海量日志下的日志架构优化:filebeat+logstash+kafka+ELK
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了海量日志下的日志架构优化:filebeat+logstash+kafka+ELK相关的知识,希望对你有一定的参考价值。
前言:
实验需求说明
在前面的日志收集中,都是使用的filebeat+ELK的日志架构。但是如果业务每天会产生海量的日志,就有可能引发logstash和elasticsearch的性能瓶颈问题。因此改善这一问题的方法就是filebeat+logstash+kafka+ELK,
也就是将存储从elasticsearch转移给消息中间件,减少海量数据引起的宕机,降低elasticsearch的压力,这里的elasticsearch主要进行数据的分析处理,然后交给kibana进行界面展示
实验架构图:
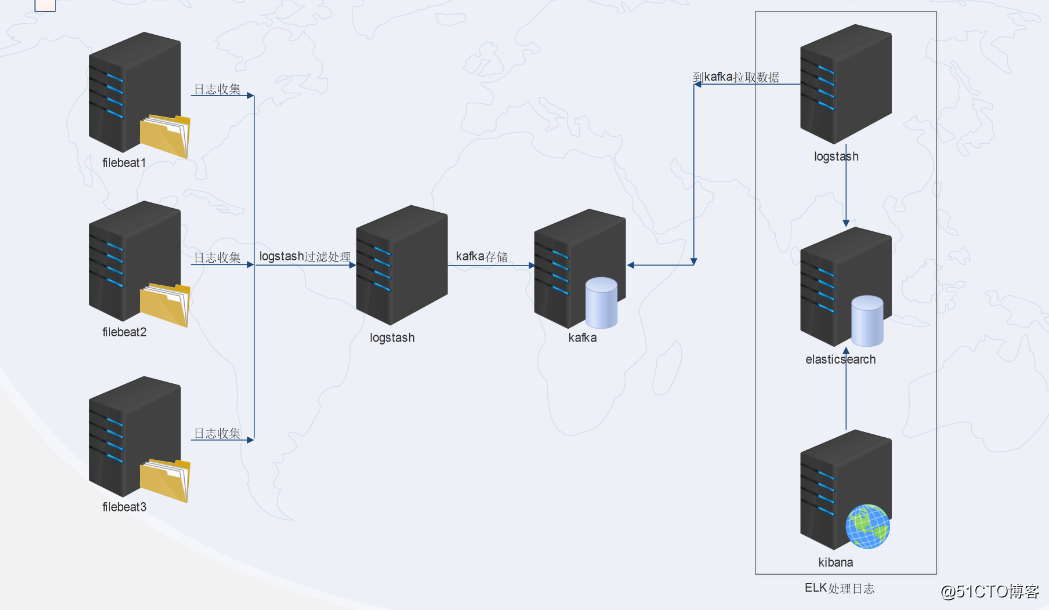
实验部属拓扑图:
整个过程是由filebeat收集本机日志——logstash(或集群)进行过滤处理——传送给kafka(或集群)进行存储——ELK工具之logstash再到kafka中获取数据——传给elk工具之elasticsearch分析处理——交给kibana展示。
这里部属的两个logstash扮演的角色和功能是不一样的。
因为实验机器是虚拟机,内存小,因此使用了四台机器,部属分布如下(试验机的内存最好在4G以上):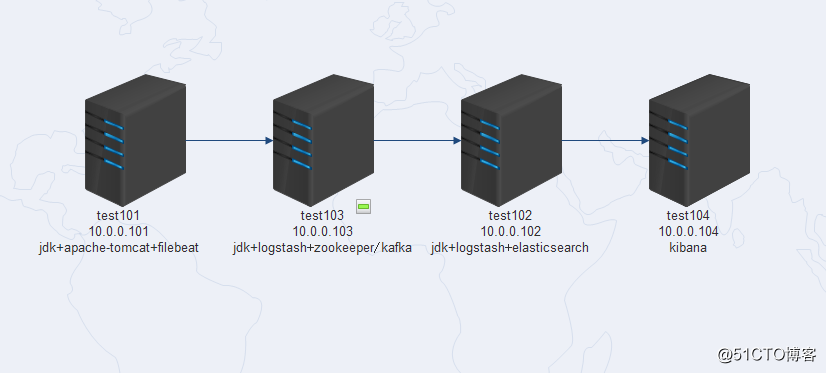
实验步骤
1、test101服务器部属tomcat并生成json格式日志
1.1 在test101服务器安装jdk+apachetomcat
jdk安装步骤省略,tomcat下载好安装包,解压即可。
1.2 修改tomcat配置,使之产生json格式日志
修改tomcat的配置文件/usr/local/apache-tomcat-9.0.14/conf/server.xml,注释掉原来的内容(大概在160行):
<!-- <Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log" suffix=".txt"
pattern="%h %l %u %t "%r" %s %b" />
-->然后添加新的内容:
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="tomcat_access_log" suffix=".log"
pattern="{"clientip":"%h","ClientUser":"%l","authenticated":"
%u","AccessTime":"%t","method":"%r","status":"%s","SendBytes":"
%b","Query?string":"%q","partner":"%{Referer}i","AgentVersion":"%{User-Agent}i"}" />1.3 重启tomcat,访问10.0.0.101:8080
查看日志已经变成了json格式:
[[email protected] logs]# tailf tomcat_access_log.2018-12-23.log
