GIThttp://blog.csdn.net/weishinexk/article/details/51454167
一. git 概述
1. git 简介?
-
什么是git?
> git是一款开源的分布式版本控制工具> 在世界上所有的分布式版本控制工具中,git是最快、最简单、最流行的- 1
- 2
- 3
-
git的起源?
> 作者是Linux之父:Linus Benedict Torvalds> 当初开发git仅仅是为了辅助Linux内核的开发(管理源代码)- 1
- 2
- 3
-
git的现状?
> 在国外已经非常普及,国内并未普及(在慢慢普及)> 越来越多的开源项目已经转移到git- 1
- 2
- 3
2. 常见的源代码管理工具有哪些?
> CVS - 开启版本控制之门 - 1990年诞生,“远古时代”的主流源代码管理工具> SVN - 全称是Subversion,集中式版本控制之王者 - 是CVS的接班人,速度比CVS快,功能比CVS多且强大 - 在国内软件企业中使用最为普遍(70%-90%)> ClearCase - 收费的集中式版本控制工具,安装比Windows还大,运行比蜗牛还慢 - 能用ClearCase的一般是世界500强,他们有个共同的特点是财大气粗或者人傻钱多> VSS - 微软的集中式版本控制工具,集成在Visual Studio中
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3. 集中式版本控制
所有的代码都集中在一块, 统一进行管理
4. 分布式版本控制
在每个客户端都有一份完整的代码仓库, 可以在每个客户端自行管理
5. git 和 svn的简单对比
> 速度 在很多情况下,git的速度远远比SVN快> 结构 SVN是集中式管理,git是分布式管理> 其他 SVN使用分支比较笨拙,git可以轻松拥有无限个分支 SVN必须联网才能正常工作,git支持本地版本控制工作 旧版本的SVN会在每一个目录置放一个.svn,git只会在根目录拥有一个.git
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
6. SVN工作流程和GIT工作流程对比
- svn checkout —— git clone svn 只下载代码, git 会连同代码仓库一起下载下来- svn commit —— git commit svn 是提交到服务器,git 中是提交到本地仓库,需要使用push才能提交到服务器- svn update - git pull 都是从服务器下载最新被修改的代码
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
分布式和集中式最大的区别在于:在分布式下,本地有个代码仓库,开发者可以在本地提交; 而集中式版本控制, 只有在服务器才有一个代码仓库, 只能在服务器进行统一管理
7. git工作原理
-
概念理解
- 工作区 > 与.git文件夹同级的其他文件夹或者子文件夹- 版本控制库 > 暂缓区 > 分支(Git不像SVN那样有主干和分支的概念. 仅仅存在分支,其中master分支为默认被创建的分支,类似于SVN中的主干) 切换分支:通过控制HEAD指针指向不同的分支,就可以切换*- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
* 操作原则: 所有新添加/删除/修改的文件 必须先添加到暂缓区,然后才能提交到HEAD指向的当前分支中*
8. git使用环境
-
单人开发只需要一个本地库
原因:不需要与他人共享代码,只负责管理自己代码即可;例如提交代码,删除代码,版本控制等等- 1
- 2
-
多人开发时需要一个共享版本库
共享版本库的形式: 本地共享库:文件夹/U盘/硬盘 远程共享库:自己搭建git服务器/ 托管到第三方平台(例如github, oschina)- 1
- 2
- 3
- 4
-
使用环境
* 无论是单人开发还是多人开发,客户端都可以使用命令行或者图形界面使用git*> SourceTree - 下载地址:http://www.sourcetreeapp.com/download/>; GitHub - 下载地址:https://mac.github.com - 不过它是专门为GitHub网站而设计的> Xcode - 虽然集成较好,但是只能做一些常用的简单操作,复杂操作还要使用命令行- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
二. Git命令行演练-个人开发
0. 如何学习git指令
> git help [子命令] > 和学习SVN指令是一样的,只不过git是通过使用指南的形式展示给用户看(不能编辑的vim编辑器),使用q退出vim编辑器,按空格进入下一页,ctrl + B 回到上一页; /关键字 进行搜索
- 1
- 2
- 3
1. 初始化一个本地仓库
> 原因: 管理本地代码,修改上传,版本回退 > 命令: git init
- 1
- 2
- 3
2. 配置仓库
> 告诉git你是谁? 原因: 追踪修改记录 命令: git config user.name “shunzi” > 告诉git怎样联系你? 原因: 多人合作开发时, 沟通交流 命令: git config user.email "[email protected]" > 查看配置信息(.git -> config打开) 命令: git config -l
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3. 个人开发演练
> 创建文件并提交 命令: touch main.c git add . git commit -m “注释” > 修改文件并提交 命令: git add . git commit -m “注释” > 删除文件并提交 命令: git rm person.h git commit -m “注释” > 日志查看 命令: git log git reflog > 版本回退 命令: git reset —hard HEAD 重置到当前版本 git reset —hard HEAD^^ 重置到上上个版本 git reset ——hard HEAD2 重置到往上2个版本 git reset —hard 七位版本号 重置到指定版本::
