Attention is all you need 论文详解(转)
Posted gczr
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Attention is all you need 论文详解(转)相关的知识,希望对你有一定的参考价值。
一、背景
自从Attention机制在提出之后,加入Attention的Seq2Seq模型在各个任务上都有了提升,所以现在的seq2seq模型指的都是结合rnn和attention的模型。传统的基于RNN的Seq2Seq模型难以处理长序列的句子,无法实现并行,并且面临对齐的问题。
所以之后这类模型的发展大多数从三个方面入手:
-
input的方向性:单向 -> 双向
-
深度:单层 -> 多层
-
类型:RNN -> LSTM GRU
但是依旧收到一些潜在问题的制约,神经网络需要能够将源语句的所有必要信息压缩成固定长度的向量。这可能使得神经网络难以应付长时间的句子,特别是那些比训练语料库中的句子更长的句子;每个时间步的输出需要依赖于前面时间步的输出,这使得模型没有办法并行,效率低;仍然面临对齐问题。
再然后CNN由计算机视觉也被引入到deep NLP中,CNN不能直接用于处理变长的序列样本但可以实现并行计算。完全基于CNN的Seq2Seq模型虽然可以并行实现,但非常占内存,很多的trick,大数据量上参数调整并不容易。
本篇文章创新点在于抛弃了之前传统的encoder-decoder模型必须结合cnn或者rnn的固有模式,只用Attention。文章的主要目的在于减少计算量和提高并行效率的同时不损害最终的实验结果。
二、整体框架
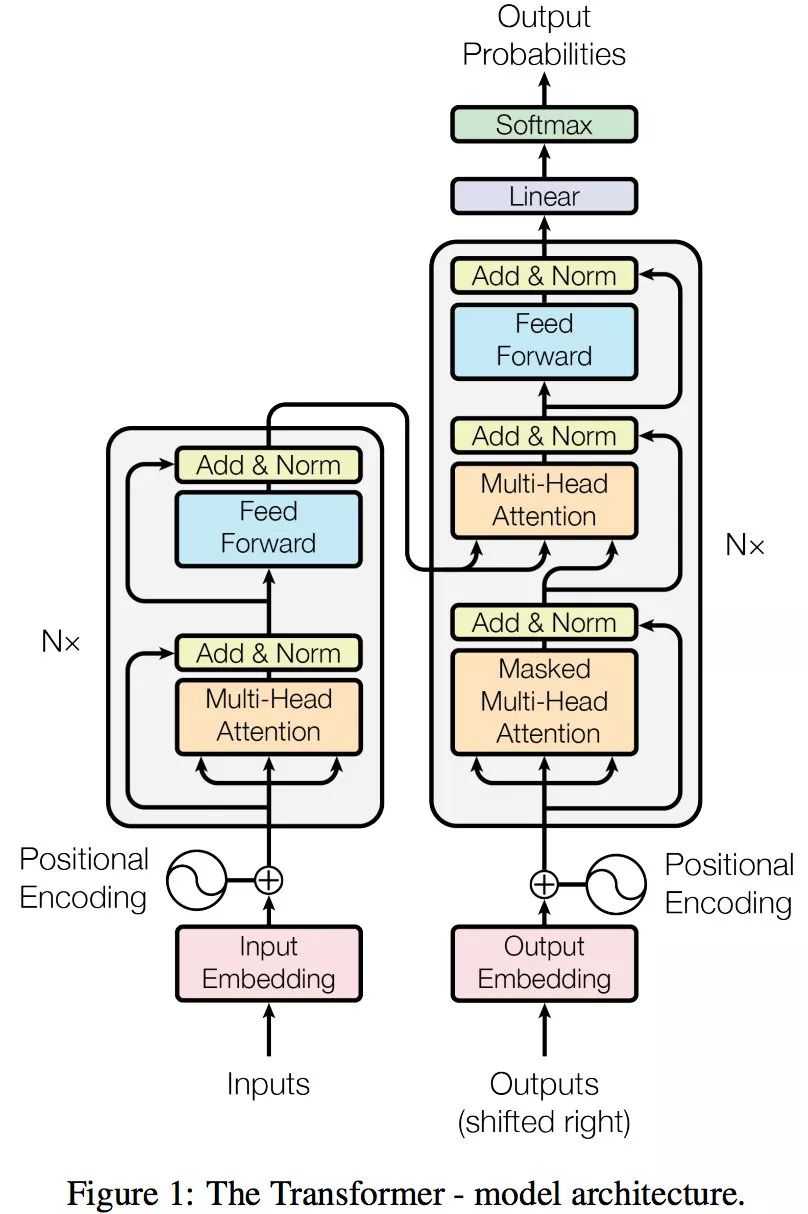
整体模型看上去看上去很复杂,其实这就是一个Seq2Seq模型,左边一个encoder把输入读进去,右边一个decoder得到输出:
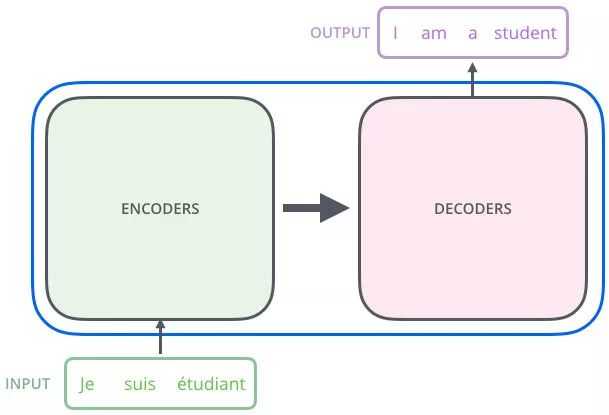
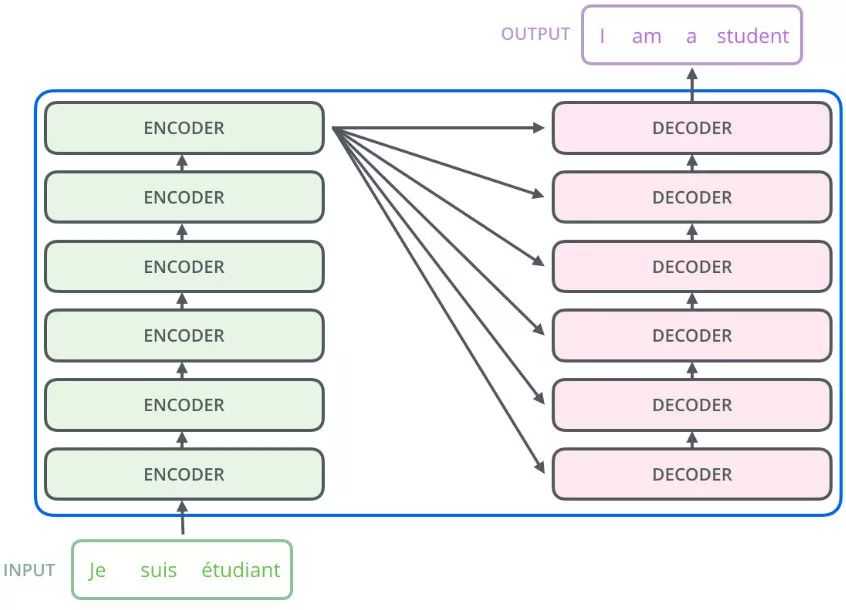
