Kaggle: Google Analytics Customer Revenue Prediction EDA
Posted simon95
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kaggle: Google Analytics Customer Revenue Prediction EDA相关的知识,希望对你有一定的参考价值。
前言
内容提要
- 本文为Kaggle竞赛 Google Analytics Customer Revenue Prediction 的探索性分析
- 题目要求根据历史顾客访问GStore的数据,预测其中部分顾客在未来的销售额,且预测期与原数据之间不连续
- 主要切入角度为针对待预测的问题,估计出答案的合理区间(数量级水平)
项目介绍
- 项目说明:Google Analytics Customer Revenue Prediction
- 预测目标(新):根据顾客的点击信息数据(2016.8.1 - 2018.10.15),预测2018.5.1 - 2018.10.31期间浏览过GStore的顾客,在2018.12.1 - 2019.1.31的消费金额(Revenue)。11月31日截止提交。
- 预测目标(原):根据浏览数据预测单次消费金额的常规问题,后来经过修改,题目变得极难预测,有相当比例的参赛者提交了全0的预测。
- 数据字段:共13个列,其中fullVisitorId为顾客的唯一标识,totals中包含一些重要的汇总信息,4列为标准的JSON格式,两列为不标准的JSON,处理难度较大。原始列名如下:
‘channelGrouping‘, ‘customDimensions‘, ‘date‘, ‘device‘, ‘fullVisitorId‘, ‘geoNetwork‘, ‘hits‘, ‘socialEngagementType‘, ‘totals‘, ‘trafficSource‘, ‘visitId‘, ‘visitNumber‘, ‘visitStartTime‘
- 数据规模:train_v2.csv, 1708345条数据, 23.6GB;test_v2.csv, 401589条数据, 7.09GB。
- 评估指标:RMSE
分析工具
- Python 3.6.5 |Anaconda, Inc.| ,主要使用Spyder作为IDE
- 电脑配置:i7- 6600U, 16GB RAM,低于此配置可能无法处理这个数据集
比赛总体思路
- 每个用户的消费总金额可以分解为客户单次消费的平均金额和预期消费次数
- 单次平均金额可以根据历史数据取平均,但只针对曾经购买的客户,无法预测新增客户
- 所以我们需要知道每个月新增购买/重复购买客户的分布,新增客户在前购买前若干月份的浏览情况,从而推算用户构成(新访新消 / 老访新消 / 老顾客)
- 对曾经购买过的客户,对其每次浏览,计算下次购买时间,标记其购买类型
- 以此为参照建立模型,尝试预测重复购买和新增购买
分析思路和历程
- 首先用pandas读取CSV,观察数据,尝试解析JSON列
- 运行多个小时之后,发现数据量太大,内存占用长期接近100%,决定拆分数据集(20000条一组)
- 分别解析JSON,通过json_normalize方法解析json列,非标准json格式需要先去掉最外层中括号(literal_eval)
- 合并数据集,检查总行数
- 缺失值分析和数据预处理
- 创建组合特征,计算出下次购买时间,区分新增购买和重复购买
- 数据透视和描述统计,按年月汇总,估计答案大致范围
- 尝试建模求解
说明
- 本文的分析主要集中于用户的浏览和购买行为,不包含很多分类特征和模型,目前参赛者还没有从这个角度分析的kernel(现有EDA主要是分类特征的可视化)
- 目前比赛已经结束,2019年2月公布比赛结果
- 本文内容较多,为了阅读体验,较长的代码均被折叠
正文
整理数据


import os import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import json from pandas.io.json import json_normalize from datetime import datetime from ast import literal_eval import warnings warnings.filterwarnings(‘ignore‘) data_path = ‘C:\\Project\\Kaggle\\Revenue_Prediction\\data\\‘
