知物由学 | 内容安全小技巧:如何辨认人工智能生成的虚假头像
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知物由学 | 内容安全小技巧:如何辨认人工智能生成的虚假头像相关的知识,希望对你有一定的参考价值。
“知物由学”是网易云易盾打造的一个品牌栏目,词语出自汉·王充《论衡·实知》。人,能力有高下之分,学习才知道事物的道理,而后才有智慧,不去求问就不会知道。“知物由学”希望通过一篇篇技术干货、趋势解读、人物思考和沉淀给你带来收获的同时,也希望打开你的眼界,成就不一样的你。
导读:通过人工智能制造的人脸样本,不通过技术手段几乎很难辨认出到底是真人还是假人,本文就告诉大家如何通过一些技巧辨别真假人脸。
本文作者:Kyle McDonald 译者:陆小凤
2014年,机器学习研究员Ian Goodfellow提出了生成对抗网络(GANs)的概念。“生成性”是因为它们输出的是如图像的这样的东西,而不是关于输入的预测(如“是否是热狗”);“对抗网络”,因为他们就像一个收银员和一个造假者一样在一个“猫捉老鼠的游戏”中使用两个神经网络相互竞争:一个试图欺骗另一个,让它认为自己可以产生真实的样本,另一个则试图区分真假。
最初的GAN图像很容易被人类辨认。想想2014年的这些面孔。
但是,2017年10月发布的最新的由GNA生成的人脸样本更难辨认。
但是,2017年10月发布的最新的由GNA生成的人脸样本更难辨认。
在尝试识别一个GAN生成的图像时,需要辨认一些内容。一般会将重点放在人脸的辨认上,因为那是研究人员的共同测试的地方,而且许多面部中最明显的假象也会出现在其他类型的图像中。
以下总结了一些技巧,供大家参考:
直发看起来像刷上去的油漆
这种直的发型在是长发的常见发型,在这种发型中,其中一小块头发看起来还不错,但在长发的部分看起来就像是有人用调色板上的刀或大刷子弄上了一束丙烯酸树脂漆。
难辩认的文本

对面部进行训练的GAN很难捕捉到背景中稀少的结构复杂的事物。此外,GAN同时出现训练数据的原始版本和镜像版本,这就意味着它们在建模的编写方面会有困难,因为通常情况下只需要一个定向。
背景是不真实的
脸部的GAN图像可靠的一个原因是所有的训练数据都集中在中心。这就是说,当涉及到例如眼睛和耳朵的位置和呈现时,GAN建模的变化点较少。然而,背景可以包含任何内容。这对于GAN来说太过复杂而无法建模,所以它最终会复制一般的类似于背景的纹理,而不是“真实”的背景场景。
不对称

GAN很难处理图像中的远距离的相关性。虽然像耳环这样的配对配饰通常在数据集中匹配,但在生成的图像中并不匹配。或者眼睛往往应该指向同一个方向,同一种颜色,但生成的图像往往是对视的,异色的。不对称也会很常见的表现在比如耳朵高度或大小的不匹配。
奇怪的牙齿

GAN可以组装一个通用场景,但目前在半规则重复细节(如牙齿)方面存在困难。有时GNA会导致牙齿错位,或以奇怪的方式拉伸或收缩每颗牙齿。在以往,这个问题也出现在其他领域,比如砖块图像的纹理合成。
杂乱的头发
这是识别生成的GNA图像的最快方法之一。通常GAN图像会在肩膀周围随意地形成一束头发,并把浓密的头发散落在额头上。一般发型有很多变化,且有很多细节,这成为GAN最难捕捉的东西之一。其中不是头发的东西有时也会变成类似头发的纹理。
没有常规的性别表现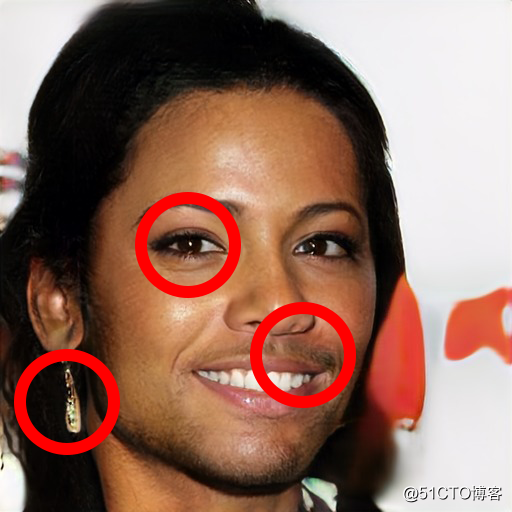
GAN在一个包含了20万张明星脸的图片的子集CelebA里进行训练。在这个数据集中并没有一个人有胡子、耳环且画了妆的样本,但GAN却总是会将性别中的典型的区别特征混为一谈。
更简单的说,这是因为GAN不能总是学习人类社会上强化的相同类别或二进制,例如“男性vs女性”的样本。这里有一点需要明确:它与不对称不同,没有常规的性别表现并不意味着图像不“真实”。与杂乱的头发不同,它在单个图像中呈现的假象更少,在大量图像集合中匹配统计数据的视差更大。
半正规的噪声

