Scala的集合
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scala的集合相关的知识,希望对你有一定的参考价值。
1.集合基础概念
? (1)集合的相关介绍
? ? Scala的集合有三大类:序列(seq)、集合(set)、映射(map)所有的集合都扩展自Iterable 特质,在Scala中集合有可变和不可变两种类型,可变集合可以在适当的地方被更新或者扩展,这意味着可以修改、添加、移除一个集合的元素,而不可变集合类则永远不会改变,但是仍然可以模拟添加、移除、或者更新操作,但是这些操作下都会返回一个新的集合。immutable 类型的集合 初始化后就不能改变了(注意与 val 修饰的变量进行区别),val 和 var:表明定义的变量(引用)是否能被修改而指向其他内容。
? ? 表明的是内存中开辟出来的这块空间里的内容能否被修改,如果针 对 immutable 变量进行修改,其实是开辟了一块新的内存空间,产生了一个新的变量,而 原来的变量依然没有改变
? (2)scala的集合类的结构
? ?所有关于集合的类都在:scala.collection包中。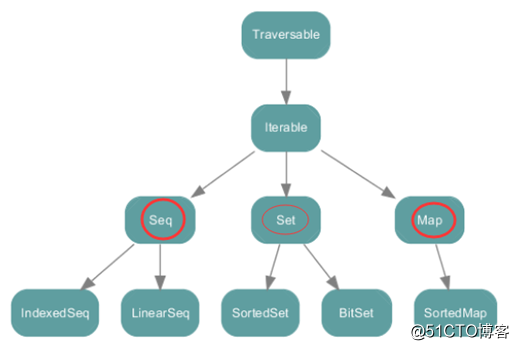
? ?不可变集合:scala.collection.immutable中。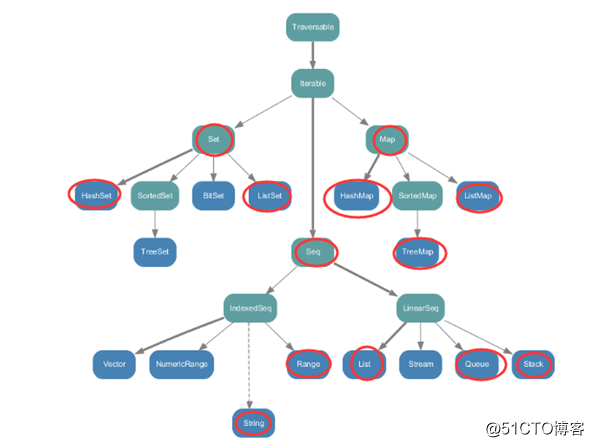
? ?可变集合:scala.collection.mutable中。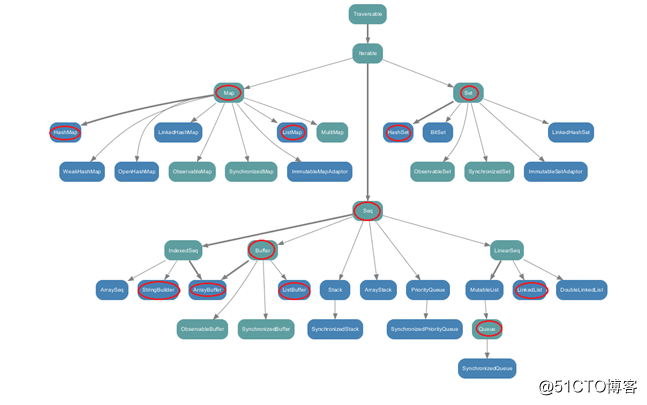
? ?而在默认的情况下Scala使用的是不可变的集合类。如果行使用可变对象必须:scala.collection.mutable.Set
2.集合的相关使用
(1)序列-list
不可变序列:
object Test01 {
def main(args: Array[String]): Unit = {
//1.创建一个list集合
val list01=List(1,2,3,4)
//2.判断集合是否为空
println(list01.isEmpty) //false
//3.获取集合中的头元素
println(list01.head) //1
//4.获取集合中除了head的其他元素
println(list01.tail) // 2 3 4
//5.获取list集合中的最后一个元素
println(list01.last) //4
//6.集合元素反转
println(list01.reverse) //4 3 2 1
//7.丢弃集合中的前n个元素
list01 drop 2
//8.获取集合中的前N个元素
var list02=list01.take(3)
//9.将集合进行分裂,返回一个tuple 第一个元素只有2个元素的list,第二个是集合中的剩下的所有元素
val tuple: (List[Int], List[Int]) = list01.splitAt(2)
//10.将两个集合压缩成一个
var list03=List(1,2,3,4)
val list04=List("1","2","3","4")
val lss=list03 zip list04
println(lss.toString()) //[(1,"1"),(2,"2"),(3,"3"),(4,"4")]
//11.集合,转换为字符串
println(list01.mkString(","))
//12.集合转化为数组
val arr=list01.toArray
}
}可变序列:
object Test01 {
def main(args: Array[String]): Unit = {
//1.创建一个list集合
val list01=ListBuffer(1,2,3,4)
//向可变序列中追加元素 (不会生成新序列)
list01+=1
list01.append(0)
//两个集合合并,会生出新的序列
val list02=ListBuffer(1,2,3,4)
val list03=ListBuffer(1,2,3,4)
val list04=list02++list03
}
}```
### (2) set集合不可变set
object Test01 {
def main(args: Array[String]): Unit = {
//创建一个不可变的set
var set01 =new mutable.HashSet[Int]()
val set02=set01+5 //生成一个新的set