def read_df(path, file_name, nrows = None): os.chdir(path) df = pd.read_csv(file_name, dtype = {‘fullVisitorId‘: ‘str‘, ‘visitId‘: ‘str‘}, chunksize = 10000) return df train_head = read_df(data_path, ‘train_v2.csv‘, nrows = 10000)

可以看出数据的结构较为复杂,对于JSON列和类JSON列,需要经过处理,才能进行有效使用。在处理的过程中, 我也参考了其他参赛者分享的一些Kernels,再通过拆分计算的思想,完成了数据的解析。
def split_df(df, path, num_split): os.chdir(path) for i in range(num_split): temp = df[i*20000 : (i+1)*20000] temp.to_csv(str(i) + ‘.csv‘, index = False) print(‘No. %s is done.‘ %i) def load_df(csv_name, nrows = None): "csv_path:文件路径, nrows 读取行数,JSON_COLUMNS: JSON的列" df = pd.read_csv(csv_name, converters = {column: json.loads for column in JSON_COLUMNS}, # json.loads : json --> python dtype = {‘fullVisitorId‘: ‘str‘, ‘visitId‘: ‘str‘}, nrows = nrows) for col in NEW_COLUMNS: df[col][df[col] == "[]"] = "[{}]" df[col] = df[col].apply(literal_eval).str[0] for column in JSON_COLUMNS + NEW_COLUMNS: column_as_df = json_normalize(df[column]) # json column --> tabel(DataFrame) column_as_df.columns = [f"{column}.{subcolumn}" for subcolumn in column_as_df.columns] # f-string in Python 3.6 # Extract the product and promo names from the complex nested structure into a simple flat list: if ‘hits.product‘ in column_as_df.columns: column_as_df[‘hits.v2ProductName‘] = column_as_df[‘hits.product‘].apply(lambda x: [p[‘v2ProductName‘] for p in x] if type(x) == list else []) column_as_df[‘hits.v2ProductCategory‘] = column_as_df[‘hits.product‘].apply(lambda x: [p[‘v2ProductCategory‘] for p in x] if type(x) == list else []) del column_as_df[‘hits.product‘] if ‘hits.promotion‘ in column_as_df.columns: column_as_df[‘hits.promoId‘] = column_as_df[‘hits.promotion‘].apply(lambda x: [p[‘promoId‘] for p in x] if type(x) == list else []) column_as_df[‘hits.promoName‘] = column_as_df[‘hits.promotion‘].apply(lambda x: [p[‘promoName‘] for p in x] if type(x) == list else []) del column_as_df[‘hits.promotion‘] df = df.drop(column, axis = 1).merge(column_as_df, left_index = True, right_index = True) df.to_csv(‘exjson_‘ + csv_name.split(‘.‘)[0] + ‘.csv‘, index = False) return df def exjson(path, num): os.chdir(path) files = [str(d) + ‘.csv‘ for d in range(num)] for i in files: load_df(i) print(‘No. {} is done.‘.format(i.split(‘.‘)[0])) def concat_df(path, num, outname): "path: path_train/path_test; num: 86/21" os.chdir(path) file_list = [‘exjson_{}.csv‘.format(i) for i in range(num)] df_list = [] for file in file_list: dfname = file.split(‘.‘)[0] dfname = pd.read_csv(file, dtype = {‘fullVisitorId‘: ‘str‘, ‘visitId‘: ‘str‘}) df_list.append(dfname) df = pd.concat(df_list, ignore_index = True) df.to_csv(outname, index = False) return df def bug_fix(df): drop_list = df[df[‘date‘] == "No"].index.tolist() df = df.drop(drop_list) print(df) return df
由于比较担心计算能力,拆分、解析、组合的过程被分别执行,且存储了过程结果,三者的主要函数见上面折叠的代码。
此后又对数据做出了一些简单处理,分离了年月日的信息,将totals.transactionRevenue取了对数(np.log1p),去掉了缺失值过多和数值单一的列,下面将主要对浏览、购买次数和时间进行分析。
构造特征
选取特征
- fullVisitorId: 顾客的唯一标识
- visitStartTime: 顾客本次浏览的开始时间,以秒为计算单位,从1970-1-1 0时开始
- visitNumber: 系统对于浏览次数的计数,第几次浏览
- totals.transactionRevenue: 当前浏览带来的销售额
- totals.hits: 当前浏览的点击次数
- totals.pageviews: 当前浏览的页面总数
- totals.timeOnSite: 当前浏览的总时间 / 秒
- totals.newVisits: 当前浏览是否为新增浏览
- date: 浏览日期
all_precleaning = read_df(path_data, ‘all_data_precleaning.csv‘) all_eda = all_precleaning[[‘fullVisitorId‘, ‘visitStartTime‘, ‘visitNumber‘, ‘totals.transactionRevenue‘, ‘totals.hits‘, ‘totals.pageviews‘, ‘totals.timeOnSite‘, ‘totals.newVisits‘, ‘date‘]]
all_precleaning 总共有70列,为了突出重点展示,本文只对以上特征进行分析。
年月合并
提取年和月作为一列,方便后续分组。
