[论文理解]Selective Search for Object Recognition
Posted aoru45
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[论文理解]Selective Search for Object Recognition相关的知识,希望对你有一定的参考价值。
Selective Search for Object Recognition
简介
Selective Search是现在目标检测里面非常常用的方法,rcnn、frcnn等就是通过selective search方法得到候选框,然后进行分类,也就是传统的two stage方法。本篇也是我看到frcnn之后不得不看的一篇论文,大致将自己的理解记录下来,方便以后指正。
Selective Search
算法目的
- 能够得到各种大小的框
由于图像中的物体可以有任意大小,所以selective search算法至少要能够做到得到各种大小的框。
- 考虑多种组合方法
由于图像中的颜色、纹理、光照条件等不同,我们无法只根据单一条件(如颜色)将区域合并,因此合并区域的过程中必须要综合考虑各种因素。
- 能够快速计算
selective search算法提出的目的就是要能够快速计算,这样我们能够把能多的计算量花在后面识别上,而不是得到物体的框上。
Hierarchical Grouping
大致理解
Selective Search算法采用的是分级合并的算法,具体就是从细节部分开始计算,最后到总体,也就是Bottom-up方法。由于这个过程是分级进行的,所以我们可以在不同级框定一定的区域,这样框定的区域就是各种scale的,满足了上面的要求。
细节理解
Hierarchical Grouping中很重要的一点是用了Felzenszwalb的算法得到了图像分割的区域,这是一个基于图的图像分割算法,这个算法下次博客更新会写理解,这里只需要知道经过该算法得到了若干个分隔后的图像区域,这些区域经过我们的selective search算法得到合并并且框出候选框。具体的做法是:首先,计算所有任意两region之间的相似性(这个怎么计算后面会提到,利用区域的特征计算),然后每次相似性最大的两个区域进行合并,框出合并后的集合,用合并之前两个区域集合的特征计算合并之后的区域的特征,这时候就可以再利用新的区域和其他区域计算相似度进一步迭代,迭代的终点是整个图像变成一个区域。由于相似度是基于区域特征来计算的,而合并后的特征可以基于合并之前的特征运算得到,不需要再根据图像的pixel重新计算,因此fast to compute。
下图就是该算法的细节,其中相似函数在后面讲道,所以当时我画了个问号。

计算s相似函数
首先是颜色空间的Scolor的计算,文章考虑了八种策略来计算色彩的相似性,下图列出了文章提的颜色空间:

在不同颜色空间下用直方图统计法计算相似度,每个channel分为25个bins,3channel图就是75bins。色彩相似性是使用L1范数来进行计算的。

Stexture是纹理特征的相似函数,使用的是SIFT特征来进行计算的,SIFT特征在之前的博客中有写道的。
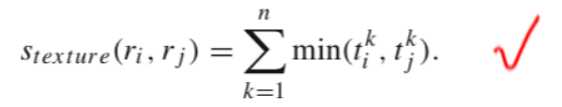
Ssize是区域大小的相似函数,
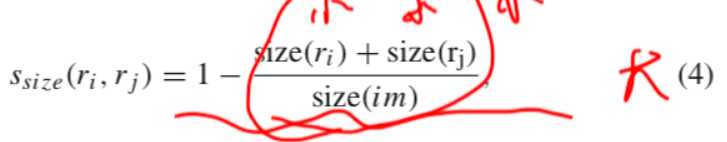
直接这样计算还是存在问题的,因为光size相似比较大,但是两者相距比较远的情况下两个region合并之后的区域是有问题的,所以为了解决这种问题,提出了Sfill函数
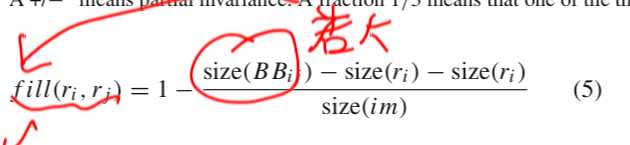
看上面的公式就知道可以解决这个问题了。
最终呢,s相似性函数就通过下面的公式计算得到:
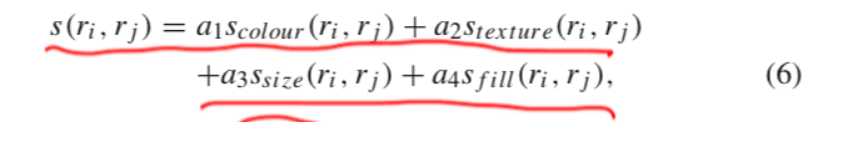
其中呢,ai取值为0或者1,表明是否启用该特征。
合并区域
合并区域需要考虑到的是防止从大区域开始合并,因为这样可能会导致很多小区域没有没框进来,所以应该优先从小区域开始合并,但是又要保留一定的随机性,所以作者定义了vi = RND*i,RND为随机数,范围为0-1,i表示层级数,i=1代表整个图像。这样就基本可以保证小区域优先合并并且有一定的随机性了。依次合并,直到合并为一个区域。
之后再将合并过程中的框的vi按照从大到小的顺序排序,保留阈值大小之前排序的框,这些框为算法的输出。
实现
github地址:https://github.com/AlpacaDB/selectivesearch
安装:
pip install selectivesearch使用:
import skimage.data
import selectivesearch
img = skimage.data.astronaut()
img_lbl, regions = selectivesearch.selective_search(img, scale=500, sigma=0.9, min_size=10)
regions[:10]
=>
[{'labels': [0.0], 'rect': (0, 0, 15, 24), 'size': 260},
{'labels': [1.0], 'rect': (13, 0, 1, 12), 'size': 23},
{'labels': [2.0], 'rect': (0, 15, 15, 11), 'size': 30},
{'labels': [3.0], 'rect': (15, 14, 0, 0), 'size': 1},
{'labels': [4.0], 'rect': (0, 0, 61, 153), 'size': 4927},
{'labels': [5.0], 'rect': (0, 12, 61, 142), 'size': 177},
{'labels': [6.0], 'rect': (7, 54, 6, 17), 'size': 8},
{'labels': [7.0], 'rect': (28, 50, 18, 32), 'size': 22},
{'labels': [8.0], 'rect': (2, 99, 7, 24), 'size': 24},
{'labels': [9.0], 'rect': (14, 118, 79, 117), 'size': 4008}]output:

论文原文:https://ivi.fnwi.uva.nl/isis/publications/2013/UijlingsIJCV2013
以上是关于[论文理解]Selective Search for Object Recognition的主要内容,如果未能解决你的问题,请参考以下文章
论文阅读笔记--Selective Search for Object Recognition
Selective Search for Object Recognition 论文笔记图片目标分割