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
5. 备注补充
-
文件状态(git status)
> 颜色含义 红色: 代表被添加或者修改的文件没有被添加到暂缓区 绿色: 代表文件在暂缓区,等待提交> 版本号的含义 版本号是一个由SHA1生成的40位哈希值 这样做的目的是保证版本号的唯一- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
vim编辑器的使用
命令模式:等待编辑命令输入;所有输入的内容都被当做命令来执行插入模式:输入的所有内容都被显示,并被当做文件内容处理命令行模式:执行待定命令(保存文件并退出vim : wq ; 强制退出不保存: q! )- 1
- 2
- 3
- 4
-
日志查看配置
命令如下: git config --global alias.lg "log --color --graph --pretty=format:‘%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)\\<%an\\>%Creset‘ --abbrev-commit"- 1
- 2
- 3
-
配置别名
git config alias.st “status”git config alias.ci “commit -m”- 1
- 2
- 3
-
–global的作用
可以进行全局配置,所有的版本库共享此配置查看全局配置(桌面前往->个人->.gitconfig** 个人电脑上建议使用全局配置**- 1
- 2
- 3
- 4
三. Git命令行演练-团队开发
* 团队开发必须有一个共享库,这样成员之间才可以进行协作开发*
0. 共享库分类
> 本地共享库(只能在本地面对面操作) - 电脑文件夹/U盘/移动硬盘 > 远程共享库(可通过网络远程操作) - 自己搭建Git服务器(**不建议**) - 在Github上托管项目(** 建议**) Github网址(https://github.com); 公开项目免费, 私有项目收费 - 在OSChina上托管项目(** 推荐**) OSChina网址(https://git.oschina.net) 安全免费,在国内访问速度快
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
1. 搭建本地共享库
原因: 多人合作开发,代码共享 命令: git init —-bare
- 1
- 2
- 3
2. 经理初始化项目到本地共享库
命令: git clone 本地代码仓库地址
- 1
- 2
3. 演示多人开发
> 创建文件夹manager, niuda 命令: mkdir manager mkdir niuda > 分别进入到两个文件夹从共享库clone项目到本地 命令: git clone 本地代码仓库地址 git clone 本地代码仓库地址 > 演练新增文件同步 命令: touch person.h git add . git commit -m “创建person.h” git push git pull > 演练修改文件同步 命令: git add . git commit -m “注释” git push git pull > 演练删除文件同步 命令: git rm filename git commit -m “注释” git push git pull > 演练冲突解决 命令: git pull > 演练忽略文件 命令: touch .gitignore open .gitignore 加入忽略文件名 git add . git commit -m “注释” .gitignore文件配置规则http://www.cnblogs.com/haiq/archive/2012/12/26/2833746.html
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
4. 备注笔记
> 关于忽略文件 在真实开发中,配置.gitignore文件 , 去github里面搜索gitignore 选择OC版本的,拷贝到本地仓库即可,记得添加到本地版本库 > 常见问题 fetch first 代表当前文件过期,需要从远程共享库更新 git pull
- 1
- 2
- 3
- 4
- 5
- 6
- 7
四. Git-XCode演练-团队开发
1. 搭建本地共享版本库
命令: git init —-bare
- 1
- 2
2. 经理初始化项目到共享版本库
** 注意: 添加忽略文件, 不然Xcode有可能会把没必要的文件提交**** 必须在使用Xcode之前把忽略文件添加进来, 因为Xcode创建工程时, 默认直接把所有文件添加到暂缓区, 加进去之后忽略文件对其就无效了**
- 1
- 2
- 3
3. 牛大,牛二使用Xcode 克隆项目
4. 演练添加文件同步
5. 演练修改文件同步
6. 演练删除文件同步
7. 演练冲突
五. github的使用
1. 托管项目到github
- 打开github网站:[https://www.github.com]
- 注册账号(OneShunzi)
- 点击创建新仓库[https://github.com/new]
- 填入项目名称,描述等信息
- 创建完成
- 可根据生成的版本库地址进行克隆下来进行操作
2. 怎样加入合作伙伴
- 点击”个人” -> setting -> SSH keys -> Add SSH key
- 将你小伙伴生成的公钥添加进来即可.(以下是生成公钥私钥方法)
[https://help.github.com/articles/generating-ssh-keys/]
3. 怎样将其他著名框架添加到我们的代码仓库?