all_eda[‘yearMonth‘] = all_eda.apply(lambda x: x[‘date‘].split(‘-‘)[0] + x[‘date‘].split(‘-‘)[1], axis = 1)

针对用户的特征构建
- sumRevenue: 用户累计购买总额
- everBuy: 用户是否有过购买 1 / 0
- buy: 用户当前次浏览,是否购买 1 / 0
- viewTimes: 用户浏览总次数
- buyTimes: 用户购买总次数
- averageRevenue: 用户平均销售额(仅对实际购买次数取平均)
- nextBuyTime: 下次购买时间(分析难点,需要构造辅助列buyNumber, nextBuyGroup)
- timeToBuy: 与下次购买的时间间隔
- timeToBuy.day: 与下次购买的时间间隔,换算到天
- lastVisitTime: 用户最后一次浏览时间,用于查找需要预测的全部数据条数
- revNum: 第几次购买(分析难点,需要辅助列buyNumber)
- firstVisitTime: 首次浏览时间
- firstBuy: 是否为首次购买 1 / 0
- reBuy: 是否为复购 1 / 0
- sinceFirstVisit: 与第一次浏览的时间间隔 / 秒
- sinceFirstVisit.day: 与第一次浏览的时间间隔 / 天
- sinceFirstVisit.period: 与第一代浏览的时间间隔 / 时期 0-30-60-120-240-800
计算过程中,将仅浏览一次的数据单独计算; 其余数据根据 fullVisitorId 进行分组累计,每个分组内按照浏览时间由小到大排列,以便标记次数。
计算特征的代码较长,折叠于下方,结果为29列。
def add_groupby_col(df, new_column_names, by = ‘fullVisitorId‘, agg_cols = [‘totals.transactionRevenue‘], aggfunc =[‘count‘]): "new_column_names: a list of col names" temp = df.groupby(by)[agg_cols].aggregate(aggfunc) temp.columns = new_column_names df = pd.merge(df, temp, left_on = ‘fullVisitorId‘, right_index = True, how = ‘left‘) return df def calculate_id_features(df): df = df.sort_values(by = ‘visitNumber‘) df[‘buy‘] = df.apply(lambda x: 1 if x[‘totals.transactionRevenue‘]>0 else 0, axis = 1) df[‘buyNumber‘] = df[‘buy‘].cumsum() df[‘nextBuyGroup‘] = df[‘buyNumber‘] - df[‘buy‘] next_buy_time = df.groupby(‘nextBuyGroup‘).agg({‘visitStartTime‘: ‘max‘}) next_buy_time.columns = [‘nextBuyTime‘] df = pd.merge(df, next_buy_time, left_on = ‘buyNumber‘, right_index = True, how = ‘left‘) df[‘sumRevenue‘] = df[‘totals.transactionRevenue‘].sum() df[‘everBuy‘] = df.apply(lambda x: 1 if x[‘sumRevenue‘]>0 else 0, axis = 1) df[‘buyTimes‘] = df[‘buy‘].sum() df[‘averageRevenue‘] = df.apply(lambda x: x[‘sumRevenue‘]/x[‘buyTimes‘] if x[‘buyTimes‘]>0 else 0, axis = 