val set03=set01++set02 //两个集合之间的合并
}
}
可变的set:
object Test01 {
def main(args: Array[String]): Unit = {
//1.创建一个可变的set
val set01=new mutable.HashSet[Int]()
//2.添加元素时,不会生成新的set
set01+=1
set01.add(1)
set01.add(2)
//3.删除一个元素
set01-=1
set01.remove(2)
//4.set的常用场景
val set02=Set(1,2,3,4)
val set03=Set(3,4,5,6)
//4.1 交集
val ints: Set[Int] = set02.intersect(set03)
//4.2 并集
val unin: Set[Int] = set02.union(set03)
//4.3差集
val diff: Set[Int]=set02.diff(set03)}
}
### (3) map 映射
? ? 在 Scala 中,有两种 Map,一个是 immutable 包下的 Map,该 Map 中的内容不可变; 另一个是 mutable 包下的 Map,该 Map 中的内容可变不可变map
object Test01 {
def main(args: Array[String]): Unit = {
//1.创建map
val base_info=Map("name"->"zs","age"->18,"address"->"beijign")
val extr0info=Map(("hobby","basketball"),("tall",180),("work","computer"))
//2.获取合修改map中的值
println(base_info.get("name")) //获取map中相应元素的值,根据key找value
println(base_info.getOrElse("age",18)) //表示根据key找value,如果没有使用默认值
base_info("age")=25 //注意这句代码是错误的,因为创建的不可变map,不能修改其中的值。
//3.遍历map
for(kv<-base_info){
println(kv._1,kv._2)
}
//使用map自带的foreach函数遍历
base_info.foreach(kv=> println(kv._1,kv._2))}
}
不可变map修改值异常:

可变map操作:
object Test01 {
def main(args: Array[String]): Unit = {
//1.创建map
val base_info=collection.mutable.
HashMap("name"->"zs","age"->18,"address"->"beijign")
//添加元素
base_info.put("hobby","basketball")
//添加map
val extra_info=collection.mutable.
HashMap("name"->"zs","age"->18,"address"->"beijign")
val new_map=base_info++extra_info
//获取元素的值
val name: Option[Any] = base_info.get("name")
//判断是否有这个元素
base_info.contains("name") //根据key判断是否有这个元素}
}
(4)Option, None, Some 类型介绍
?? None、Some 是 Option 的子类,它主要解决值为 null 的问题,在 java 语言中, 对于定义好的 HashMap,如果 get 方法中传入的键不存在,方法会返回 null,在编写代码的 时候对于 null 的这种情况通常需要特殊处理,然而在实际中经常会忘记,因此它很容易引起 NullPointerException 异常。在 Scala 语言中通过 Option、None、Some 这三个类来避免这样 的问题,这样做有几个好处,首先是代码可读性更强,当看到 Option 时,我们自然而然就 知道它的值是可选的,然后变量是 Option,比如 Option[String]的时候,直接使用 String 的话, 编译直接通不过。
例:object Test01 {
def main(args: Array[String]): Unit = {
//1.创建map
val base_info = collection.mutable.
