字典特征抽取
Posted shixinzei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字典特征抽取相关的知识,希望对你有一定的参考价值。
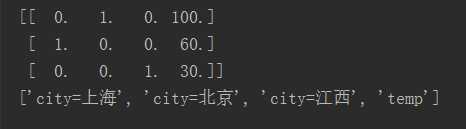
#特征抽取 feature_extraction #导包 # from sklearn.feature_extraction.text import CountVectorizer # # vector = CountVectorizer() # # res = vector.fit_transform(["life is short,i like python ", "life is too long ,i dislike python"]) # # print(vector.get_feature_names()) # # print(res.toarray()) #导包 字典特征抽取 from sklearn.feature_extraction import DictVectorizer #字典数据抽取:把字典中一些类别数据,分别进行转换成特征 def dictvec(): #实例化 dict = DictVectorizer(sparse=False) #sparse=False 取消稀疏矩阵 data = dict.fit_transform([{‘city‘: ‘北京‘, ‘temp‘: 100}, {‘city‘: ‘上海‘, ‘temp‘: 60}, {‘city‘: ‘江西‘, ‘temp‘: 30}]) print(data)#sparse格式 节约内存 便于读取处理 # [[0. 1. 0. 100.] # [1. 0. 0. 60.] # [0. 0. 1. 30.]] print(dict.get_feature_names()) #读取特征值 # [‘city=上海‘, ‘city=北京‘, ‘city=江西‘, ‘temp‘] return None if __name__ == "__main__": dictvec()
运行结果:

以上是关于字典特征抽取的主要内容,如果未能解决你的问题,请参考以下文章