1) df[‘firstVisitTime‘] = df[‘visitStartTime‘].min() df[‘lastVisitTime‘] = df[‘visitStartTime‘].max() df[‘sinceFirstVisit‘] = df[‘visitStartTime‘] - df[‘firstVisitTime‘] df[‘sinceFirstVisit.day‘] = df[‘sinceFirstVisit‘] // (24*3600) df[‘sinceFirstVisit.period‘] = pd.cut(df[‘sinceFirstVisit.day‘], [-1, 30, 60, 120, 240, 800], labels = [‘within30‘, ‘30-60‘, ‘60-120‘, ‘120-240‘, ‘240-800‘]) def get_timegap(df_l): timegap = df_l[‘nextBuyTime‘] - df_l[‘visitStartTime‘] if timegap > 0: return timegap df[‘timeToBuy‘] = df.apply(lambda x: get_timegap(x), axis = 1) df[‘timeToBuy‘].fillna(0, inplace = True) df[‘timeToBuy.day‘] = df.apply(lambda x: x[‘timeToBuy‘]/(24*3600) if x[‘everBuy‘]==1 else -10, axis = 1) df[‘revNum‘] = df.apply(lambda x: x[‘buyNumber‘] if x[‘buy‘]==1 else 0, axis = 1) df[‘firstBuy‘] = df.apply(lambda x: 1 if x[‘revNum‘]==1 else 0, axis = 1) df[‘reBuy‘] = df.apply(lambda x: 1 if x[‘revNum‘]>1 else 0, axis = 1) return df def one_visit_features(df): df[‘buy‘] = df.apply(lambda x: 1 if x[‘totals.transactionRevenue‘]>0 else 0, axis = 1) df[‘sumRevenue‘] = df[‘totals.transactionRevenue‘].sum() df[‘everBuy‘] = df.apply(lambda x: 1 if x[‘sumRevenue‘]>0 else 0, axis = 1) #df[‘viewTimes‘] = df[‘visitStartTime‘].count() df[‘buyTimes‘] = df[‘buy‘].sum() df[‘averageRevenue‘] = df.apply(lambda x: x[‘sumRevenue‘]/x[‘buyTimes‘] if x[‘buyTimes‘]>0 else 0, axis = 1) df[‘firstVisitTime‘] = df[‘visitStartTime‘] df[‘lastVisitTime‘] = df[‘visitStartTime‘] df[‘revNum‘] = df.apply(lambda x: 1 if x[‘buy‘]==1 else 0, axis = 1) df[‘firstBuy‘] = df.apply(lambda x: 1 if x[‘buy‘]==1 else 0, axis = 1) df[‘reBuy‘] = 0 return df all_eda = add_groupby_col(all_eda, [‘viewTimes‘]) all_eda_oneview = all_eda[all_eda[‘viewTimes‘] == 1] all_eda_views = all_eda[all_eda[‘viewTimes‘] > 1] all_eda_oneview_cal = one_visit_features(all_eda_oneview) all_eda_views_cal = all_eda_views.groupby(‘fullVisitorId‘).apply(calculate_id_features) all_eda_cal = pd.concat([all_eda_views_cal, all_eda_oneview_cal], ignore_index = True) all_eda_cal.to_csv(‘all_eda_cal.csv‘, index = False)
