如何解释语音识别的技术原理?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何解释语音识别的技术原理?相关的知识,希望对你有一定的参考价值。
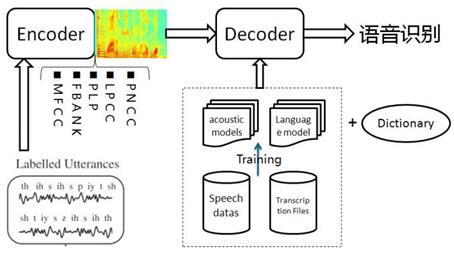
语音识别,是人工智能的重要入口,越来越火。从京东科大讯飞合作的叮咚,亚马逊的明星产品Echo,到最近一个月谷歌Master和百度小度掀起的人机大战,赚够了眼球。但语音只是个入口,内容或者说引导用户做决策乃至消费,才是王道。.语音识别系统,分训练和解码两阶段。训练,即通过大量标注的语音数据训练声学模型,包括GMM-HMM、DNN-HMM和RNN+CTC等;解码,即通过声学模型和语言模型将训练集外的语音数据识别成文字。目前常用的开源工具有HTK Speech Recognition Toolkit,Kaldi ASR以及基于Tensorflow(speech-to-text-wavenet)实现端到端系统。我以古老而又经典的HTK为例,来阐述语音识别领域涉及到的概念及其原理。HTK提供了丰富的语音数据处理,以及训练和解码的工具。语音识别,分为孤立词和连续词语音识别系统。早期,1952年贝尔实验室和1962年IBM实现的都是孤立词(特定人的数字及个别英文单词)识别系统。连续词识别,因为不同人在不同的场景下会有不同的语气和停顿,很难确定词边界,切分的帧数也未必相同;而且识别结果,需要语言模型来进行打分后处理,得到合乎逻辑的结果。
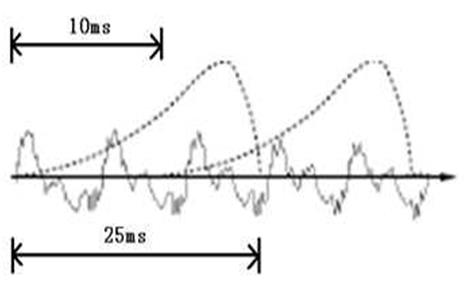
首先,我们知道声音实际上是一种波。常见的mp3等格式都是压缩格式,必须转成非压缩的纯波形首先,我们知道声音实际上是一种波。常见的mp3等格式都是压缩格式,必须转成非压缩的纯波形头以外,就是声音波形的一个个点了。在开始语音识别之前,有时需要把首尾端的静音切除,降低对后续步骤造成的干扰。这个静音切除的操作一般称为VAD,需要用到信号处理的一些技术。要对声音进行分析,需要对声音分帧,也就是把声音切开成一小段一小段,每小段称为一帧。分帧操作一般不是简单的切开,而是使用移动窗函数来实现,这里不详述。帧与帧之间一般是有交叠的,图中,每帧的长度为25毫秒,每两帧之间有25-10=15毫秒的交叠。我们称为以帧长25ms、帧移10ms分帧。分帧后,语音就变成了很多小段。但波形在时域上几乎没有描述能力,因此必须将波形作变换。常见的一种变换方法是提取MFCC特征,根据人耳的生理特性,把每一帧波形变成一个多维向量,可以简单地理解为这个向量包含了这帧语音的内容信息。这个过程叫做声学特征提取。实际应用中,这一步有很多细节,声学特征也不止有MFCC这一种,具体这里不讲。至此,声音就成了一个12行(假设声学特征是12维)、N列的一个矩阵,称之为观察序列,这里N为总帧数。观察序列如下图所示,图中,每一帧都用一个12维的向量表示,色块的颜色深浅表示向量值的大小。
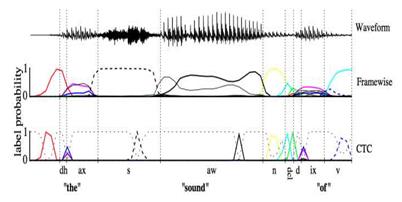
语音识别的第一个特点是要识别的语音的内容(比声韵母等)是不定长时序,也就是说,在识别以前你不可能知道当前的声韵母有多长,这样在构建统计模型输入语音特征的时候无法简单判定到底该输入0.0到0.5秒还是0.2到0.8秒进行识别,同时多数常见的模型都不方便处理维度不确定的输入特征(注意在一次处理的时候,时间长度转化成了当前的特征维度)。一种简单的解决思路是对语音进行分帧,每一帧占有比较短固定的时长(比如25ms),再假设说这样的一帧既足够长(可以蕴含足以判断它属于哪个声韵母的信息),又很平稳(方便进行短时傅里叶分析),这样将每一帧转换为一个特征向量,(依次)分别识别它们属于哪个声韵母,就可以解决问题。识别的结果可以是比如第100到第105帧是声母c,而第106帧到115帧是韵母eng等。这种思路有点类似微积分中的『以直代曲』。另外在实际的分帧过程中,还有很多常用技巧,比如相邻两帧之间有所重叠,或引入与临近帧之间的差分作为额外特征,乃至直接堆叠许多语音帧等等,这些都可以让前述的两个假设更可靠。近年来,研究种也出现了一些更新颖的处理方式,比如用.wav文件的采样点取代分帧并处理后的语音帧,但这样的方法在处理速度及性能上暂时还没有优势。
以上是关于如何解释语音识别的技术原理?的主要内容,如果未能解决你的问题,请参考以下文章