用CNN对文本处理,句子分类(简单理解卷积原理)
Posted libin123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用CNN对文本处理,句子分类(简单理解卷积原理)相关的知识,希望对你有一定的参考价值。
首先需要理解N-gram
https://zhuanlan.zhihu.com/p/32829048对于在NLP中N-gram的理解,一元,二元,三元gram
大多数 NLP 任务的输入不是图像像素,而是以矩阵表示的句子或文档。矩阵的每一行对应一个标记,通常是一个单词,但它也可以是一个字符。也就是说,每一行都是代表一个单词的向量。通常这些向量是像 word2vec 或 GloVe 这样的词嵌入(低维表示),但是它们也可以是将单词索引到词汇表中的一个 one-hot 向量。对于使用 100 维嵌入的 10 个字的句子,我们将有一个 10×100 的矩阵作为我们的输入。这就是是我们的“图像”。
在计算机视觉上,我们的过滤器在图像的局部区域上滑动,但是在 NLP 中,我们通常使用滑过整行矩阵(单词)的过滤器。因此,我们的滤波器的“宽度”通常与输入矩阵的宽度相同。对于矩阵的宽度其实就是一个单词转化为的词向量的长度,然后这个滤波器相当于一次遍历多个词向量,而且可以有不同的滤波器。高度或区域大小可能会有所不同,通常使用一次滑动 2-5 个字的窗口。综合以上所述,一个用于 NLP 的卷积神经网络可能看起来像这样
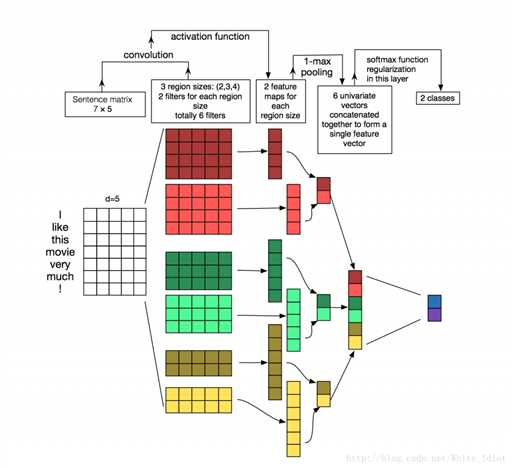
用于句子分类的卷积神经网络(CNN)体系结构图。 这里我们描述了三个过滤器的大小:2,3和4,每个大小都有2个过滤器。 每个过滤器对句子矩阵执行卷积并生成(可变长度)特征映射。 然后在每个特征图上执行1-max池化,即记录来自每个特征图的最大数。 因此,从六个特征图生成一元特征向量,并且这六个特征被连接以形成倒数第二层的特征向量。 最后的softmax层接收这个特征向量作为输入,并用它来分类句子;这里我们假设二进制分类,因此描述了两种可能的输出状态。
CNN的一个重要论点是,它们很快。非常快。卷积是计算机图形的核心部分,并在 GPUs 上的硬件级别上实现。与 n-grams 相比,CNNs 在表达方面也是有效的。有了大量的词汇,计算超过 3-grams 的任何东西都可能很快变得昂贵。即使是 Google 也不提供超过 5-grams 的任何东西。卷积过滤器自动学习好的表征,而不需要表示整个词汇表。我认为,第一层中的许多学习过滤器捕获与 n-gram 非常相似(但不限于)的特征,但是以更紧凑的方式表示它们。
以上是关于用CNN对文本处理,句子分类(简单理解卷积原理)的主要内容,如果未能解决你的问题,请参考以下文章