总浏览次数&总购买次数分析
- 按次统计,划分区间
- 浏览次数为1次和2次居多、购买次数绝大多数都是0
数据计算
def view_range_agg(df): "df: all_eda_cal" view_times = df.groupby(‘fullVisitorId‘).agg({‘viewTimes‘: ‘max‘}) view_times_agg = view_times.groupby(‘viewTimes‘).agg({‘viewTimes‘: ‘count‘}) view_times_agg.columns = [‘num‘] view_times_agg.reset_index(inplace = True) view_times_agg[‘viewRange‘] = pd.cut(view_times_agg[‘viewTimes‘], [-1, 1, 2, 3, 6, 10, 20, 40, 80, 500], labels = [‘1‘, ‘2‘, ‘3‘, ‘4-6‘, ‘7-10‘, ‘11-20‘, ‘21-40‘, ‘41-80‘, ‘81-500‘]) result = view_times_agg.groupby(‘viewRange‘).agg({‘num‘: ‘sum‘}) return result def buy_range_agg(df): "df: all_eda_agg" buy_times = df.groupby(‘fullVisitorId‘).agg({‘buyTimes‘: ‘max‘}) buy_times_agg = buy_times.groupby(‘buyTimes‘).agg({‘buyTimes‘: ‘count‘}) buy_times_agg.columns = [‘num‘] buy_times_agg.reset_index(inplace = True) buy_times_agg[‘buyRange‘] = pd.cut(buy_times_agg[‘buyTimes‘], [-1, 0, 1, 2, 3, 6, 10, 33], labels = [‘0‘, ‘1‘, ‘2‘, ‘3‘, ‘4-6‘, ‘7-10‘, ‘11-33‘]) result = buy_times_agg.groupby(‘buyRange‘).agg({‘num‘: ‘sum‘}) return result view_range = view_range_agg(all_eda_cal) buy_range = buy_range_agg(all_eda_cal) print(‘浏览次数分布如下:‘) print(view_range) print(‘-‘ * 10) print(‘购买次数分布如下:‘) print(buy_range)
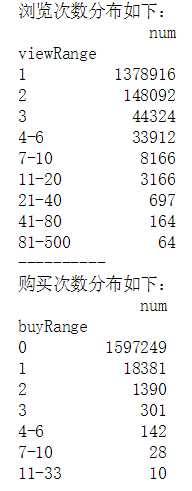
原始图表
包含所有取值可能,会导致部分数据无法获得直观展示
plt.rcParams[‘font.sans-serif‘]=[‘SimHei‘] fig,axes = plt.subplots(1,2,figsize = (20,6)) view_range.plot.barh(ax = axes[0]) axes[0].set_title(‘浏览次数分布‘) buy_range.plot.barh(ax = axes[1]) axes[1].set_title(‘购买次数分布‘)
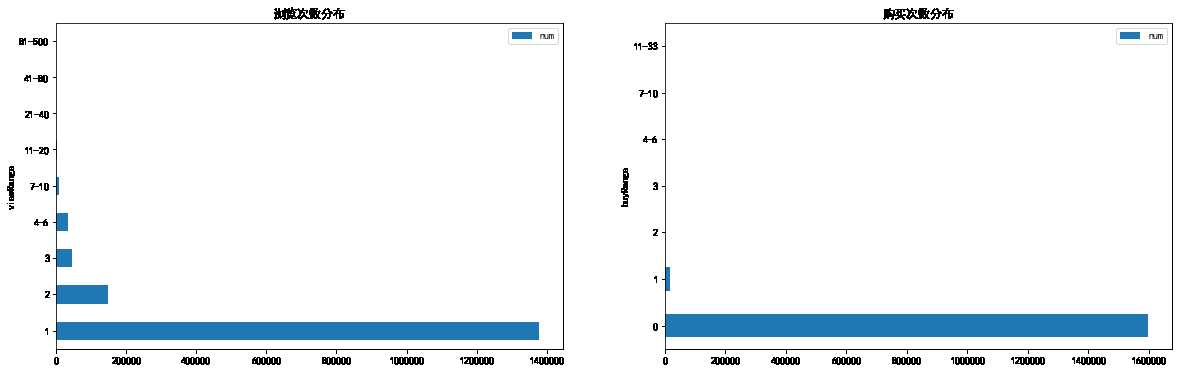
放大图表
- 除去浏览次数为0和1的图形
- 除去购买次数为0和1的图形
