Flume相关文章汇集
Posted cbwcbj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flume相关文章汇集相关的知识,希望对你有一定的参考价值。
flume安装:
https://blog.csdn.net/u011254180/article/details/80000763
1 运行机制
1、 Flume分布式系统中最核心的角色是agent,flume采集系统就是由一个个agent所连接起来形成
2、每一个agent相当于一个数据传递员,内部有三个组件:
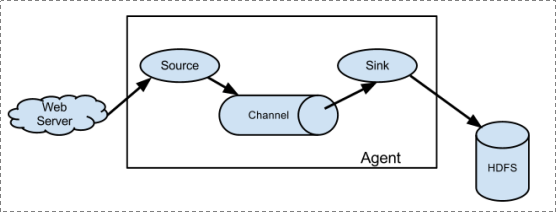
a) Source:采集源,用于跟数据源对接,以获取数据
b) Sink:下沉地,采集数据的传送目的,用于往下一级agent传递数据或者往最终存储系统传递数据
c) Channel:angent内部的数据传输通道,用于从source将数据传递到sink
2.Flume采集系统结构图
2.1 简单结构: 单个agent采集数据
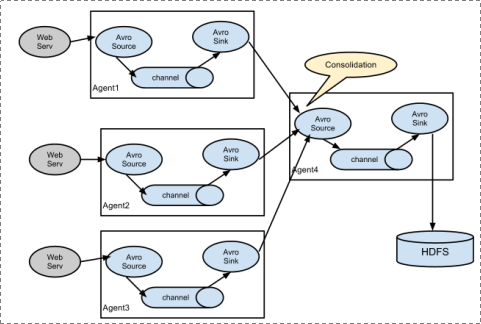
2.2 复杂结构: 多级agent之间串联
3 Flume实战案例
1、Flume的安装非常简单,只需要解压即可,当然,前提是已有hadoop环境
上传安装包到数据源所在节点上
然后解压 tar -zxvf apache-flume-1.6.0-bin.tar.gz
然后进入flume的目录,修改conf下的flume-env.sh,在里面配置JAVA_HOME
2、根据数据采集的需求配置采集方案,描述在配置文件中(文件名可任意自定义)
3、指定采集方案配置文件,在相应的节点上启动flume agent
注:
Source——日志来源,其中包括:Avro Source、Thrift Source、Exec Source、JMS Source、Spooling Directory Source、Kafka Source、NetCat Source、Sequence Generator Source、Syslog Source、HTTP Source、Stress Source、Legacy Source、Custom Source、Scribe Source以及Twitter 1% firehose Source。
Channel——日志管道,所有从Source过来的日志数据都会以队列的形式存放在里面,它包括:Memory Channel、JDBC Channel、Kafka Channel、File Channel、Spillable Memory Channel、Pseudo Transaction Channel、Custom Channel。
Sink——日志出口,日志将通过Sink向外发射,它包括:HDFS Sink、Hive Sink、Logger Sink、Avro Sink、Thrift Sink、IRC Sink、File Roll Sink、Null Sink、HBase Sink、Async HBase Sink、Morphline Solr Sink、Elastic Search Sink、Kite Dataset Sink、Kafka Sink、Custom Sink。
以上是关于Flume相关文章汇集的主要内容,如果未能解决你的问题,请参考以下文章