- 搜索到对应的框架
- 点击fork
-
当项目被移到自己代码仓库中,就可以根据地址克隆下来进行操作
** 注意: 你可以针对此框架进行任意修改,但是仅仅作用在你的本地仓库中的副本,对原作者项目没有任何影响. 如果想向原作者提建议,可以直接使用,pull request操作. 提交完成后,原作者可以在pull request中看到你的提交.至于是否采纳,就是原作者的意愿- 1
- 2
- 3
- 4
- 5
六. OSChina的使用
1. 托管项目到OSChina
- 打开oschina网站:[https://git.oschina.net]
- 注册账号(OneShunzi)
- 点击创建新仓库[https://git.oschina.net/projects/new]
- 填入项目名称,描述等信息
- 创建完成
- 可根据生成的版本库地址进行克隆下来进行操作
2. 怎样加入合作伙伴?
- 点击”管理”->项目成员管理->选择成员权限进行创建
-
或者直接只用SSH(以下是生成公钥私钥方法)
> 部署公钥允许以只读的方式访问项目,主要用于项目在生产服务器的部署上,免去HTTP方式每次操作都要输入密码和普通SSH方式担心不小心修改项目代码的麻烦。 > [https://help.github.com/articles/generating-ssh-keys/]- 1
- 2
- 3
3. 怎样将其他著名框架添加到我们的代码仓库?
- 搜索到对应的框架
- 点击fork
-
当项目被移到自己代码仓库中,就可以根据地址克隆下来进行操作
** 注意: 你可以针对此框架进行任意修改,但是仅仅作用在你的本地仓库中的副本,对原作者项目没有任何影响. 如果想向原作者提建议,可以直接使用,pull request操作. 提交完成后,原作者可以在pull request中看到你的提交.至于是否采纳,就是原作者的意愿- 1
- 2
- 3
- 4
- 5
七. 新人服务器搭建(补充了解)
-
新人服务器搭建概念原因?