fig,axes = plt.subplots(1,2,figsize = (20,6)) view_range[2:].plot.barh(ax = axes[0]) axes[0].set_title(‘浏览次数分布‘) buy_range[2:].plot.barh(ax = axes[1]) axes[1].set_title(‘购买次数分布‘)
按照年月进行分组统计
- 指标包括: 浏览次数、购买次数、新增浏览、总销售额、新增购买次数、重复购买次数、新增购买收入、重复购买收入等
- 对数据中的每个月,绘制浏览次数、新增浏览、购买次数、新增购买、重复购买的对比折线图
- 数据中10月只有15天,所以数据量小属于正常现象
特征计算
def yearMonth_des(df): "df: all_eda_cal" # 总购买数 新增浏览 总销售额 yearmonth_1 = df.groupby(‘yearMonth‘).agg({‘buy‘: ‘sum‘, ‘totals.newVisits‘: ‘sum‘, ‘totals.transactionRevenue‘: ‘sum‘}) yearmonth_1.columns = [‘month_buyTimes‘, ‘month_newVisits‘, ‘month_totalRev‘] # 总浏览数 yearmonth_visit_time = df.groupby(‘yearMonth‘).apply(lambda x: len(x)).reset_index() yearmonth_visit_time.columns = [‘yearMonth‘, ‘month_visitTime‘] yearmonth_visit_time.index = yearmonth_visit_time[‘yearMonth‘] # 新增购买 / 重复购买 销售额 # 此时的重复购买指:不是第一次购买,有可能第一次购买就发生于当月 first_buy_rev = df[df[‘firstBuy‘]==1].groupby(‘yearMonth‘).agg({‘totals.transactionRevenue‘: ‘sum‘}) rebuy_rev = df[df[‘reBuy‘]==1].groupby(‘yearMonth‘).agg({‘totals.transactionRevenue‘: ‘sum‘}) first_buy_rev.columns = [‘firstBuyRev‘] rebuy_rev.columns = [‘reBuyRev‘] # 统计新增/重复购买人数 按年月分组 yearmonth_2 = df.groupby(‘yearMonth‘).agg({‘firstBuy‘: ‘sum‘, ‘reBuy‘: ‘sum‘}) # 将分散的groupby特征整合到一起 yearmonth_des = pd.concat([yearmonth_visit_time, yearmonth_1, yearmonth_2, first_buy_rev, rebuy_rev], axis = 1) # 计算首次购买和重复购买的金额均值 yearmonth_des[‘avgFirst‘] = yearmonth_des[‘firstBuyRev‘] / yearmonth_des[‘firstBuy‘] yearmonth_des[‘avgRev‘] = yearmonth_des[‘reBuyRev‘] / yearmonth_des[‘reBuy‘] #yearmonth_des.to_csv(‘yearmonth_group.csv‘, index = False) return yearmonth_des yearmonth_des = yearMonth_des(all_eda_cal) yearmonth_des.index = yearmonth_des.index.astype(str) yearmonth_des.tail(6)
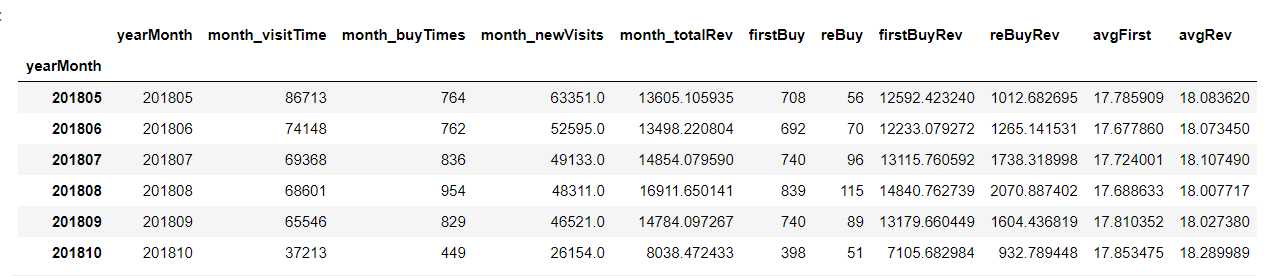
月浏览次数和购买次数折线图