{"clientip":"10.0.0.1","ClientUser":"-","authenticated":" -","AccessTime":"[23/Dec/2018:16:01:35 -0500]","method":"GET / HTTP/1.1","status":"200","SendBytes":" 11286","Query?string":"","partner":"-","AgentVersion":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/71.0.3578.98 Safari/537.36"}1.4 创建elk的yum文件,安装filebeat
[[email protected] ~]# cat /etc/yum.repos.d/elk.repo
[elastic-6.x]
name=Elastic repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
[[email protected] ~]#
[[email protected] ~]# yum -y install filebeat修改配置文件/etc/filebeat/filebeat.yml如下(去掉已经注释的内容,还剩下这面一部分:)
这里要手动改配置,不能清空文件直接粘贴下面的配置!
这里要手动改配置,不能清空文件直接粘贴下面的配置!
这里要手动改配置,不能清空文件直接粘贴下面的配置!
#=========================== Filebeat inputs =============================
filebeat.inputs:
- type: log
enabled: true
paths:
- /usr/local/apache-tomcat-9.0.14/logs/tomcat_access_log* #日志路径
json.keys_under_root: true #这两行是为了保证能传送json格式的日志
json.overwrite_keys: true
#============================= Filebeat modules ===============================
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
#==================== Elasticsearch template setting ==========================
setup.template.settings:
index.number_of_shards: 3
#============================== Kibana =====================================
setup.kibana:
#----------------------------- Logstash output --------------------------------
output.logstash:
hosts: ["10.0.0.103:5044"]
#================================ Procesors =====================================
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~启动filebeat
[[email protected] ~]# systemctl start filebeat2、test103服务器部属logstash+kafka
2.1 部属jdk+zookeeper+kafka
1)jdk部属省略
2)zookeeper安装:
[[email protected] ~]# tar xf zookeeper-3.4.13.tar.gz -C /usr/local/
