KMP算法
Posted authetic
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KMP算法相关的知识,希望对你有一定的参考价值。
概述
KMP(Knuth-Morris-Pratt)算法是一种用来解决字符串匹配问题的算法,时间复杂度为O(n+m),主要思想是当模式串与主串发生失配时,不必从头开始匹配,而是滑动到已经匹配的部分
next数组
在KMP算法中,next数组用来存储一段子串最大相等前后缀的长度加1,例如长度为i+1的字符串,它的最大相等前后缀分别为0~k和i-k~i,则next[i]=k,这里k小于i。
问题在于如何去求next数组,遍历的话KMP算法就没什么意义了,但仔细观察就可以发现next[i]的值可以由已求出的next数组的值推导出
求next[i+1]只需考虑两种情况
- s[i+1] == next[i] + 1,则next[i+1] = next[i] + 1
- s[i+1] != next[i] = 1
对于第二种情况,我们需要一个变量j,我们令j=next[next[i]],如果s[i+1] == s[j+1],则next[i+1]=j+1。我认为整个KMP的精髓就在这里,这也是最难理解的一步。其实再看一下next数组的意义就知道了,这里s[0~j]肯定等于s[i-j~i],这里的一部分就是s[next[i]]所匹配出来的最大前后缀,如图所示
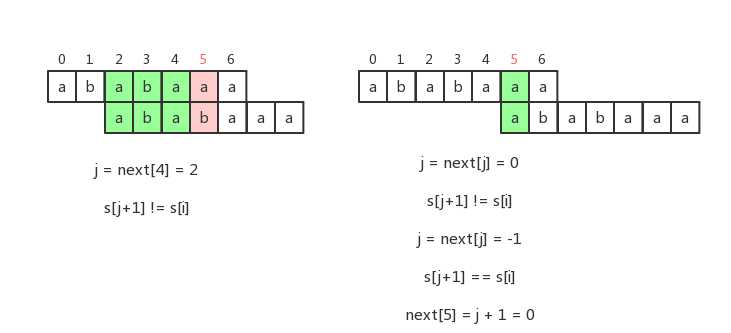
这样我们就可以轻松的求出next数组了
void getnext(char s[], int len) {
int j = -1, next[0] = -1;
for(int i = 0; i < n; i ++ ) {
while (j != -1 && s[i] != s[j+1]) {
j = next[j];
}
if (s[i] == s[j+1]) {
j++;
}
next[i] = j;
}
}KMP算法的实现
命名变量i和j,i表示主串预匹配的下标,j表示模式串已匹配的下标,那么每次匹配过程无非有两种情况
- text[i] == pattern[j+1]
- text[i] != pattern[j+1]
对于第二种情况,我们不断地让j=next[j],直到text[i] == pattern[j+1]或者j等于-1
算法实现
bool KMP(char text[], char pattern[]) {
int n = strlen(text), m = strlen(pattern);
int next[m];
getnext(pattern, m);
int j = -1;
for (int i = 0; i < n; i ++ ) {
while (j != -1 && text[i] != pattern[j+1]) {
j = next[j];
}
if (text[i] == pattern[j+1]) {
j++;
}
if (j == m-1) {
return true;
}
}
return false;
}算法优化
在while循环里每次回退找到j的过程可以更快一些,通过优化求解next数组的部分,因为如何已知s[j+1]==s[i+1],j肯定还要回退,我们直接让next数组存储每次适配时需要回到的那个j
void getnextval(char s[], int len) {
int j = -1, nextval[0] = -1;
for (int i = 0; i < len; i ++ ) {
while (j !=1 && s[j+1] != s[i]) {
j = nextval[i];
}
if (s[j+1] == s[i]) {
j++;
}
if (j == -1 || s[j+1] != s[i+1]) {
nextval[i] = j;
} else {
nextval[i] = nextval[j];
}
}
}以上是关于KMP算法的主要内容,如果未能解决你的问题,请参考以下文章