Python3中的68个内置函数总结
Posted luowei2018
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python3中的68个内置函数总结相关的知识,希望对你有一定的参考价值。
一、内置函数
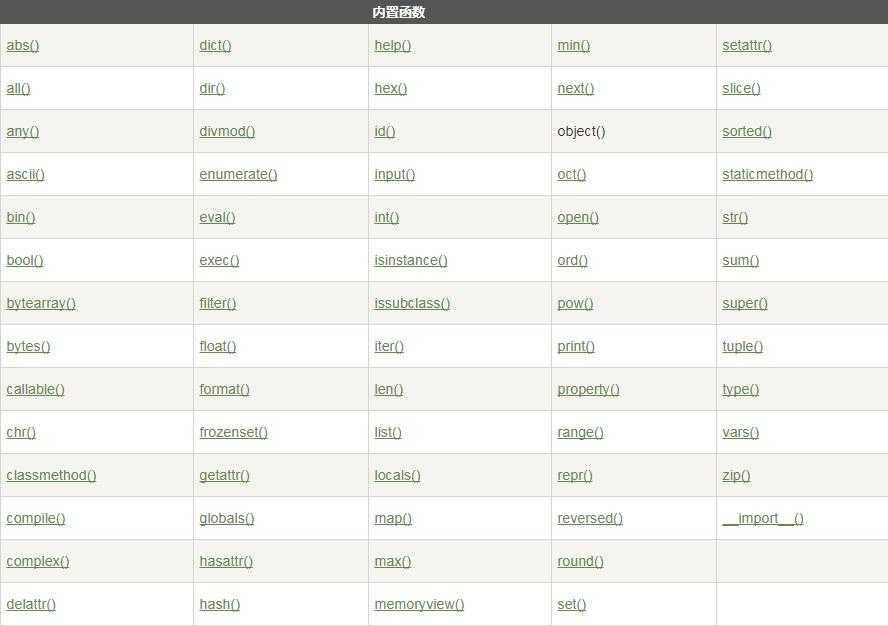
10大类
- 数学运算(7个)
- 类型转换(24个)
- 序列操作(8个)
- 对象操作(9个)
- 反射操作(8个)
- 变量操作(2个)
- 交互操作(2个)
- 文件操作(1个)
- 编译执行(4个)
- 装饰器(3个
1、数学运算(7个)
(1)abs()
- 返回数字的绝对值
(2)divmod()
- 返回两个数值的商和余数,是一个元组
(a//b, a%b)
>>>divmod(7, 2)
(3, 1)(3)max()
- 返回可迭代对象中的元素中的最大值或者所有参数的最大值
(4)min()
- 返回可迭代对象中的元素中的最小值或者所有参数的最小值
>>> min(-1,-2,key = abs) # 传入了求绝对值函数,则参数都会进行求绝对值后再取较小者
-1(5)pow()
- 返回两个数值的幂运算值或其与指定整数的模值,语法:
pow(x,y[,z]),如果z存在,则再对结果进行取模,其结果等效于pow(x,y) %z - 注意:pow() 通过内置的方法直接调用,内置方法会把参数作为整型,而math模块则会把参数转换为float
(6)round()
- 返回浮点数x的四舍五入值,语法:
round(x[,n]) - 除非对精确度没什么要求,否则尽量避开用round()函数,近似计算我们还有其他的选择:
①使用math模块中的一些函数,比如math.ceiling(天花板除法)。
②python自带整除,//和div函数。
③字符串格式化可以做截断使用,例如"%.2f"% value(保留两位小数并变成字符串……如果还想用浮点数请披上float()的外衣)。
④当然,对浮点数精度要求如果很高的话,请用decimal模块。(7)sum()
- 对元素类型是数值的可迭代对象中的每个元素求和,语法:
sum(iterable[, start])
>>>sum([0,1,2])
3
>>> sum((2, 3, 4), 1) # 元组计算总和后再加 1
10
>>> sum([0,1,2,3,4], 2) # 列表计算总和后再加 2
122、类型转换(24个)
(1)bool()
- 将给定参数转换为布尔类型,如果没有参数,返回False,bool 是int的子类。
>>>bool()
False
>>> bool(0)
False
>>> issubclass(bool, int) # bool 是 int 子类
True(2)int()
- 将一个字符串或数字转换为整型。语法:class int(x,base=10),x是字符串或数字,base为进制数,默认十进制。
(3)float()
- 根据传入的参数创建一个新的浮点数
>>> float() #不提供参数的时候,返回0.0
0.0
>>> float(3)
3.0
>>> float(‘3‘)
3.0(4)complex()
- 创建一个值为
real + imag*j的复数或者转化一个字符串或数为复数。如果第一个参数为字符串,则不需要指定第二个参数。
语法:class complex([real[, imag]])
参数:
real -- int, long, float或字符串
imag -- int, long, float
>>>complex(1, 2)
(1 + 2j)
>>> complex(1) # 数字
(1 + 0j)
>>> complex("1") # 当做字符串处理
(1 + 0j)
# 注意:这个地方在"+"号两边不能有空格,也就是不能写成"1 + 2j",应该是"1+2j",否则会报错
>>> complex("1+2j")
(1 + 2j)(5)str()
- 返回一个对象的字符串表现形式(给用户)
(6)bytearry()
- 根据传入的参数创建一个新的可变字节数组,并且每个元素的值范围:
0<=x<256。
class bytearray([source[, encoding[, errors]]])
# 如果 source 为整数,则返回一个长度为 source 的初始化数组;
# 如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
# 如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
# 如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。
# 如果没有输入任何参数,默认就是初始化数组为0个元素。
>>>bytearray()