[[email protected] conf]# cd /usr/local/zookeeper-3.4.13/conf/
[[email protected] conf]# mv zoo_sample.cfg zoo.cfg
[[email protected] conf]# cd ../bin/
[[email protected] bin]# ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.4.13/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[[email protected] bin]# netstat -tlunp|grep 2181
tcp6 0 0 :::2181 :::* LISTEN 18106/java
[[email protected] bin]# 3)kafka安装:
[[email protected] ~]# tar xf kafka_2.12-2.1.0.tgz
[[email protected] ~]# mv kafka_2.12-2.1.0 /usr/local/kafka
[[email protected] ~]# cd /usr/local/kafka/config/修改server.properties,修改了两个地方:
listeners=PLAINTEXT://10.0.0.103:9092
zookeeper.connect=10.0.0.103:2181启动kafka
[[email protected] config]# nohup /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties >/dev/null 2>&1 &
[[email protected] config]# netstat -tlunp|grep 9092
tcp6 0 0 10.0.0.103:9092 :::* LISTEN 17123/java 2.2、部属logstash
1)同test101一样,创建elk的yum文件:
[[email protected] ~]# cat /etc/yum.repos.d/elk.repo
[elastic-6.x]
name=Elastic repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
[[email protected] ~]# 2)部属服务,修改配置
[[email protected] ~]# yum -y install logstash修改/etc/logstash/logstash.yml文件下面几项内容:
path.data: /var/lib/logstash
path.config: /etc/logstash/conf.d
http.host: "10.0.0.103" #本机IP
path.logs: /var/log/logstash创建收集日志文件
[[email protected] ~]# cd /etc/logstash/conf.d/创建配置文件logstash-kafka.conf,这个文件是在拿到filebeat推送过来的数据后,再推送给kafka:
[[email protected] conf.d]# cat logstash-kafka.conf
input {
beats {
port => 5044
}
}
output {
kafka {