概念: 搭建一个临时共享版本库, 供新人专用原因: 防止新人刚到时,搞乱服务器上的项目- 1
- 2
- 3
-
新建一个文件夹,newBee,作为新人服务器
- 进入文件夹 使用git init —-bare 初始化仓库
- 经理打开自己项目所在文件夹,执行PULL ,更新到最新
-
然后source control ->项目master -> configure 项目
> 选择Remotes 选项 代表当前所连的远程服务器地址> 点击+号 添加 将newBee文件路径作为另外一个远程服务器地址 file:// 协议开头 结尾以/结尾> Done- 1
- 2
- 3
- 4
-
经理将最新代码提交到新人远程仓库
- 经理分配新人服务器地址给新人
- 新人各种折腾
- 经理建立文件夹,从新人服务器下载代码检查
-
图解
八. Git版本备份/分支管理(补充了解)
* 在git中不是通过拷贝代码来解决备份和开启分支的*
* git 直接打标签, 通过控制head指向,来回到任一版本*
1.版本备份
-
建立共享库
> 创建文件夹shareWeibo> 进入文件夹后,初始化共享库 git init ——bare- 1
- 2
- 3
- 4
-
经理克隆项目后开发完1.0版本,打标签后,上传共享库
> 创建manager文件夹> 进入文件夹后 git clone 共享库绝对路径> 进入工作区,配置姓名,邮箱 git config user.name “manager” git config user.email “[email protected]”> 经理创建文件,并修改部分代码,提交代码,上传到共享库,完成v1.0版本 touch main.c open main.c:: 打开后写入abc git add . git commit -m “完成1.0版本开发” git push> 经理给此版本打标签,并将标签上传到共享库 git tag -a v1.0 -m “标记1.0版本” git push origin v1.0> 经理继续开发2.0版本......并提交 git add . git commit -m “2.0部分功能” git push- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2. 已发布版本bug修复
在以上步骤基础上做以下操作
-
牛大克隆项目,根据1.0版本创建分支,修复bug
> 创建niuda文件夹> 进入文件夹后 git clone 共享库绝对路径> 进入工作区,配置姓名,邮箱 git config user.name “niuda” git config user.email “[email protected]”> 根据v1.0版本建立新分支v1.0fixbug并切换到此分支 git checkout v1.0 -b v1.0fixbug::> 修复bug后提交到本地版本库- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
* 注意此处提交到的是HEAD指向的分支-v1.0fixbug*
git add . git commit -m “修复bug”- 1
- 2
- 3
-
牛大修复bug后,打标签v1.1作版本备份,并上传共享库
git tag -a v1.1 -m “1.1版本备份”git push origin v1.1- 1
- 2
- 3
-
牛大上传整个分支到共享版本库
git push origin v1.0fixbug- 1
- 2
* ———至此,分支修复bug结束,下面经理要合并分支———*
-
经理从共享库更新代码到本地库
git pull- 1
- 2
-
经理查看当前服务器都有哪些分支
git branch -r- 1
- 2
-
经理切换到master分支后,将v1.0fixbug分支合并过来
git checkout mastergit merge origin/v1.0fixbug -m “合并分支”- 1
- 2
- 3
-
经理合并完成后提交到共享库
git add .git commit -m “合并分支”git push- 1
- 2
- 3
- 4
-
合并完成后,可以删除共享库的分支
git branch -r -d origin/v1.0fixbug- 1
- 2
-
查看版本标签,至此结束!!
git tag
趁着最近工作清闲,学习一下Git的源码。搜了一下网上没有这方面的资料,只能自己慢慢的看。为了降低难度,并且更好的理解Git的发展历程,我决定从最初版的Git开始看起,跟着Git学Git。
选择Git v0.99开始学习。从https://github.com/git/git/tree/v0.99/处下载源码,这个版本的Git非常简单,功能也很少,可以从中看到初期Git设计的初衷。Clone下来之后,reset到第一次commit,开始源码的阅读之旅。
第一次Commit的文件很少,目录结构如下所示:

编译
依赖包:libssl-dev、zlib
修改编译选项:Makefile中LIBS= -lcrypto -lz
编译完成之后在~/bin/下会产生以下命令:cat-file、commit-tree、init-db、read-tree、show-diff、update-cache、write-tree。
用法
1、使用init-db初始化工作目录,类似于git init的作用。
2、项目编写,增删改各种文件等等。