bytearray(b‘‘)
>>> bytearray([1,2,3])
bytearray(b‘x01x02x03‘)
>>> bytearray(‘中文‘,‘utf-8‘)
bytearray(b‘xe4xb8xadxe6x96x87‘)(7)bytes()
- 返回一个新的bytes对象,该对象是一个0<=x<256区间内的整数不可变序列,它是bytearray的不可变版本。语法:
class bytes([source[,encoding[,errors]]])
>>> bytes(‘中文‘,‘utf-8‘)
b‘xe4xb8xadxe6x96x87‘(8)memoryview()
- 返回给定参数的内存查看对象(Momory view)。所谓内存查看对象,是指对支持缓冲区协议的数据进行包装,在不需要复制对象基础上允许Python代码访问,语法:memoryview(obj),返回元组列表。
>>> v = memoryview(b‘abcefg‘)
>>> v[1]
98
>>> v[-1]
103(9)ord()
- 是
chr()函数(对于8位的ASCII字符串)的配对函数,它以一个字符串(Unicode字符)作为参数,返回对应的ASCII数值,或者Unicode数值。
>>>ord(‘a‘)
97
>>> ord(‘€‘)
8364(10)chr()
- 返回整数所对应的Unicode字符。语法:
chr(i),可以是10进制也可以是16进制形式的数字,数字范围为0到1,114,111(16进制为0x10FFFF)。
(11)bin()
- 返回一个整数的2进制字符串表示。
>>>bin(10)
‘0b1010‘
>>> bin(20)
‘0b10100‘(12)oct()
- 将一个整数转换成8进制字符串。
(13)hex()
- 将一个指定数字转换为16进制数字符串,以
0x开头。
(14)tuple()
- 根据传入的参数创建一个新的元组
>>> tuple() #不传入参数,创建空元组
()
>>> tuple(‘121‘) #传入可迭代对象,使用其元素创建新的元组
(‘1‘, ‘2‘, ‘1‘)(15)list()
- 根据传入的参数创建一个新的列表
>>>list() # 不传入参数,创建空列表
[]
>>> list(‘abcd‘) # 传入可迭代对象,使用其元素创建新的列表
[‘a‘, ‘b‘, ‘c‘, ‘d‘](16)dict()
- 根据传入的参数创建一个新的字典
# 创建空字典
>>>dict()
{}
# 传入关键字
>>> dict(a=‘a‘, b=‘b‘, t=‘t‘)
{‘a‘: ‘a‘, ‘b‘: ‘b‘, ‘t‘: ‘t‘}
# 映射函数方式来构造字典
>>> dict(zip([‘one‘, ‘two‘, ‘three‘], [1, 2, 3]))
{‘three‘: 3, ‘two‘: 2, ‘one‘: 1}
# 可迭代对象方式来构造字典
>>> dict([(‘one‘, 1), (‘two‘, 2), (‘three‘, 3)])
{‘three‘: 3, ‘two‘: 2, ‘one‘: 1}(17)set()
- 创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。语法:
class set([iterable]),返回新的集合对象。
>>> a = set(range(10)) # 传入可迭代对象,创建集合
>>> a
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
>>> x = set(‘runoob‘)
>>> y = set(‘google‘)
>>> x, y
(set([‘b‘, ‘r‘, ‘u‘, ‘o‘, ‘n‘]), set([‘e‘, ‘o‘, ‘g‘, ‘l‘])) # 重复的被删除
>>> x & y # 交集
set([‘o‘])
>>> x | y # 并集
set([‘b‘, ‘e‘, ‘g‘, ‘l‘, ‘o‘, ‘n‘, ‘r‘, ‘u‘])
>>> x - y # 差集
set([‘r‘, ‘b‘, ‘u‘, ‘n‘])(18)frozenset()
- 返回一个冻结的不可变集合,冻结后集合不能再添加或删除任何元素,语法:
class frozenset([iterable])
>>>a = frozenset(range(10)) # 生成一个新的不可变集合
>>> a
