分布式系统中"身份证"是如何生成的?
Posted davidwang456
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式系统中"身份证"是如何生成的?相关的知识,希望对你有一定的参考价值。
1.公民身份证是如何生产的?
根据中华人民共和国国家标准GB 11643-1999 公民身份号码规则
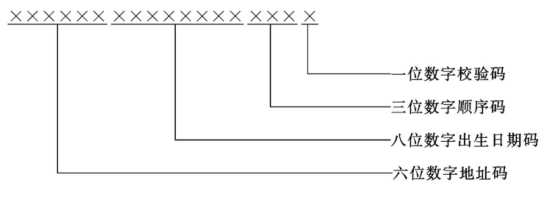
示例:

校验码公式
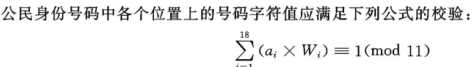
校验码规则说明

2.分布式系统中"身份证"
分布式系统,有的业务系统,都有生成ID的需求,如订单id,商品id,文章ID等。这个"身份证"一般要求:
>>全局唯一
>>有序
分布式系统中"身份证"生成常用方法:
1.数据库生成法
沈剑老师在<细聊分布式ID生成方法>中提到两个方法:1.单个法(auto_increment) 2.批量法(也称步长法) 其中详述了它们的优缺点,我就不一一赘述了。
2.redis生成法
分布式唯一ID极简教程 中提到,不赘述
3.zk生成法
与redis类似,不赘述。
4.mongo生成法
分布式唯一ID极简教程 中提到,不赘述
5.类snowflakes生成法
沈剑老师在<细聊分布式ID生成方法>中也提到,不赘述
6.uuid法
沈剑老师在<细聊分布式ID生成方法>中也提到,不赘述
7.msic法
其中,1~6种方法,网上都可以轻易找到,这里就不赘述了。
重点是方式 7,通过业务结合,灵活利用1~6来做,下面是我根据公民身份证唯一的思路来设计订单号一种方式,仅供参考
说明:
1.时间戳为毫秒级
2.用户号9位可以满足大部分系统需求,可以根据系统修正
3.顺序码 3位 是该用户同时下单的顺序码,先从redis查找,该用户在1分钟之内是否有订单,没有则设置为1,返回1,否则增加1
4.校验码,验证订单号是否符合规则,不符合规则的抛弃。
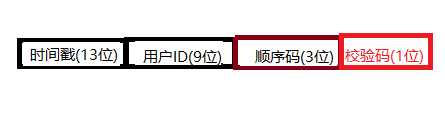
5. 建议使用数据库+redis缓存方式来做,多库的时候订单号也可以加上库信息
小结:
总体而言,分布式唯一ID需要满足以下条件:
-
高可用性:不能有单点故障。
-
全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
-
趋势递增:在mysql InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
-
时间有序:以时间为序,或者ID里包含时间。这样一是可以少一个索引,二是冷热数据容易分离。
-
分片支持:可以控制ShardingId。比如某一个用户的文章要放在同一个分片内,这样查询效率高,修改也容易。
-
单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
-
长度适中:不要太长,最好64bit。使用long比较好操作,如果是96bit,那就要各种移位相当的不方便,还有可能有些组件不能支持这么大的ID。
-
信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞争对手可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
参考资料:
【1】https://mp.weixin.qq.com/s/0H-GEXlFnM1z-THI8ZGV2Q
【2】https://mp.weixin.qq.com/s?__biz=MzI4NDY5Mjc1Mg==&mid=2247484269&idx=1&sn=795446b290f75c3129c50f8fa2e0b2c8&chksm=ebf6db12dc815204e81f6fddc4e690c3315c0e3ce71753b73720e74d47b9d08c633a617ccd95&scene=27#wechat_redirect
以上是关于分布式系统中"身份证"是如何生成的?的主要内容,如果未能解决你的问题,请参考以下文章