3、使用update-cache [file-path],保存更改至缓存中。这会生成一个index文件,改文件用于保存当前的cache。
4、使用write-tree提交缓存中的更改。这会生成一个tree文件,当前的cache中的文件会写入到tree文件中去。命令结果会返回tree文件的sha1值。
5、使用commit-tree <tree-sha1> [-p parent-sha1]* < changelog提交这次更改。如果没有parent的信息,就会当做是第一次提交。有的话就表示改次提交是在parent基础上提交的。这里也只是一个信息的记录,其实并不会检查是否存在child-parent的关系。
6、工具命令show-diff,用来比较当前工作目录下的文件和cache中(即index文件)记录的文件的区别。
7、工具命令cat-file <SHA1>,查看某个sha1文件。会生成一个TEMP文件用来保存改SHA1文件中的内容。
概念
1、The Object Database(SHA1_FILE_DIRECTORY)
这是一个用于存储SHI1文件的文件数据库,其实本质上只是一个文件夹,用于存放所提交的文件。文件包含Metadata信息和Blob内容,经由Zlib压缩后算出SHA1,该SHA1的前2位作为子文件夹名,后38位作为文件名。Directory如下图所示。
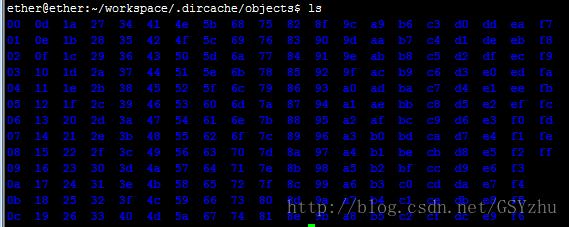
这里存放的文件包括三种:tree、blob和commit。
Tree:tree文件中存放的是所提交的文件列表,每一行描述所记录的一个文件,包括:文件的权限、路径名、SHA1值。这个就能够用于保存每一次提交的具体内容,通过查询tree文件,可以知道该次提交时所含有的所有文件,然后根据每一个文件的SHA1,可以在object database中搜索出该文件。这样就达到了保存每一次提交的具体内容的目的。
BLOB:blob文件是指具体的文件内容,即我们所提交的文件。Blob文件会被压缩,然后计算SHA1值,所以如果文件的内容没有发生变化,那么就不会产生新的Blob文件。因为它们算出的SHA1是相同的,而SHA1值就是它们实际的存放路径。
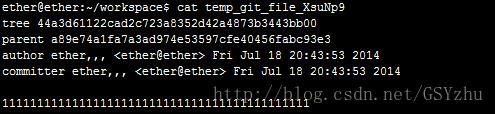
Commit:commit文件是用于记录每一次提交的文件。包含的内容有:tree、parents、author、committer、changelog。其中tree是指用于保存此次提交的tree文件。Parents是指此次提交的父分支是哪些,也是对应的tree文件。Author、committer、changelog是提交的记录信息。
一个commit文件的例子:
源码分析
init-db.c
该文件的工作很简单,就是在工作目录下创建一个.dircache的目录,并在其中创建objects目录作为database的主目录,在objects中,创建了从00到ff一共255个子目录。这些子目录将被用来存储SHA1文件。如计算出sha1值为b7140ba6976a2a2bf3cb31bf3aa2bd3e3619d521的文件,将被保存为.dircache/objects/b7/140ba6976a2a2bf3cb31bf3aa2bd3e3619d521
Update-cache.c
该文件实现了update-cache命令,主要流程为:从index中读取cache,根据传入的file,添加或者替换cache,讲新的cache写回index文件。
下面分几个主要部分记录主要的代码工作。
1、index文件的更新。
这里使用的方式是先更新内存中的cache内容,然后create一个index.lock文件,将新的cache写入index.lock文件中,然后将index.lock改名为index。
2、Cache的更新。
Cache在内存中使用一个数组保存,本地使用index文件存储。通常是从index文件中读取到数组中。Cache中的条目根据cache->name有序排放,更新cache时,会通过二分查找检查该条目是否在cache中,如果已存在则进行替换,否则直接加入到cache中(注意有序排放)。
Show-diff.c
这里需要解释的是,实际的工作是通过diff命令来实现的。为了避免所有的文件都会调用diff,先通过比较文件的属性来判断文件是否发生了改变。如果已经能够判断出文件未发生改变,就无需再调用diff来比较新旧文件。此外,没有加入到cache中的文件不会被比较,也就是说对于添加和删除文件来说,这里是不能看到diff的结果的。并且如果是删除文件的话,使用show-diff还会报segment fault.
代码的大致逻辑:从index中读取cache到数组中,根据cache_entry->name找到工作目录下的文件(即新的文件),根据cache_entry->sha1从objects中读取旧的文件,使用cache_entry中存放的旧文件的属性和新文件的stat比较,如果不同则调用diff来显示两者的差异。
总结:
从这个最初版的git中可以看到我们日常使用的git的一点影子。它能够跟踪项目的版本,但是还没有实现控制的功能。使用文件database的方式存储历史文件,并且利用sha1来简单的实现文件的复用,即相同的blob只需要存储一份。目前能够查看历史版本的文件,能够手动的记录提交的信息,手动的跟踪版本更新的信息。从今天的角度来看,但是这些功能都有待优化,优化的初衷就是更加易用。期待着它一步一步变成今天强大的Git!