一些单色区域可能会出现水平或垂直条带的半规则噪声。在上述情况下,这可能是网络试图模仿布料的纹理。以前的GAN具有更显著的噪声模式,通常被描述为棋盘格假象。
彩虹色的出现

一些颜色较浅的区域像图上了多彩的石膏,包括衣领、脖子和眼白(图片中没显示出来)。
真实的图像样本

看看这些样本有清晰的背景文字,配对的耳环,相同大小的牙齿,还有精细的发型。记住所有这些细节,然后试着测试你区分真假的能力,看看你会正确多少。值得一说的是,有些人在“开始”就有困难了。
在上述图像一年的“逐步预处理”后,相同的研究人员发表了“模式化的GAN生成器体系结构”。
这有一些加强版认识:
在低分辨率下,论文中几乎所有的图像与照片都难以区分真假,但还是会有少数的假象是可以发现的。
丢失的耳环
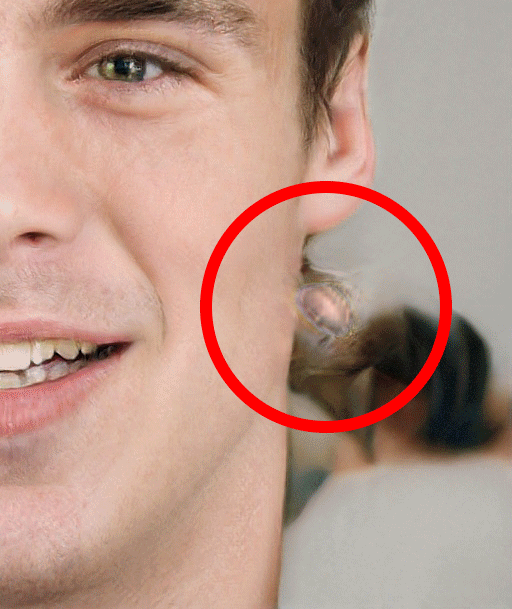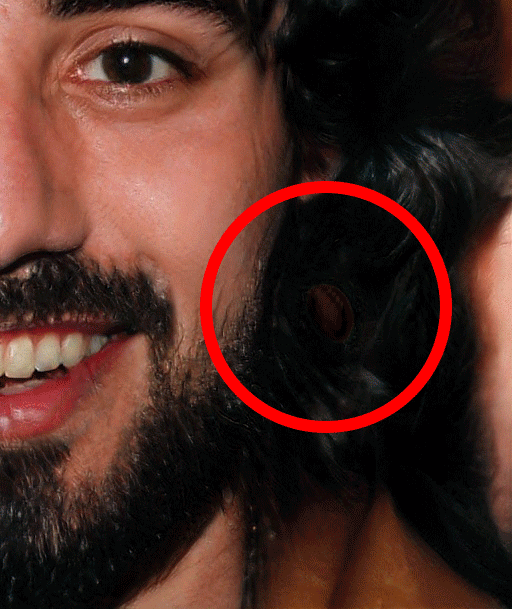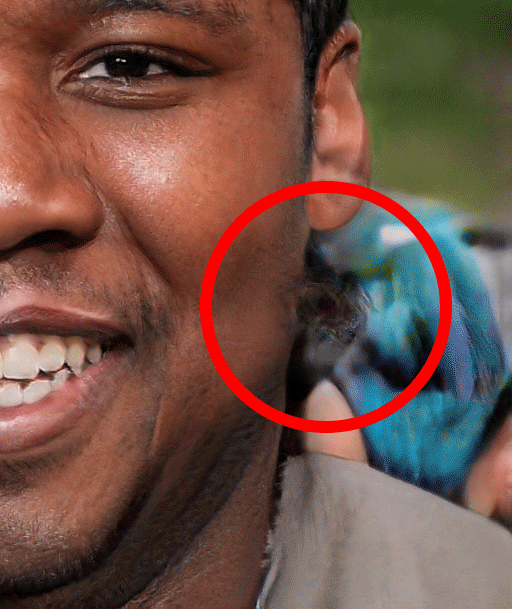
这个错误出现在几个图像在完全相同的位置。这可能是与神经网络试图生成耳环而失败有关,一个是因为它们都来自相同的“源”图像,还有就是在一种情况下,当与“中性”的女性面孔混淆时,耳环就会出现在这个位置。这也可能是无关的,因为另一个样本显示一个类似的错误出现在了多个图像之间的不同位置。
不对称