bootstrap_servers => "10.0.0.103:9092" #kafka 的IP地址
topic_id => "crystal"
compression_type => "snappy"
codec => json
}
}
[[email protected] conf.d]# 3)测试启动logstash
[[email protected] ~]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/logstash-kafka.conf -t
WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults
Could not find log4j2 configuration at path /usr/share/logstash/config/log4j2.properties. Using default config which logs errors to the console
[WARN ] 2018-12-23 14:02:59.870 [LogStash::Runner] multilocal - Ignoring the ‘pipelines.yml‘ file because modules or command line options are specified
Configuration OK
[INFO ] 2018-12-23 14:03:06.277 [LogStash::Runner] runner - Using config.test_and_exit mode. Config Validation Result: OK. Exiting Logstash
[[email protected] ~]# 测试OK,启动logstash:
[[email protected] ~]# nohup /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/logstash-kafka.conf >/dev/null 2>&1 &
[2] 18200
[[email protected] ~]# netstat -tlunp|grep 18200 #检查端口启动状况,OK
tcp6 0 0 :::5044 :::* LISTEN 18200/java
tcp6 0 0 127.0.0.1:9600 :::* LISTEN 18200/java
[[email protected] ~]#
3、搭建ELK工具
3.1 test102服务器搭建jdk+logstash+elasticsearch
jdk部属省略
3.2 test102服务器安装logstash
1)yum安装logstash,修改/etc/logstash/logstash.yml文件下面几项内容:
path.data: /var/lib/logstash
path.config: /etc/logstash/conf.d
http.host: "10.0.0.102"
path.logs: /var/log/logstash2) 创建收集日志配置文件,这个文件是在kafka里面去拿数据,然后交给elasticsearch分析处理:
[[email protected] logstash]# cat /etc/logstash/conf.d/logstash-es.conf
input {
kafka {
bootstrap_servers => "10.0.0.103:9092"
topics => "crystal"
codec => "json"
