in the same configuration file. The configuration file includes properties of each source, sink and channel in an agent and how they are wired together to form data flows.
Configuring individual components
Each component (source, sink or channel) in the flow has a name, type, and set of properties that are specific to the type and instantiation. For example, an Avro source needs a hostname (or IP address) and a port number to receive data from. A memory channel can have max queue size (“capacity”), and an HDFS sink needs to know the file system URI, path to create files, frequency of file rotation (“hdfs.rollInterval”) etc. All such attributes of a component needs to be set in the properties file of the hosting Flume agent.
Wiring the pieces together
The agent needs to know what individual components to load and how they are connected in order to constitute(构成) the flow. This is done by listing the names of each of the sources, sinks and channels in the agent, and then specifying the connecting channel for each sink and source.
Starting an agent
An agent is started using a shell script called flume-ng which is located in the bin directory of the Flume distribution. You need to specify the agent name, the config directory, and the config file on the command line:
$ bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template
Now the agent will start running source and sinks configured in the given properties file.
A simple example
Here, we give an example configuration file, describing a single-node Flume deployment. This configuration lets a user generate events and subsequently logs them to the console.
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
This configuration defines a single agent named a1. a1 has a source that listens for data on port 44444, a channel that buffers event data in memory(缓冲内存中的事件), and a sink that logs event data to the console.
Given this configuration file, we can start Flume as follows:
$ bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console
From a separate terminal, we can then telnet (远程登录)port 44444 and send Flume an event:
$ telnet localhost 44444
Trying 127.0.0.1...
Connected to localhost.localdomain (127.0.0.1).
Escape character is ‘^]‘.
Hello world! <ENTER>
OK
The original Flume terminal will output the event in a log message.
12/06/19 15:32:19 INFO source.NetcatSource: Source starting
12/06/19 15:32:19 INFO source.NetcatSource: Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
12/06/19 15:32:34 INFO sink.LoggerSink: Event: { headers:{} body: 48 65 6C 6C 6F 20 77 6F 72 6C 64 21 0D Hello world!. }
Setting multi-agent flow

In order to flow the data across multiple agents or hops, the sink of the previous agent and source of the current hop need to be avro type with the sink pointing to the hostname (or IP address) and port of the source.
Consolidation(合并)
A very common scenario in log collection is a large number of log producing clients sending data to a few consumer agents that are attached to the storage subsystem. For example, logs collected from hundreds of web servers sent to a dozen of agents that write to HDFS cluster.
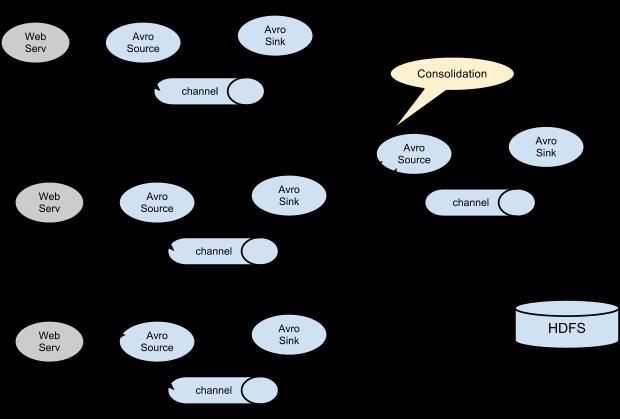
This can be achieved in Flume by configuring a number of first tier agents with an avro sink, all pointing to an avro source of single agent (Again you could use the thrift sources/sinks/clients in such a scenario). This source on the second tier agent consolidates the received events into a single channel which is consumed by a sink to its final destination.
Multiplexing the flow
Flume supports multiplexing the event flow to one or more destinations. This is achieved by defining a flow multiplexer that can replicate or selectively route an event to one or more channels.
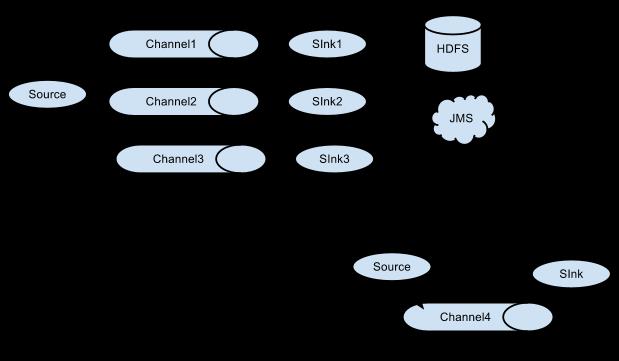
The above example shows a source from agent “foo” fanning out the flow to three different channels. This fan out can be replicating or multiplexing. In case of replicating flow, each event is sent to all three channels. For the multiplexing case, an event is delivered to a subset of available channels when an event’s attribute matches a preconfigured value. For example, if an event attribute called “txnType” is set to “customer”, then it should go to channel1 and channel3, if it’s “vendor” then it should go to channel2, otherwise channel3. The mapping can be set in the agent’s configuration file.
CSDN博客:转自:https://blog.csdn.net/qq_15300683/article/details/79879779
一、什么是Flume:
Flume是一个分布式的、可靠的、容错性(recovery mechanisms)、高可用性的一个服务,高效的收集、聚合、移动一个大数据量的日志文件(分布式的海量日志的高效收集、聚合、移动/传输的一个框架),特点:简单灵活,是基于一个流式数据处理框架。
二、Flume为什么会出现
通常情况下,我们抽取日志,通过shell脚本cp命令采集日志,时效性较差,无法压缩,shell脚本可能挂掉,不易监控。
三、Flume的架构
Agent:是一个Flume中最核心的组件,可以理解为就是一个flume
Agent=Source+Channel+Sink
Flume三个重要参数:
Source:数据从哪里取。去源头读数据,写到Channel中
Channel:中间管道(内存或磁盘中)。链接Source和Sink,类似一个队列或缓冲区
Sink:写到哪里去。从Channel拉数据,写到HDFS中,或把数据写入到下一个agent的source中
一个agent就是一个配置文件:可配置的、可插拔的、可组装的 0代码 (最重要的是bin目录,conf目录)
下载:http://cloudera-fastly-s3-2.s3-website-us-west-1.amazonaws.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.7.0.tar.gz
以上是关于Flume入门的主要内容,如果未能解决你的问题,请参考以下文章