附上Linus在这个版本README中对Git的描述:
"git" can mean anything, depending on your mood.
- random three-letter combination that is pronounceable, and not
actually used by any common UNIX command. The fact that it is a
mispronounciation of "get" may or may not be relevant.
- stupid. contemptible and despicable. simple. Take your pick from the
dictionary of slang.
- "global information tracker": you‘re in a good mood, and it actually
works for you. Angels sing, and a light suddenly fills the room.
http://blog.csdn.net/gsyzhu/article/details/38065765
Git --- The stupid content tracker, 傻瓜内容跟踪器。Linus 是这样给我们介绍 Git 的。
Git 是用于 Linux 内核开发的版本控制工具。与常用的版本控制工具 CVS, Subversion 等不同,它采用了分布式版本库的方式,不必服务器端软件支持,使源代码的发布和交流极其方便。 Git 的速度很快,这对于诸如 Linux kernel 这样的大项目来说自然很重要。 Git 最为出色的是它的合并跟踪(merge tracing)能力。
实际上内核开发团队决定开始开发和使用 Git 来作为内核开发的版本控制系统的时候,世界开源社群的反对声音不少,最大的理由是 Git 太艰涩难懂,从 Git 的内部工作机制来说,的确是这样。但是随着开发的深入,Git 的正常使用都由一些友好的脚本命令来执行,使 Git 变得非常好用,即使是用来管理我们自己的开发项目,Git 都是一个友好,有力的工具。现在,越来越多的著名项目采用 Git 来管理项目开发,例如:wine, U-boot 等,详情看 http://www.kernel.org/git
Git架构
commit-tree commit obj +----+ | | | | V V +-----------+ | Object DB | | Backing | | Store | +-----------+ ^ write-tree | | tree obj | | | | read-tree | | tree obj V +-----------+ | Index | | "cache" | +-----------+ update-index ^ blob obj | | | | checkout-index -u | | checkout-index stat | | blob obj V +-----------+ | Working | | Directory | +-----------+git 使用“三大数据结构”来完成它的工作,当前工作目录、“index file”(index cache) 和 git仓库。 git commit 会将 index file 中的改变写到 git 仓库;git add 会将“当前工作目录”的改变写到“index file”;“commit -a”则会直接将“当前工作目录”的改动同时写到“index file”和“git仓库”。
将 Current working directory 记为 (1), 将 Index file 记为 (2), 将 Git repository 记为 (3), 他们之间的提交层次关系是 (1) -> (2) -> (3) 。git add 完成的是(1) -> (2),git commit 完成的是(2) -> (3),git commit -a 是两者的直接结合。从时间上看,可以认为(1)是最新的代码,(2)比较旧,(3)更旧。
git diff 得到的是从(2)到(1)的变化。git diff –cached 得到的是从(3)到(2)的变化。 git diff HEAD 得到的是从(3)到(1)的变化。
Git简单用法
转载自 http://roclinux.cn/?p=371 (需要注明作者,文章题名;另外,该段内容属于使用问题,因该移到其他页面。)
独立开发者的最大特点就是他们不需要和其他人来交换补丁,而且只在一个独立的固定的git仓库中工作。
下面这些命令将可以帮助你完成日常工作:
git-show-branch:可以显示你当前所在的分支以及提交记录。
git-log:显示提交日志
git-checkout或者git-branch:用于切换日志
git-add:用于将修改内容加入到index文件中
git-diff和git-status:用于显示开发者所做的修改
git-commit:用于提交当前修改到git仓库。
git-reset和git-checkout:用于撤销某些修改
git-merge:用于合并两个分支
git-rebase:用于维护topic分支(此处我也不太懂,等完成git学习后转过头来会关注此问题)
git-tag:用于标记标签。
1)获得帮助可以使用类似man git-****的命令格式:想获得关于commit命令的帮助,则man git-commit想获得关于pull命令的帮助,则man git-pull想获得关于merge命令的帮助,则man git-merge以此类推
2)任何人在使用git之前,都要提交简单的个人信息,以便git区分不同的提交者身份。
- git config –global user.name “your name”
- git config –global user.email [email protected]
3)想新开启一个项目,应该先建立一个目录,例如名为myproject,然后所有的项目开发内容都在此目录下进行。
- cd myproject
- git init
- git add .