consumer_threads => 5
decorate_events => true
}
}
output {
elasticsearch {
hosts => [ "10.0.0.102:9200" ]
index => "tomcat-log-%{+YYYY-MM-DD}"
codec => "json"
}
}
[[email protected] logstash]# 启动服务:
[[email protected] ~]# nohup /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/logstash-es.conf >/dev/null 2>&1 &3.3 test102服务器安装elasticsearch
yum安装elasticsearch,修改配置文件/etc/elasticsearch/elasticsearch.yml下面几行内容:
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 10.0.0.102
http.port: 9200启动服务:
[[email protected] config]# systemctl start elasticsearch
[[email protected] config]# netstat -tlunp|grep 9200
tcp6 0 0 10.0.0.102:9200 :::* LISTEN 7109/java
[[email protected] config]# 3.4 在test104服务器安装kibana
yum安装kibana,修改配置文件/etc/kibana/kibana.yml下面几行:
server.port: 5601
server.host: "10.0.0.104"
elasticsearch.url: "http://10.0.0.102:9200"
kibana.index: ".kibana"启动服务
[[email protected] kibana]# systemctl start kibana
[[email protected] kibana]# netstat -tlunp|grep 5601
tcp 0 0 10.0.0.104:5601 0.0.0.0:* LISTEN 11600/node
[[email protected] kibana]# 4、日志收集测试
4.1 访问tomcat:10.0.0.101:8080产生日志
访问10.0.0.101:8080后,查看kibana的索引创建界面,已经有索引tomcat-log-2018-12-357。创建索引,选择“I don‘t want to use the Time Filter”,然后查看界面数据,已经有日志了,并且是json格式: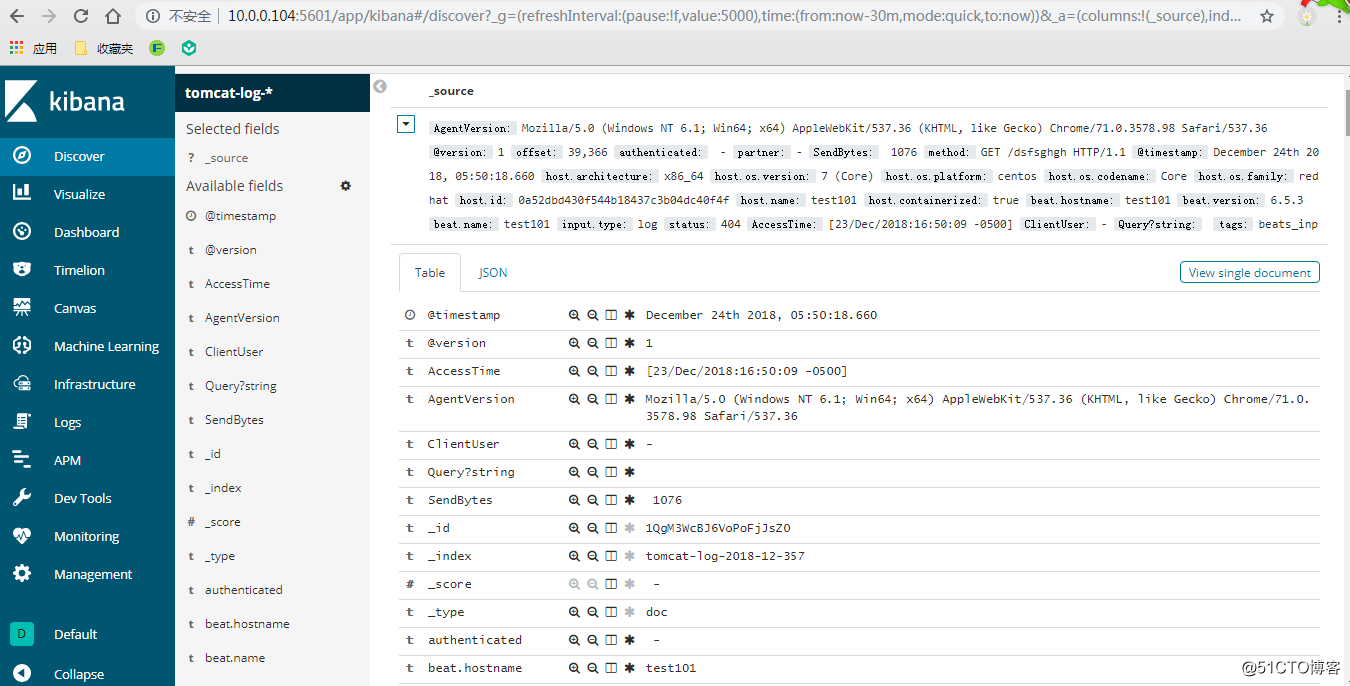
说明整个流程已经OK了。
同《ELK收集Apache的json格式访问日志并按状态码绘制图表》,创建一个饼图添加到Dashboard
: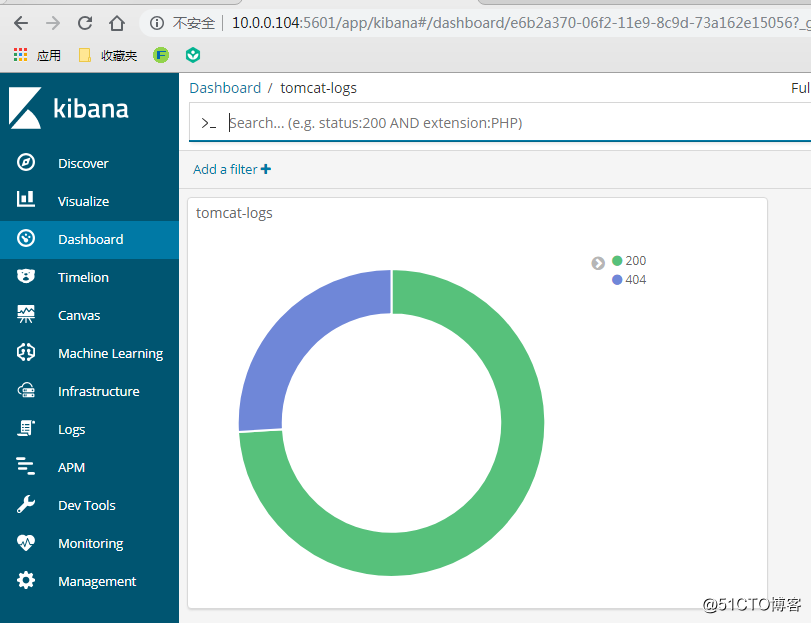
刷新10.0.0.101:8080/dsfsdsd(界面不存在,会产生404的状态码),饼图会动态变化如下: 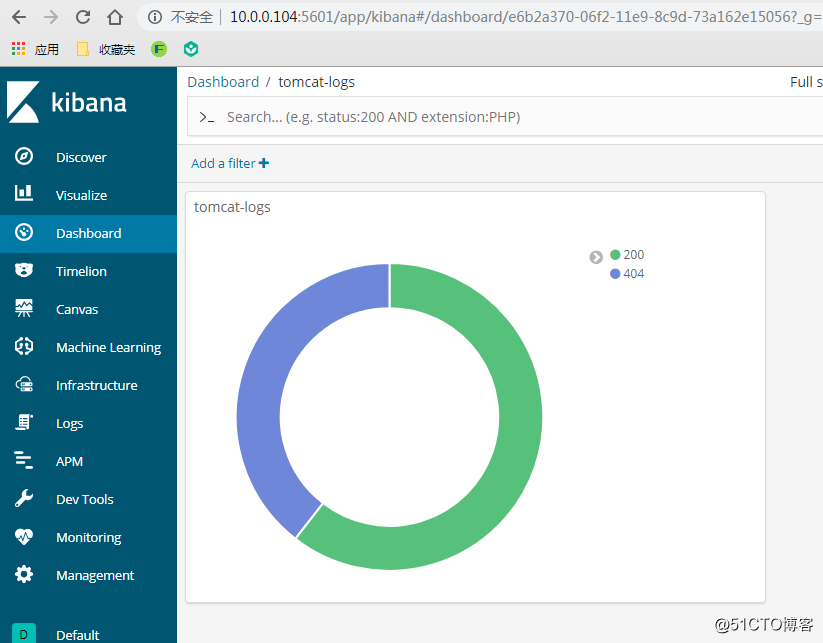
至此,filebeat+logstash+kafka+elk架构部属完成了。
以上是关于海量日志下的日志架构优化:filebeat+logstash+kafka+ELK的主要内容,如果未能解决你的问题,请参考以下文章