中间的图像是来自数据集的“平均脸”,基于来自世界各地Flickr用户的70k张照片。左边的图像中右耳有一个耳环,但左耳没有。这并不是要去判断单耳佩戴耳环是“对”还是“错”,而是判断这种不对称在数据集中是否是常见的。右边的图像中不匹配的耳朵大小是另一个不对称的样本。另一个过度不对称的样本可能是这张脸有斜视,即一个眼睛似乎看向不同的方向。

奇怪的牙齿

这些假象还有很多,在这个样本中,一颗牙齿在中间有一个空隙。在其他图像中,他们显示所有的牙齿滑向一边。
杂乱的头发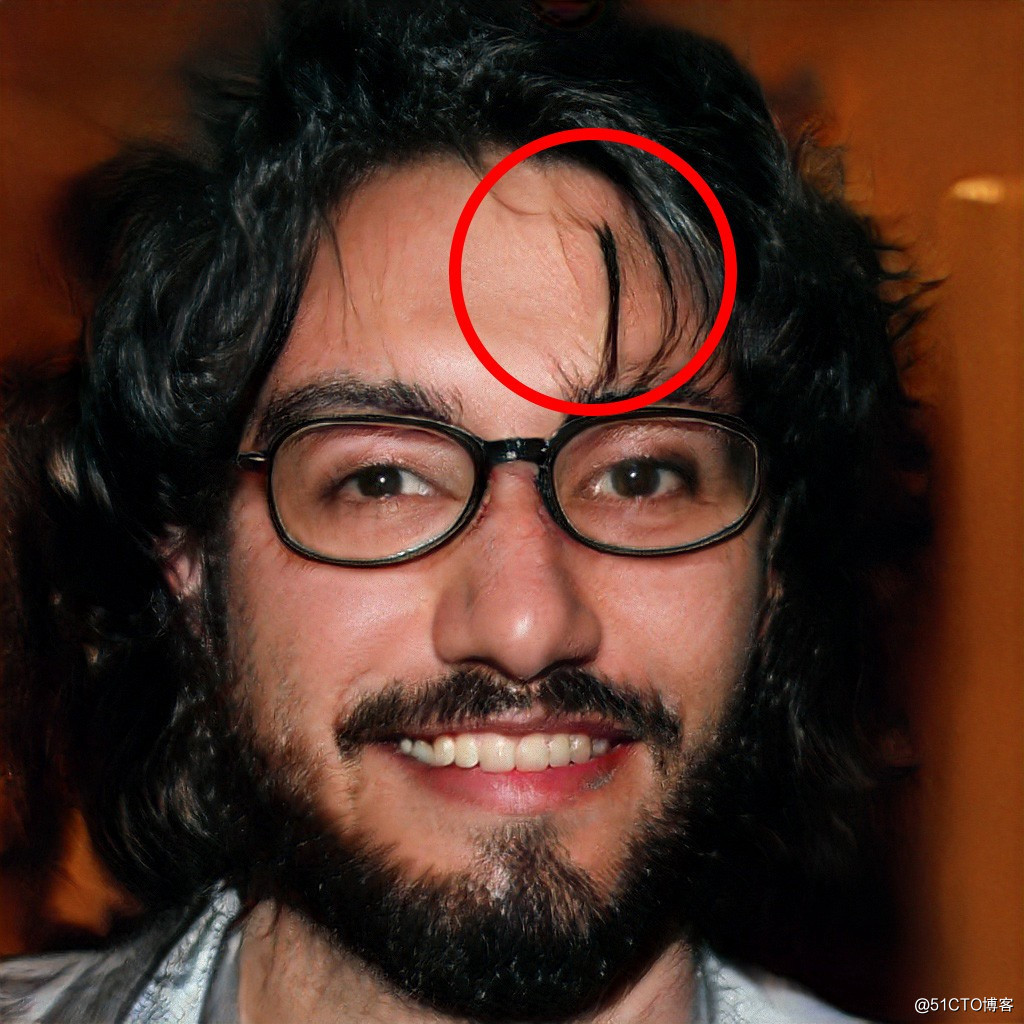
仍然存在,但通常会更好地融入其中。
绘画般的绘制

这一幅图像具有不寻常的水彩美感。目前还不清楚为什么会出现这种情况。在之前的工作中,会使用超分辨率网络对训练图像进行预处理。如果这里用的是同一个系统。在另一幅“粗制滥造”的图像中,这个区域看起来像是一件色彩鲜艳的衬衫的变体。
以上是关于知物由学 | 内容安全小技巧:如何辨认人工智能生成的虚假头像的主要内容,如果未能解决你的问题,请参考以下文章