一、概述
1.什么是Hbase
根据官网:https://hbase.apache.org/
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
HBASE是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统
中文简明介绍:
Hbase是分布式、面向列的开源数据库(其实准确的说是面向列族)。HDFS为Hbase提供可靠的底层数据存储服务,MapReduce为Hbase提供高性能的计算能力,Zookeeper为Hbase提供稳定服务和Failover机制,因此我们说Hbase是一个通过大量廉价的机器解决海量数据的高速存储和读取的分布式数据库解决方案。
2.什么是列式存储
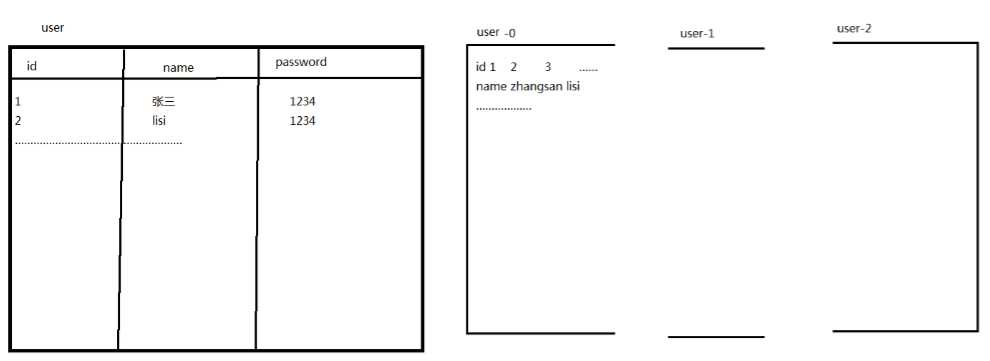
使用网友的图就是:
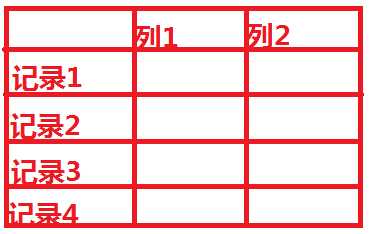
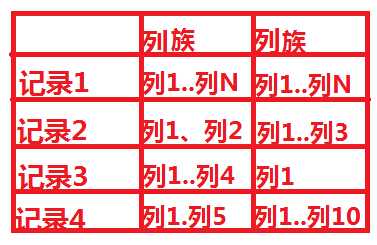
其中更加深入的内部原理讲解,参考:http://blog.csdn.net/lifuxiangcaohui/article/details/39891099
http://lib.csdn.net/article/datastructure/8951
3.为什么需要Hbase
以下介绍了一种Hbase出现的场景:
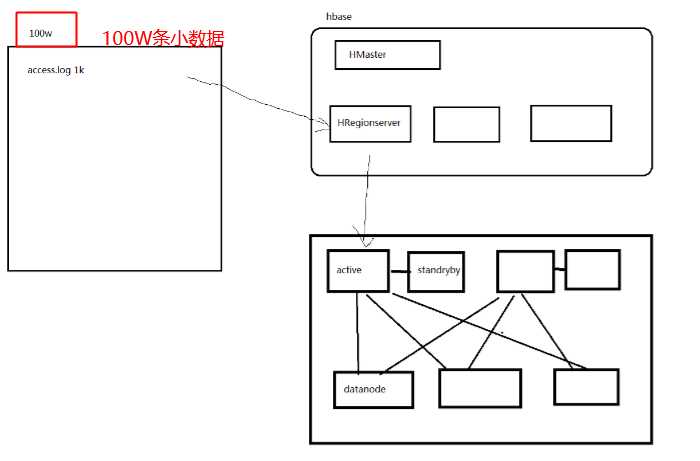
更多完整的原因介绍,参考:http://www.thebigdata.cn/HBase/30332.html
与传统数据库的对比如下:
1、传统数据库遇到的问题:
1)数据量很大的时候无法存储
2)没有很好的备份机制
3)数据达到一定数量开始缓慢,很大的话基本无法支撑
2、HBASE优势:
1)线性扩展,随着数据量增多可以通过节点扩展进行支撑
2)数据存储在hdfs上,备份机制健全
3)通过zookeeper协调查找数据,访问速度块。
4.hbase中的角色
1、一个或者多个主节点,Hmaster
2、多个从节点,HregionServer