frozenset([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> b = frozenset(‘runoob‘)
>>> b
frozenset([‘b‘, ‘r‘, ‘u‘, ‘o‘, ‘n‘]) # 创建不可变集合(19)enumerate()
- 根据可迭代对象创建枚举对象,将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中,返回enumerate(枚举)对象。语法:
enumerate(sequence, [start=0])
>>>seasons = [‘Spring‘, ‘Summer‘, ‘Fall‘, ‘Winter‘]
>>>list(enumerate(seasons))
[(0, ‘Spring‘), (1, ‘Summer‘), (2, ‘Fall‘), (3, ‘Winter‘)]
# 指定起始值,小标从1开始
>>>list(enumerate(seasons, start=1))
[(1, ‘Spring‘), (2, ‘Summer‘), (3, ‘Fall‘), (4, ‘Winter‘)]
普通for循环:
>>>i = 0
>>>seq = [‘one‘, ‘two‘, ‘three‘]
>>>for element in seq:
... print(i, seq[i])
... i += 1
for循环使用enumerate
>>>seq = [‘one‘, ‘two‘, ‘three‘]
>>>for i, element in enumerate(seq):
... print(i, seq[i])
同样输出:
0 one
1 two
2 three(20)range()
- 根据传入的参数创建一个新的range对象,注意差一行为
(21)iter()
- 用来生成迭代器,语法:iter(object[,sentinel]),sentinel--如果传递了第二个参数,则参数object必须是一个可调用的对象(如,函数),此时,iter创建了一个迭代器对象,每次调用这个迭代器对象的__next__()方法时,都会调用object。
>>> a = iter(‘abcd‘) #字符串序列
>>> a
<str_iterator object at 0x03FB4FB0>
>>> next(a)
‘a‘
>>> next(a)
‘b‘
>>> next(a)
‘c‘
>>> next(a)
‘d‘
>>> next(a)
Traceback (most recent call last):
File "<pyshell#29>", line 1, in <module>
next(a)
StopIteration(22)slice()
- 根据传入的参数创建一个新的切片对象
语法:
class slice(stop)
class slice(start, stop[, step])
# 设置截取5个元素的切片
>>>myslice = slice(5)
>>> myslice
slice(None, 5, None)
>>> arr = range(10)
>>> arr
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 截取 5 个元素
>>> arr[myslice]
[0, 1, 2, 3, 4](23)super()
- 根据传入的参数创建一个新的子类和父类关系的代理对象。用于调用父类(超类)的一个方法,可以解决多重继承问题,因为在使用多继承时,会涉及到查找顺序(MRO)、重复调用(钻石继承)等问题,无法像单继承那样直接用类名调用父类方法。
语法:super(type[, object-or-type])
# type -- 类。
# object-or-type -- 类,一般是 self
class A:
pass
class B(A):
def add(self, x):
super().add(x)(24)object()
- 创建一个新的object对象
3、序列操作(8个)
(1)all()
- 判断可迭代对象中的每个元素是否都为True值,如果是返回True,否则返回False,元素除了是0、空、False外都算True。注意:空元组、空列表返回值为True
>>> all([‘a‘, ‘b‘, ‘‘, ‘d‘]) # 列表list,存在一个为空的元素
False
>>> all([0, 1,2, 3]) # 列表list,存在一个为0的元素
False
>>> all([]) # 空列表
True
>>> all(()) # 空元组
True(2)any()