左边的encoders和右边的decoders都是由6层组成,内部左边encoder的输出是怎么和右边decoder结合的呢?再画张图直观的看就是这样:
三、分别展开
从上面可知,Encoder的输出,会和每一层的Decoder进行结合。我们取其中一层进行详细的展示:
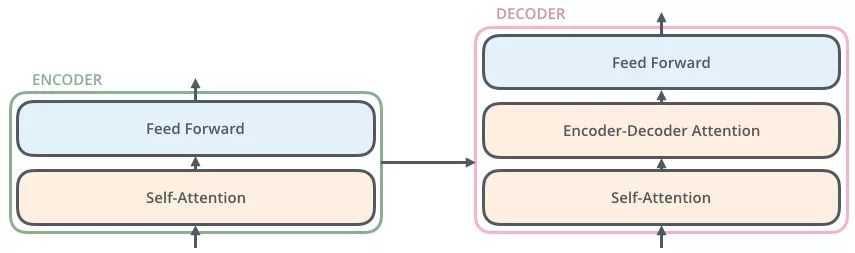
整体框架细节展示:
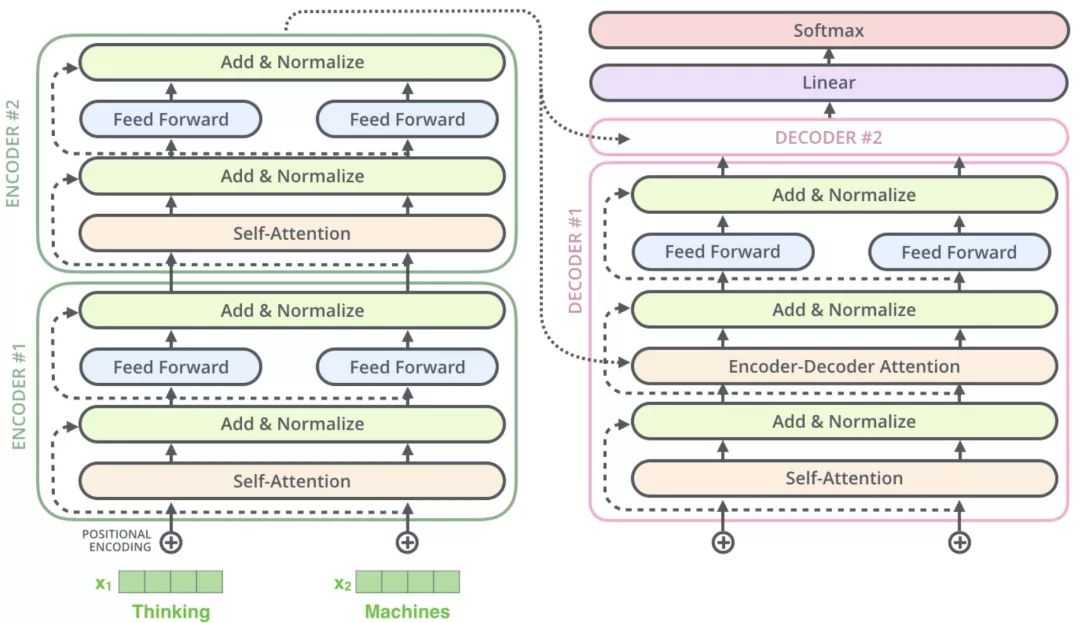
1)Encoder
Encoder有N=6层,每层包括两个sub-layers:
-
第一个sub-layer是multi-head self-attention mechanism,用来计算输入的self-attention
-
第二个sub-layer是简单的全连接网络。
-
在每个sub-layer我们都模拟了残差网络,每个sub-layer的输出都是:
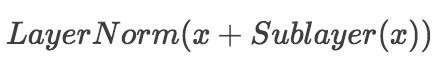
其中Sublayer(x) 表示Sub-layer对输入 x 做的映射,为了确保连接,所有的sub-layers和embedding layer输出的维数都相同 。