- git commit //这个步骤会自动进入编辑状态,要求提交者输入有关本次提交的“开发信息”
至此,一个新项目就诞生了,第一个开发信息(开发日志)也随之诞生。
4)如果改进了项目源代码,并且到了开发者认为“应该再次记录开发信息”的时候,则提交“工作成果”。
- git commit -a //这是一个偷懒的命令,相当于git add .; git commit;
5)想检查到目前为止对源码都做了哪些修改(相对于本次工作刚开始之时):
- git diff //这个命令只在git add之前使用有效。如果已经add了,那么此命令输出为空
- git diff –cached //这个命令在git add之后在git commit之前有效。
- git status //这个命令在git commit之前有效,表示都有哪些文件发生了改动
6)想查看自项目开启到现在的所有开发日志
- git log
- git log -p //会输出非常详细的日志内容,包括了每次都做了哪些源码的修改
7)开启一个试验分支(experimental),如果分支开发成功则合并到主分支(master),否则放弃该试验分支。
- git branch experimental //创建一个试验分支,名称叫experimental
- git branch //显示当前都有哪些分支,其中标注*为当前所在分支
- git checkout experimental //转移到experimental分支
(省略数小时在此分支上的开发过程)…如果分支开发成功:
- git commit -a //在experimental分支改进完代码之后用commit在此分支中进行提交
- git checkout master //转移回master分支
- git merge experimental //经证实分支开发成功,将exerimental分支合并到主分支
- git commit -a //彻底完成此次分支合并,即提交master分支
- git branch -d experimental //因为experimental分支已提交,所以可安全删除此分支
如果分支开发失败:
- git checkout master
- git branch -D experimental //由于分支被证明失败,因此使用-D来放弃并删除该分支
8)随时查看图形化分支信息。
- gitk
9)当合作伙伴bob希望改进我(rocrocket)的工作成果,则:
- bob$git clone /home/rocrocket/project myrepo //此命令用于克隆我的工作到bob的myrepo目录下。请注意,此命令有可能会因为/home/rocrocket的目录权限问题而被拒绝,解决方法是chmod o+rx /home/rocrocket。
(省略bob数小时的开发过程)…
- bob$git commit -a //bob提交自己的改进成果到自己的git仓库中,并口头告知我(rocrocket)他已经完成了工作。
我如果非常非常信任bob的开发能力:
- cd /home/rocrocket/project
- git pull /home/bob/myrepo //pull命令的意思是从远端git仓库中取出(git-fetch)修改的代码,然后合并(git-merge)到我(rocrocket)的项目中去。读者要记住一个小技巧,那就是“git pull .”命令,它和git merge的功能是一样的,以后完全可以用git pull .来代替git merge哦!请注意,git-pull命令有可能会因为/home/bob的目录权限问题而被拒绝,解决方法是chmod o+rx /home/bob。
如果我不是很信任bob的开发能力:
- cd /home/rocrocket/project
- git fetch /home/bob/myrepo master:bobworks //此命令意思是提取出bob修改的代码内容,然后放到我(rocrocket)工作目录下的bobworks分支中。之所以要放到分支中,而不是master中,就是要我先仔仔细细看看bob的开发成果,如果我觉得满意,我再merge到master中,如果不满意,我完全可以直接git branch -D掉。
- git whatchanged -p master..bobworks //用来查看bob都做了什么
- git checkout master //切换到master分区
- git pull . bobworks //如果我检查了bob的工作后很满意,就可以用pull来将bobworks分支合并到我的项目中了
- git branch -D bobworks //如果我检查了bob的工作后很不满意,就可以用-D来放弃这个分支就可以了
过了几天,bob如果想继续帮助我开发,他需要先同步一下我这几天的工作成果,只要在其当初clone的myrepo目录下执行git pull即可:
- git pull //不用加任何参数,因为当初clone的时候,git已经记住了我(rocrocket)的工作目录,它会直接找到我的目录来取。
数据结构
GIT 核心数据结构有五个: object, blob, tree, commit, cache_entry。其中
- object: 基类。
- blob: 对应于一个文件。
- tree: 对应于一个目录。 一个 tree 包含一个或多个 blob 和 tree。
- commit: 对应于一个版本。 一个 commit 对象指向一个 tree 对象,该 tree 对象对应于该版本的根目录。 一个 commit 对象指向一个父 commit 对象, 表示它是该父commit 的下一个版本,或指向多个父 commit 对象,表示它由这些父 commit 合并得到。
Example
执行下面代码来创建一个测试目录
然后键入 `git log‘ 得到
commit字符串后面的一大长串(共40位)十六进制数字是干什么用的?