- 判断给定的可迭代对象的每个元素是否都为False值,则返回False,如果有一个为True,则返回True,元素除了是0、空、False外都算True。注意:空元组、空列表返回值为False
(3)filter()
- 使用指定方法过滤可迭代对象的元素,返回一个迭代器对象。该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回True或False,最后将返回True的元素放到新列表中。
语法:filter(function, iterable)
(4)map()
- 使用指定方法去作用传入的每个可迭代对象的元素,返回包含每次function函数返回值的新列表。
>>>def square(x) : # 计算平方数
... return x ** 2
>>> map(square, [1,2,3,4,5]) # 计算列表各个元素的平方
[1, 4, 9, 16, 25]
>>> map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 使用 lambda 匿名函数
[1, 4, 9, 16, 25]
# 提供了两个列表,对相同位置的列表数据进行相加
>>> map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10])
[3, 7, 11, 15, 19]- 如果函数有多个参数, 但每个参数的序列元素数量不一样, 会根据最少元素的序列进行。
(5)next()
- 返回迭代器对象中的下一个元素值。语法
next(iterator[,default])。函数必须接收一个可迭代对象参数,每次调用的时候,返回可迭代对象的下一个元素。如果所有元素均已经返回过,则抛出StopIteration异常;函数可以接收一个可选的default参数,传入default参数后,如果可迭代对象还有元素没有返回,则依次返回其元素值,如果所有元素已经返回,则返回default指定的默认值而不抛出StopIteration异常。
>>> a = iter(‘abcd‘)
>>> next(a)
‘a‘
>>> next(a)
‘b‘
>>> next(a)
‘c‘
>>> next(a)
‘d‘
>>> next(a)
Traceback (most recent call last):
File "<pyshell#18>", line 1, in <module>
next(a)
StopIteration
>>> next(a,‘e‘)
‘e‘
>>> next(a,‘e‘)
‘e‘(6)reversed()`` + 反转序列生成新的可迭代对象,语法:reversed(seq)`
seqList = [1, 2, 4, 3, 5]
print(list(reversed(seqList)))
输出:
[5, 3, 4, 2, 1](7)sorted()
- 对可迭代对象进行排序,返回一个新的列表。sort是应用在list上的方法,sorted可以对所有可迭代的对象进行排序操作。list的sort方法会对原始列表进行操作并返回,而内置函数sorted方法返回的是一个新list,而不是在原来的基础上进行的操作。
语法:sorted(iterable, key=None, reverse=False)
# key主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序,reverse=True降序,reverse=False升序(默认)。
>>>sorted({1: ‘D‘, 2: ‘B‘, 3: ‘B‘, 4: ‘E‘, 5: ‘A‘})
[1, 2, 3, 4, 5]
# 利用key进行倒序排序
>>>example_list = [5, 0, 6, 1, 2, 7, 3, 4]
>>> result_list = sorted(example_list, key=lambda x: x*-1)
>>> print(result_list)
[7, 6, 5, 4, 3, 2, 1, 0](8)zip()
- 聚合传入的每个迭代器中相同位置的元素,返回一个新的元组类型迭代器,这样做的好处是节约了不少的内存。如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用*号操作符,可以将元组解压为列表。
>>> a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 返回一个对象
>>> zipped
<zip object at 0x103abc288>
>>> list(zipped) # list() 转换为列表
[(1, 4), (2, 5), (3, 6)]