HashMap("name" -> "zs", "age" -> 18, "address" -> "beijign")
//传递不存在的key
println(base_info("hobby"))
}
}
报出错误:

object Test01 {
def main(args: Array[String]): Unit = {
//1.创建map
val base_info = collection.mutable.
HashMap("name" -> "zs", "age" -> 18, "address" -> "beijign")
//传递不存在的key
println(base_info.get("hobby")) //返回none并不是报错
}
}
**总结**:Option有两个子类别,Some和None。当程序回传Some的时候,代表这个函式成功地给了你一个String,而你可以透过get()函数拿到那个String,如果程序返回的是None,则代表没有字符串可以给你。在Scala里Option[T]实际上是一个容器,就像数组或是List一样,你可以把他看成是一个可能有零到一个元素的List。当你的Option里面有东西的时候,这个List的长度是1(也就是 Some),而当你的Option里没有东西的时候,它的长度是0(也就是 None)。
### (5)元组-Tuple
元组的创建:object Test01 {
def main(args: Array[String]): Unit = {
//创建tuple
val tuple01=(1,2,3)
val (name,age,id)=("zs",18,1001) //这种方式是给tuple中的每一个元素起名字
//val (name,age,id)=("zs",18,1001)方式的实际应用
def getMaxandMin(arr:Array[Int]) ={
(arr.max,arr.min)
}
val (max,min)=getMaxandMin(Array(1,2,3,4)) //可以一次性获取最大值,最小值}
}
元组的转化:object Test01 {
def main(args: Array[String]): Unit = {
//创建一个全部是元组的数组
val arr=Array((1,"zs"),(2,"ls"),(3,"ww"))
val map = arr.toMap
map.foreach(e=>println(s"${e._1}:${e._2}"))
}
}
### (6)集合的综合使用:
编写wordcount程序:
方法一:object Test01 {
def main(args: Array[String]): Unit = {
//定义一个数组
val arr=Array("zzy,zs,ww,zl","zy,jj,ww,cl","zzy,jj,ww","jj,cl,ww")
//1.第一步,将数组中的每一个元素按,切分
//((zzy,zs,ww,zl),(zy,jj,ww,cl),(zzy,jj,ww),(jj,cl,ww))
val words: Array[Array[String]] = arr.map(line=>line.split("s+"))
//2.将数组元素为元组的,数组,压平成一个全是字符串的数组
//zzy zs ww zl zy jj ww cl zzy jj ww jj cl ww
val word: Array[String] = words.flatten
//3.对数组元素进行分类输出
//(zzy,1) (zs,1) (ww,1) (zl,1) ...
val tuples: Array[(String, Int)] = word.map(word=>(word,1))
//4.将元素进行分组
//map(ww,(1,1,1,1)),(zzy,(1,1))
val stringToTuples: Map[String, Array[(String, Int)]] = tuples.groupBy(x=>x._1)
//5.对每个分组的元素进行聚合
val wordcount: Map[String, Int] = stringToTuples.map(x=>(x._1,x._2.length))}
}```
方法二:
object Test01 {
def main(args: Array[String]): Unit = {
val arr=Array("zzy,zs,ww,zl","zy,jj,ww,cl","zzy,jj,ww","jj,cl,ww")
val words: Array[String] = arr.flatMap(line=>line.split("\s+"))
val word: Array[(String, Int)] = words.map(word=>(word,1))
val stringToTuples: Map[String, Array[(String, Int)]] = word.groupBy((x=>x._1))
stringToTuples.map(word=>(word._1,word._2.length))
}
}以上是关于Scala的集合的主要内容,如果未能解决你的问题,请参考以下文章