。
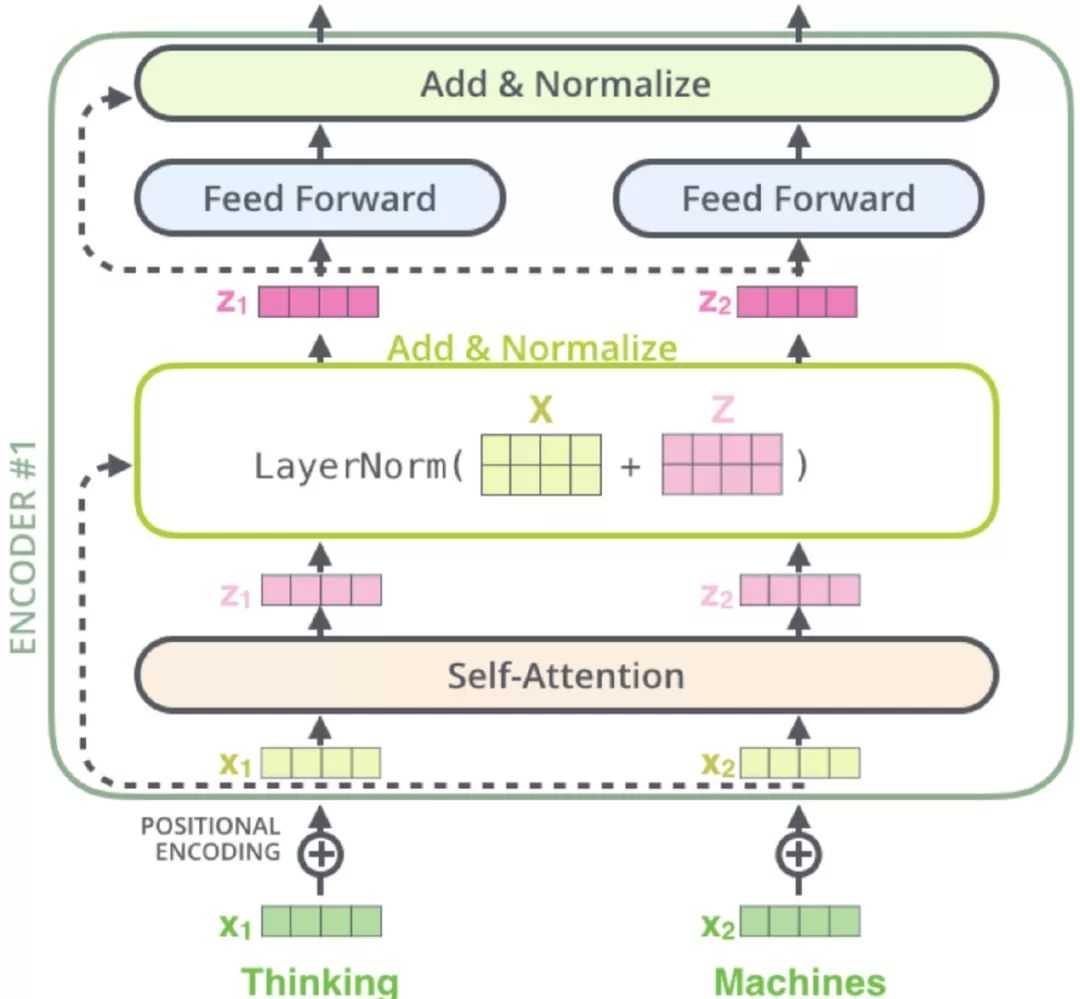
2)Decoder
Decoder也是N=6层,每层包括3个sub-layers:
第一个是Masked multi-head self-attention,也是计算输入的self-attention,但是因为是生成过程,因此在时刻 i 的时候,大于 i 的时刻都没有结果,只有小于 i 的时刻有结果,因此需要做Mask
第二个sub-layer是全连接网络,与Encoder相同
第三个sub-layer是对encoder的输入进行attention计算。
同时Decoder中的self-attention层需要进行修改,因为只能获取到当前时刻之前的输入,因此只对时刻 t 之前的时刻输入进行attention计算,这也称为Mask操作。
图示参考上述总体框架细节图
以上是关于Attention is all you need 论文详解(转)的主要内容,如果未能解决你的问题,请参考以下文章