>>> list(zip(a,c)) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> a1, a2 = zip(*zip(a,b)) # 与 zip 相反,zip(*) 可理解为解压,返回二维矩阵式
>>> list(a1)
[1, 2, 3]
>>> list(a2)
[4, 5, 6]4、对象操作(9个)
(1)help()
- 返回对象的帮助信息
(2)dir()
- 返回对象或者当前作用域内的属性列表,语法
dir([object])
>>> import math
>>> math
<module ‘math‘ (built-in)>
>>> dir(math)
[‘__doc__‘, ‘__loader__‘, ‘__name__‘, ‘__package__‘, ‘__spec__‘, ‘acos‘, ‘acosh‘, ‘asin‘, ‘asinh‘, ‘atan‘, ‘atan2‘, ‘atanh‘, ‘ceil‘, ‘copysign‘, ‘cos‘, ‘cosh‘, ‘degrees‘, ‘e‘, ‘erf‘, ‘erfc‘, ‘exp‘, ‘expm1‘, ‘fabs‘, ‘factorial‘, ‘floor‘, ‘fmod‘, ‘frexp‘, ‘fsum‘, ‘gamma‘, ‘gcd‘, ‘hypot‘, ‘inf‘, ‘isclose‘, ‘isfinite‘, ‘isinf‘, ‘isnan‘, ‘ldexp‘, ‘lgamma‘, ‘log‘, ‘log10‘, ‘log1p‘, ‘log2‘, ‘modf‘, ‘nan‘, ‘pi‘, ‘pow‘, ‘radians‘, ‘sin‘, ‘sinh‘, ‘sqrt‘, ‘tan‘, ‘tanh‘, ‘trunc‘](3)id()
- 用于获取对象的内存地址,返回对象的唯一标识符,语法:
id([object])
(4)hash()
- 获取对象(字符串或者数值等)的哈希值,语法:
hash(object)。
>>>hash(‘test‘) # 字符串
2314058222102390712
>>> hash(1) # 数字
1
>>> hash(str([1,2,3])) # 集合
1335416675971793195
>>> hash(str(sorted({‘1‘:1}))) # 字典
7666464346782421378(5)type()
- 返回对象的类型,或者根据传入的参数创建一个新的类型。
- 注意和
isinstance()的区别:在于是否考虑继承关系;语法:(1)type(object);(2)type(name,bases,dict),有第一个参数则返回对象的类型,三个参数时返回新的类型对象。
参数:
name -- 类的名称。
bases -- 基类的元组。
dict -- 字典,类内定义的命名空间变量。
# 使用type函数创建类型D,含有属性InfoD
>>> D = type(‘D‘,(A,B),dict(InfoD=‘some thing defined in D‘))
>>> d = D()
>>> d.InfoD
‘some thing defined in D‘(6)len()
- 返回对象的长度
(7)ascii()
- 类似repr()函数,返回一个表示对象的字符串,但是对于字符串中的非ASCII字符则返回通过repr()函数使用 x, u 或 U 编码的字符。语法:
ascii(object)
>>>a = ascii(‘paul你好‘)
>>>print(a)
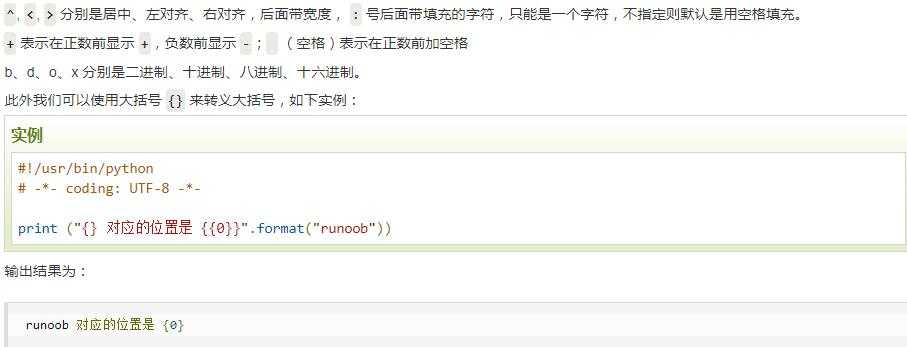
‘paulu4f60u597d‘(8)format()
- 格式化字符串的函数
str.format()。
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
‘hello world‘
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
‘world hello world‘
print("网站名:{name}, 地址 {url}".format(name="菜鸟教程", url="www.runoob.com"))
# 通过字典设置参数
site = {"name": "菜鸟教程", "url": "www.runoob.com"}
print("网站名:{name}, 地址 {url}".format(**site))
# 通过列表索引设置参数
my_list = [‘菜鸟教程‘, ‘www.runoob.com‘]
