1DadaFrame和Series创建
Posted xiaoliziaaa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了1DadaFrame和Series创建相关的知识,希望对你有一定的参考价值。
通过GroupBy创建DF对象
sn_group=data.groupby(‘SN‘)
purchase_count=sn_group.count().Price
average_purchase_price=sn_group.mean().Price.round(2)
total_purchase_price=sn_group.sum().Price
spender_summary=pd.DataFrame({"Purchase Count":purchase_count,
"Average Purchase":average_purchase_price,
"Total Purchase Value":total_purchase_price})
spender_summary.sort_values(‘Total Purchase Value‘,ascending=False,inplace=True)
spender_summary.head(10)
注意:purchase_count和average_purchase_price、total_purchase_price都是Series对象,并且它们的index都是一样的
第二种处理Series组成一个DF
#Age Demographics
age_bins = [0, 9, 14, 19, 24, 29, 34, 39, 100]
group_labels = ["<10", "10-14", "15-19", "20-24", "25-29", "30-34", "35-39", "40+"]
#9个数字 8个区间
data[‘Age_group‘]=pd.cut(data.Age,age_bins,labels=group_labels) #后面增加一列Age_group 原始数据780行就增加780个年龄区间
age_groupy=data.groupby(‘Age_group‘)
age_df=age_groupy["SN"].nunique()
age_df.name=‘Total Count‘ #age_df和age_percent_df的name都是SN所以要改为不同的名字作为列名
age_df #Series类型
age_percent_df=round((age_df/age_df.sum())*100,2)
age_percent_df.name=‘%Percentage of Players‘
avg_purchase_price=age_groupy[‘Price‘].mean()#等价avg_purchase_price=age_groupy.mean().Price avg_purchase_price=age_groupy.mean()是一个DF对象
avg_purchase_price.name=‘avg_purchase_price‘
total_purchase_price=age_groupy[‘Price‘].sum()
total_purchase_price.name=‘total_purchase_price‘
summary_age_df=pd.concat([age_df,age_percent_df,avg_purchase_price,total_purchase_price],axis=1) #列拼接
summary_age_df.reset_index(inplace=True)
任意举出一个age_groupy.nunique()就是DF的例子 。age_groupy.mean();age_groupy.count()...都是一个DF
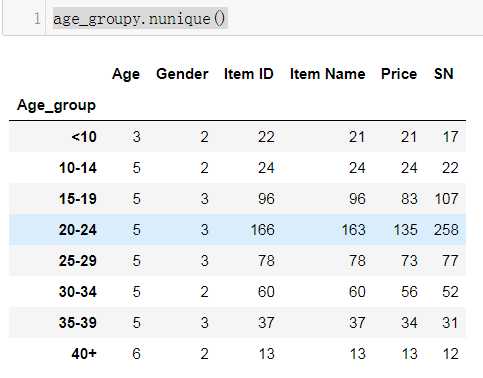
把不同的字段组成一个DF,各项之间没有关系,字段用[]阔起来,外面是一个字典{}
#Number of Unique Items
unique_items=data[‘Item ID‘].nunique()
#Average Purchase Price
avg_purchase=data.Price.mean()
#Total Number of Purchases
total_purchases=data.SN.count()
#Total Revenue
total_revenue=data.Price.sum()
summary_df = pd.DataFrame({"Number of Unique Items":[unique_items],
"Average Price":[avg_purchase],
"Number of Purchases":[total_purchases],
"Total Revenue":[total_revenue]})
summary_df

列表list[]转为DF 形如[(),(),(),]列表里面套元组形式
#Gender Demographics 性别特征
def gender_Percentage1(gender,):
gender_count=data.loc[data.Gender==gender,‘SN‘].nunique()
gender_perc = ((gender_count/total_count)*100)
return gender,gender_count,gender_perc
gender_laberls=np.sort(data.Gender.unique()).tolist()
total_count=data.SN.nunique()
result=[]
for gender in gender_laberls:
result.append(gender_Percentage1(gender))
gender_df1=pd.DataFrame(result,columns = ["Gender", "Total Count", "%Percentage of Players"])
gender_df1

最简单的通过字典创建DF
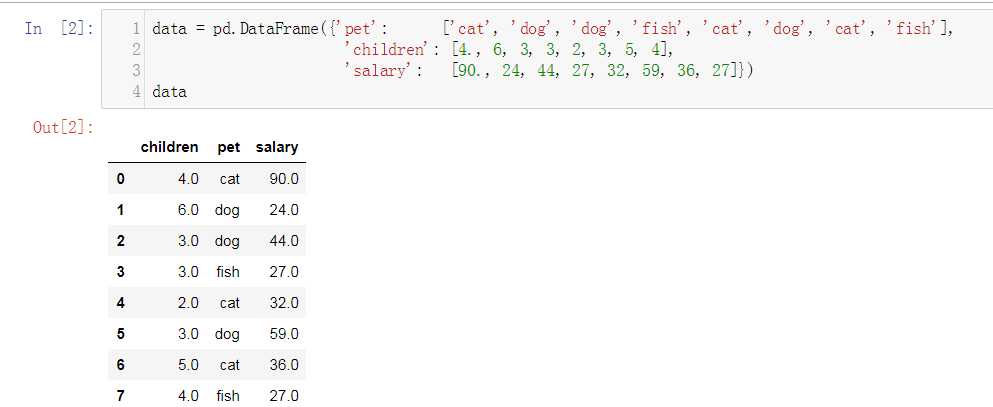
单个字典创建一个DF
Genre_temp=data.Genre.str.split(‘,‘).tolist() #[[],[],[]...]
genre_list=[i for j in Genre_temp for i in j] #里面有重复的但是没关系
import nltk
fdist=nltk.FreqDist(genre_list)
df=pd.DataFrame(fdist,index=[0]) #index=[0]一定要加一个索引是不是0无所谓
#df.T转置看起来更舒服一点
#genre=pd.Series(fdist).sort_values(ascending=False) #dist-->pd.Series 其实单个字典转为Series好一点

以上是关于1DadaFrame和Series创建的主要内容,如果未能解决你的问题,请参考以下文章