这40位十六进制数是用来“标识一次commit”的名称。其实,这40位十六进制数是一个SHA1哈希数(Secure Hash Algorithm),它可以保证每次commit生成的名称都是唯一的且可以永远有效的。
- $git cat-file -t 241e //cat-file命令中-t选项表示列出相应ID的对象类型;241e是刚才commit后得出的SHA1码
commit //可以看到此ID对应的对象类型为一次commit
然后介入 cat-file 命令
$git cat-file commit 241e //此处的commit表示要查询的是一个对象类型为commit的对象,后面给出此对象的IDtree 9a327d5e3aa818b98ddaa7b5b369f5deb47dc9f6 author rocrocket <[email protected]> 1222397833 +0800 committer rocrocket <[email protected]> 1222397833 +0800
- $ git ls-tree 9a327
100644 blob 7d4e0fa616551318405e8309817bcfecb7224cff file.txt
我们可以看到9a327这棵树上包括了一个file.txt文件,其ID为7d4e0f
- $ git cat-file -t 7d4e0f
blob
- $ git cat-file blob 7d4e0f
Hi,rocrocket
可以看到7d4e0f对应的对象的类型是blob,而其内容就是“Hi,rocrocket”
object
blob
tree
commit
cache_entry
重要函数
由于index cache对理解git工作原理起到至关重要的作用,这里主要分析与之相关的一些函数
cache中的全局变量
void * read_sha1_file(const unsigned char *sha1, char *type, unsigned long *size)
int write_sha1_file(char *buf, unsigned len, unsigned char *returnsha1)
int add_cache_entry(struct cache_entry *ce, int ok_to_add)
工作流程
1) working directory -> index
You update the index with information from the working directory withthe gitlink:git-update-index command. Yougenerally update the index information by just specifying the filenameyou want to update, like so:
2) index -> object database
You write your current index file to a "tree" object with the program
that doesn‘t come with any options - it will just write out thecurrent index into the set of tree objects that describe that state,and it will return the name of the resulting top-level tree. You canuse that tree to re-generate the index at any time by going in theother direction
3) object database -> index
You read a "tree" file from the object database, and use that topopulate (and overwrite - don‘t do this if your index contains anyunsaved state that you might want to restore later!) your currentindex. Normal operation is just
and your index file will now be equivalent to the tree that you savedearlier. However, that is only your ‘index‘ file: your workingdirectory contents have not been modified.
4) index -> working directory
You update your working directory from the index by "checking out"files. This is not a very common operation, since normally you‘d justkeep your files updated, and rather than write to your workingdirectory, you‘d tell the index files about the changes in yourworking directory (i.e. `git-update-index`).
However, if you decide to jump to a new version, or check out somebodyelse‘s version, or just restore a previous tree, you‘d populate yourindex file with read-tree, and then you need to check out the resultwith
or, if you want to check out all of the index, use `-a`.
5) Tying it all together
To commit a tree you have instantiated with "git-write-tree", you‘dcreate a "commit" object that refers to that tree and the historybehind it - most notably the "parent" commits that preceded it inhistory.
You create a commit object by giving it the tree that describes thestate at the time of the commit, and a list of parents:
6) Examining the data
You can examine the data represented in the object database and theindex with various helper tools. For every object, you can usegitlink:git-cat-file[1] to examine details about theobject:
shows the type of the object, and once you have the type (which isusually implicit in where you find the object), you can use
7) Merging multiple trees
To get the "base" for the merge, you first look up the common parentof two commits with
which will return you the commit they are both based on.To do the merge, do
which will do all trivial merge operations for you directly in theindex file, and you can just write the result out with