print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是**必须**的
输出:
网站名:菜鸟教程, 地址 www.runoob.com
class AssignValue(object):
def __init__(self, value):
self.value = value
my_value = AssignValue(6)
print(‘value 为: {0.value}‘.format(my_value)) # "0" 是**可选**的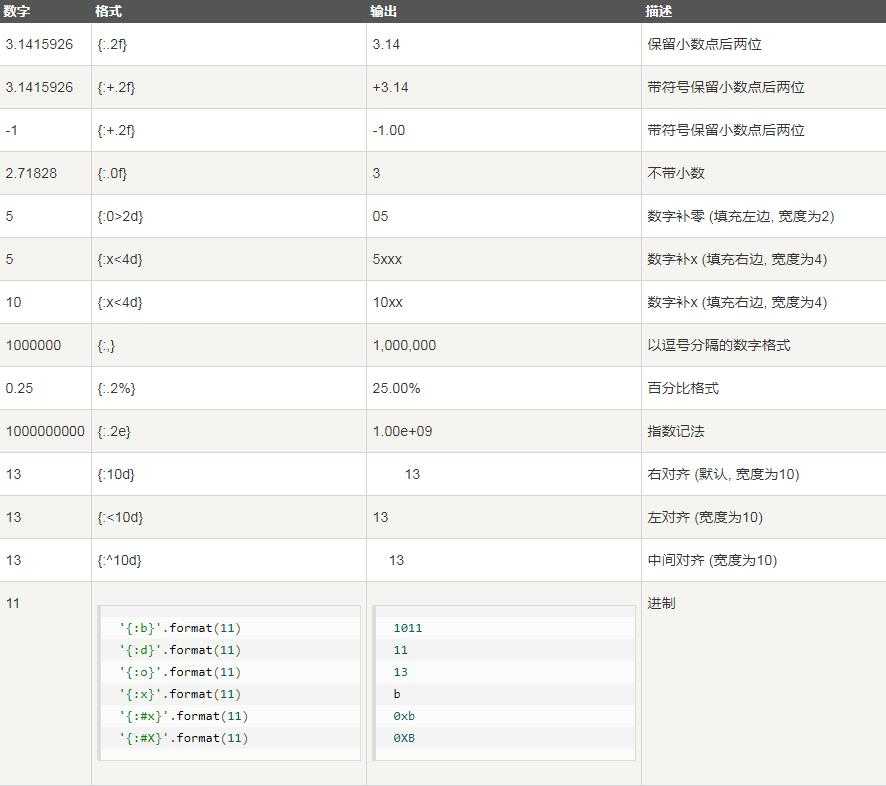
(9)vars()
- 返回当前作用域内的局部变量和其值组成的字典,或者返回对象的属性列表。语法:
vars([object]),如果没有参数,就打印当前调用位置的属性和属性值类似locals()。
>>>print(vars())
{‘__builtins__‘: <module ‘__builtin__‘ (built-in)>, ‘__name__‘: ‘__main__‘, ‘__doc__‘: None, ‘__package__‘: None}
>>> class Runoob:
... a = 1
>>> print(vars(Runoob))
{‘a‘: 1, ‘__module__‘: ‘__main__‘, ‘__doc__‘: None}
>>> runoob = Runoob()
>>> print(vars(runoob))
{}5、反射操作(8个)
(1)import()
- 动态导入模块
(2)isinstance()
- 判断对象是否是类或者类型元组中任意类元素的实例。语法:
isinstance(object,classinfo),如果对象的类型与参数二的类型(classinfo)相同则返回True,否则返回False。 - isinstance() 与type()区别:
type() 不会认为子类是一种父类类型,==不考虑继承关系==
isinstance() 会认为子类是一种父类类型,==考虑继承关系==
==如果要判断两个类型是否相同推荐使用isinstance()==
>>> isinstance (a,(str,int,list)) # 是元组中的一个返回 True
True
class A:
pass
class B(A):
pass
isinstance(A(), A) # returns True
type(A()) == A # returns True
isinstance(B(), A) # returns True
type(B()) == A # returns False(3)issubclass()
- 判断类是否是另外一个类或者类型元组中任意类元素的子类,语法:
issubclass(class,classinfo),如果class是classinfo的子类返回True,否则返回False。
>>> issubclass(bool,int)
True
>>> issubclass(bool,str)
False
>>> issubclass(bool,(str,int))
True(4)hasattr()
- 判断对象是否包含对应的属性,语法:
hasattr(object,name),如果对象有该属性返回True,否则返回False。
>>> class Student:
def __init__(self,name):
self.name = name
>>> s = Student(‘Aim‘)
>>> hasattr(s,‘name‘) #a含有name属性
True
>>> hasattr(s,‘age‘) #a不含有age属性
False(5)getattr()
- 获取对象的属性值。语法:
getattr(object, name[, default])
>>>class A(object):
... bar = 1
...
>>> a = A()
>>> getattr(a, ‘bar‘) # 获取属性 bar 值
1
>>> getattr(a, ‘bar2‘) # 属性bar2不存在,触发异常
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: ‘A‘ object has no attribute ‘bar2‘
>>> getattr(a, ‘bar2‘, 3) # 属性bar2不存在,但设置了默认值
3(6)setattr()
- 设置对象的属性值,前提是该属性必须存在。
语法:setattr(object, name, value) #(对象,字符串/对象属性,属性值)
>>>class A(object):
... bar = 1
...
>>> a = A()
# 获取属性 bar 值
>>> getattr(a, ‘bar‘)
1
# 设置属性 bar 值
>>> setattr(a, ‘bar‘, 5)
>>> a.bar
5(7)delattr()
- 删除对象的属性
delattr(x,‘foobar‘)相等于del x.foobar,语法:delattr(object,name)
(8)callable()
- 检查对象是否可被调用。如果返回True,object仍然可能调用失败;但如果返回False,调用对象ojbect绝对不会成功。对于函数、方法、lambda函式、类以及实现了
__call__方法的类实例, 它都返回True。语法:callable(object)
>>> class B: #定义类B
def __call__(self):
print(‘instances are callable now.‘)
>>> callable(B) #类B是可调用对象
True
>>> b = B() #调用类B
>>> callable(b) #实例b是可调用对象
True
>>> b() #调用实例b成功6、变量操作(2个)
(1)globals()
- 返回当前作用域内的全局变量和其值组成的字典
>>>a=‘runoob‘
>>>print(globals())
# globals 函数返回一个全局变量的字典,包括所有导入的变量。
{‘__builtins__‘: <module ‘__builtin__‘ (built-in)>, ‘__name__‘: ‘__main__‘, ‘__doc__‘: None, ‘a‘: ‘runoob‘, ‘__package__‘: None}(2)locals()
- 返回当前作用域内的局部变量和其值组成的字典
>>>def runoob(arg): # 两个局部变量:arg、z
... z = 1
... print (locals())
...
>>> runoob(4)
{‘z‘: 1, ‘arg‘: 4} # 返回一个名字/值对的字典7、交互操作(2个)
(1)print()
- 向标准输出对象打印输出
(2)input()
- 读取用户输入值
8、文件操作(1个)
(1)open()
- 使用指定的模式和编码打开文件,返回文件读写对象。在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出OSError。使用open()方法一定要保证关闭文件对象,即调用close()方法,open()函数常用形式是接收两个参数:文件名(file)和模式(mode)。
- 完整的语法格式:
open(file, mode=‘r‘, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None) - 参数说明:
file: 必需,文件路径(相对或者绝对路径)
mode: 可选,文件打开模式
buffering: 设置缓冲
encoding: 一般使用utf8
errors: 报错级别
newline: 区分换行符
closefd: 传入的file参数类型
opener:- mode参数
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
9、编译执行(4个)
(1)compile()
- 将字符串编译为代码或者AST对象,使之能够通过exec语句来执行或者eval进行求值
语法:compile(source, filename, mode[, flags[, dont_inherit]])
参数:
source -- 字符串或者AST(Abstract Syntax Trees)对象。。
filename -- 代码文件名称,如果不是从文件读取代码则传递一些可辨认的值。
mode -- 指定编译代码的种类。可以指定为 exec, eval, single。
flags -- 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
flags和dont_inherit是用来控制编译源码时的标志
>>>str = "for i in range(0,3): print(i)"
>>> c = compile(str,‘‘,‘exec‘) # 编译为字节代码对象
>>> c
<code object <module> at 0x10141e0b0, file "", line 1>
>>> exec(c)
0
1
2
>>> str = "3 * 4 + 5"
>>> a = compile(str,‘‘,‘eval‘)
>>> eval(a)
17(2)eval()
- 执行动态表达式求值(只能执行计算数学表达式的结果的功能)。语法:
eval(expression[,globals[,locals]])globals变量作用域,全局命名空间,如果被提供,则必须是一个字典对象;locals变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
>>>x = 7
>>> eval( ‘3 * x‘ )
21
>>> eval(‘pow(2,2)‘)
4
>>> eval(‘2 + 2‘)
4
>>> n=81
>>> eval("n + 4")
85(3)exec()
- 执行动态语句块,语法:
exec(object[,globals[,locals]]),返回值永远为None。(object:必选参数,表示需要被指定的Python代码。它必须是字符串或code对象。如果object是一个字符串,该字符串会先被解析为一组Python语句,然后在执行(除非发生语法错误)。如果object是一个code对象,那么它只是被简单的执行)
x = 10
expr = """
z = 30
sum = x + y + z
print(sum)
"""
def func():
y = 20 # 局部变量y
exec(expr)
exec(expr, {‘x‘: 1, ‘y‘: 2})
exec(expr, {‘x‘: 1, ‘y‘: 2}, {‘y‘: 3, ‘z‘: 4})
# 在expr语句中,有三个变量x,y,z,其中z值已给定,我们可以在exec()函数外指定x,y的值,也可以在exec()函数中以字典的形式指定x,y的值。在最后的语句中,我们给出了x,y,z的值,并且y值重复,exec()函数接收后面一个y值,且z值传递不起作用,因此输出结果为34
func()
输出:
60
33
34
eval()函数和exec()函数的区别:
eval()函数只能计算单个表达式的值,而exec()函数可以动态运行代码段。
eval()函数可以有返回值,而exec()函数返回值永远为None。(4)repr()
- 返回一个对象的字符串表现形式(给解释器),语法:
repr(object)
>>>s = ‘RUNOOB‘
>>> repr(s)
"‘RUNOOB‘"
>>> dict = {‘runoob‘: ‘runoob.com‘, ‘google‘: ‘google.com‘};
>>> repr(dict)
"{‘google‘: ‘google.com‘, ‘runoob‘: ‘runoob.com‘}"10、装饰器(3个)
(1)property
- 标示属性的装饰器,语法:
class property([fget[, fset[, fdel[, doc]]]])
参数:
fget -- 获取属性值的函数
fset -- 设置属性值的函数
fdel -- 删除属性值函数
doc -- 属性描述信息
# 将 property 函数用作装饰器可以很方便的创建只读属性
class Parrot(object):
def __init__(self):
self._voltage = 100000
@property
def voltage(self):
"""Get the current voltage."""
return self._voltage
# 上面的代码将 voltage() 方法转化成同名只读属性的getter方法。property的getter,setter 和deleter方法同样可以用作装饰器:
class C(object):
def __init__(self):
self._x = None
@property
def x(self):
"""I‘m the ‘x‘ property."""
return self._x
@x.setter
def x(self, value):
self._x = value
@x.deleter
def x(self):
del self._x
>>> class C:
def __init__(self):
self._name = ‘‘
@property
def name(self):
"""i‘m the ‘name‘ property."""
return self._name
@name.setter
def name(self,value):
if value is None:
raise RuntimeError(‘name can not be None‘)
else:
self._name = value
>>> c = C()
>>> c.name # 访问属性
‘‘
>>> c.name = None # 设置属性时进行验证
Traceback (most recent call last):
File "<pyshell#84>", line 1, in <module>
c.name = None
File "<pyshell#81>", line 11, in name
raise RuntimeError(‘name can not be None‘)
RuntimeError: name can not be None
>>> c.name = ‘Kim‘ # 设置属性
>>> c.name # 访问属性
‘Kim‘
>>> del c.name # 删除属性,不提供deleter则不能删除
Traceback (most recent call last):
File "<pyshell#87>", line 1, in <module>
del c.name
AttributeError: can‘t delete attribute
>>> c.name
‘Kim‘(2)classmethod
- 标示方法为类方法的装饰器,classmethod修饰符对应的函数不需要实例化,不需要self参数,但第一个参数需要是表示自身类的cls参数,可以来调用类的属性,类的方法,实例化对象等。返回函数的类方法。
class A(object):
bar = 1
def func1(self):
print (‘foo‘)
@classmethod
def func2(cls):
print (‘func2‘)
print (cls.bar)
cls().func1() # 调用 foo 方法
A.func2() # 不需要实例化(3)staticmethod
- 标示方法为静态方法的装饰器,该方法不强制要求传递参数,如声明一个静态方法。
class C(object):
@staticmethod
def f(arg1, arg2, ...):
pass
# 以上实例声明了静态方法f,类可以不用实例化就可以调用该方法C.f(),当然也可以实例化后调用C().f()。
class C(object):
@staticmethod
def f():
print(‘runoob‘);
C.f() # 静态方法无需实例化
cobj = C()
cobj.f() # 也可以实例化后调用
# 使用装饰器定义静态方法
>>> class Student(object):
def __init__(self,name):
self.name = name
@staticmethod
def sayHello(lang):
print(lang)
if lang == ‘en‘:
print(‘Welcome!‘)
else:
print(‘你好!‘)
>>> Student.sayHello(‘en‘) #类调用,‘en‘传给了lang参数
en
Welcome!
>>> b = Student(‘Kim‘)
>>> b.sayHello(‘zh‘) #类实例对象调用,‘zh‘传给了lang参数
zh
你好参考:
1、RUNOOB.COM-Python3 内置函数
2、博客园-十月狐狸-Python内置函数详解——总结篇 ==(强烈推荐)==
以上是关于Python3中的68个内置函数总结的主要内容,如果未能解决你的问题,请参考以下文章