fig, ax = plt.subplots(2, 1, figsize = (20, 16)) ax[0].plot(yearmonth_des[‘month_visitTime‘]) ax[0].plot(yearmonth_des[‘month_newVisits‘]) ax[0].plot(yearmonth_des[‘month_buyTimes‘]) ax[0].legend() ax[0].set_title(‘浏览次数 新增浏览 购买次数‘) ax[1].plot(yearmonth_des[‘month_buyTimes‘]) ax[1].plot(yearmonth_des[‘firstBuy‘]) ax[1].plot(yearmonth_des[‘reBuy‘]) ax[1].legend() ax[1].set_title(‘购买次数 首次购买 重复购买‘)
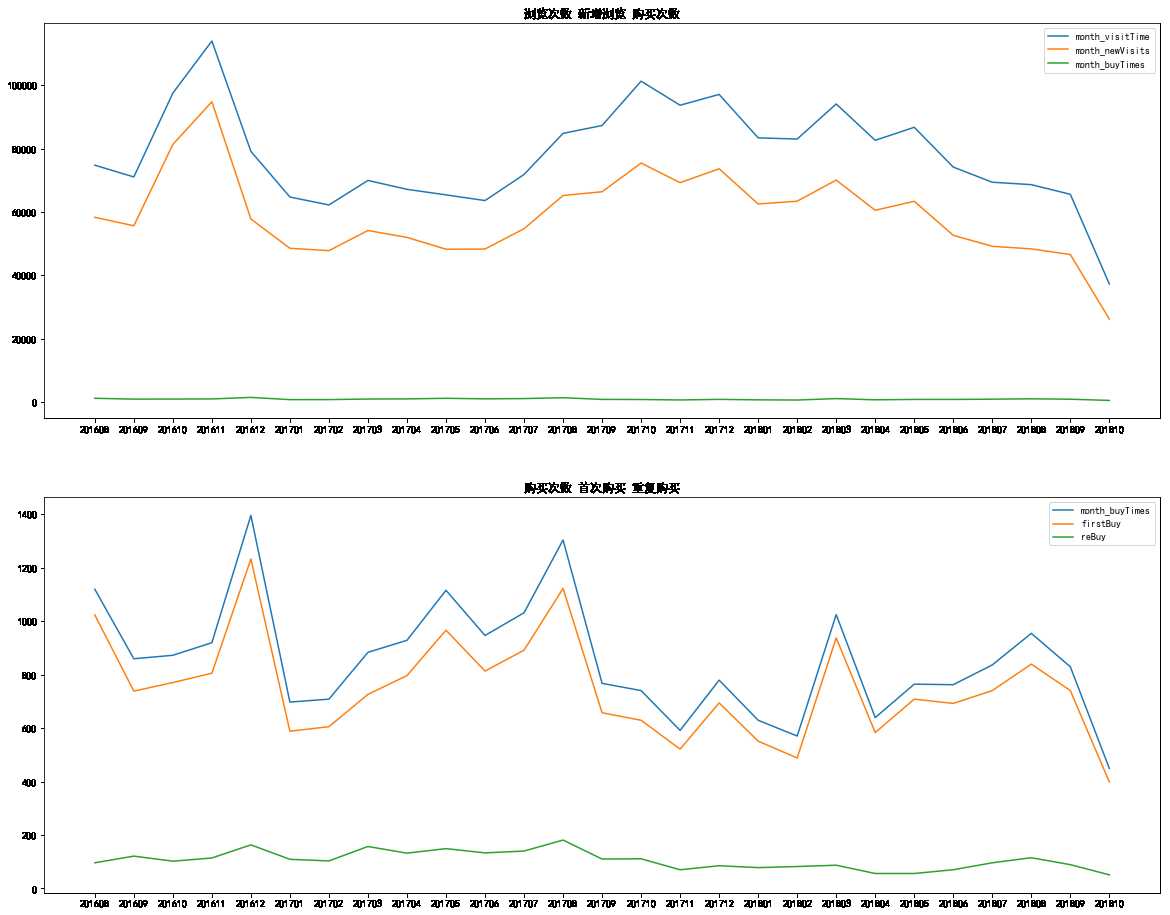
- 由上图可以观察到每个月浏览次数大约为8000次左右,波动性主要与新增浏览相关
- 月购买次数大约在1000次左右,很大比例都是新增购买,二者波动有很大的相关性
- 重复购买数量相对稳定,平均在100次左右
- 2018年5月左右,购买次数存在波谷,正好是训练集和测试集的连接处,可能竞赛数据并非全数据,待下一步分析
- 浏览和购买次数之间存在一定的相关性,但程度并不高
- 次数预测可以分解为新增购买和重复购买
每个月购买次数的数据透视
- 前面的分析将购买次数划分为了首次和重复,并且在总体上对购买次数进行了统计
- 此时可以进行按月统计,查看有无显著规律
yearmonth_buy_pivo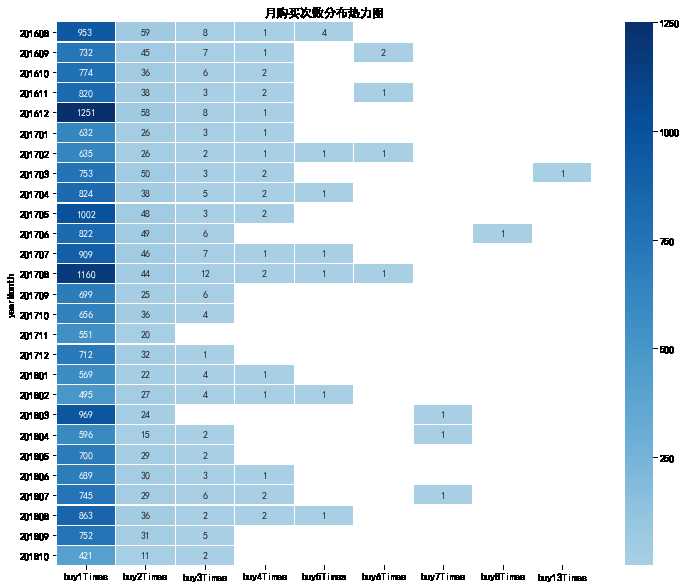
- 从图中可以观察到每个月购买三次以上的顾客十分少见
- 购买2-3次的顾客每月大约30人
- 此时还不能确定在一个月内大量购买的顾客的后续表现
首次购买时的浏览次数分布
## 表2 # 首次购买的用户需要的浏览次数 区间 all_eda_cal[‘visitNumRange‘] = pd.cut(all_eda_cal[‘visitNumber‘], [0, 1, 2, 5, 10, 20, 388], labels = [‘1‘, ‘2‘, ‘3-5‘, ‘6-10‘, ‘11-20‘, ‘21-388‘]) firstBuy_visitNum_pivot = all_eda_cal[all_eda_cal[‘firstBuy‘]==1].pivot_table(index = ‘yearMonth‘, columns = ‘visitNumRange‘, aggfunc = {‘visitNumRange‘: ‘count‘}) firstBuy_visitNum_pivot.tail(6) plt.figure(figsize = (12, 10)) #yearmonth_buy_pivot.fillna(0, inplace = True) sns.heatmap(firstBuy_visitNum_pivot, annot = True, # 是否显示数值 fmt = ‘.0f‘, # 格式化字符串 linewidths = 0.1, # 格子边线宽度 center = 300, # 调色盘的色彩中心值,若没有指定,则以cmap为主 cmap = ‘Blues‘, # 设置调色盘 cbar = True, # 是否显示图例色带 #cbar_kws={"orientation": "horizontal"}, # 是否横向显示图例色带 #square = True, # 是否正方形显示图表 ) plt.title(‘首次购买时的浏览次数分布‘)
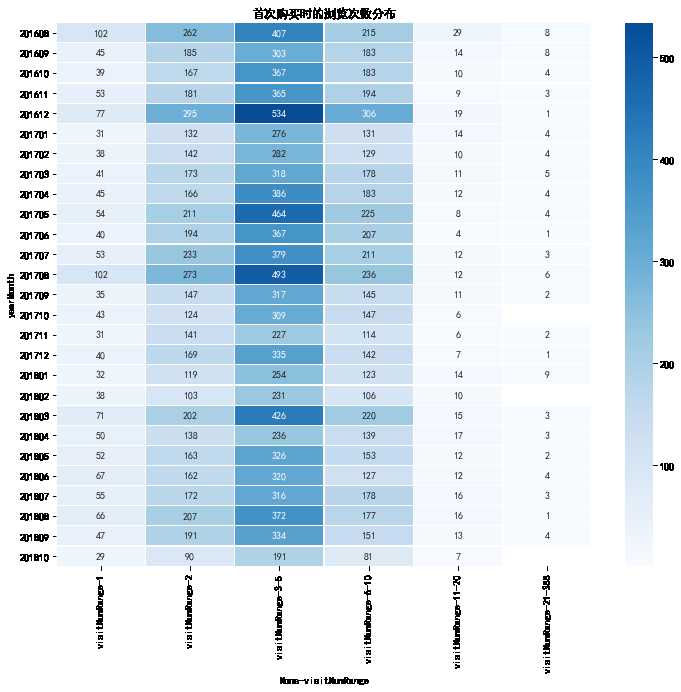
- 观察上图可知完成首次购买的时候,浏览次数主要集中于3-5次(2-10次)
- 但不能得知次数的时间跨度
购买与首次浏览的间隔分布
- 时间间隔被划分为区间进行统计
- 考虑到最后的预测目标,应主要关注60-240天的数据
## 表3表4 # 首次购买和重复购买与首次浏览时间间隔的分布 firstBuy_sinceFisrtVisit_pivot = all_eda_cal[all_eda_cal[‘firstBuy‘]==1].pivot_table(index = ‘yearMonth‘, columns = ‘sinceFirstVisit.period‘, aggfunc = {‘sinceFirstVisit.period‘: ‘count‘}) reBuy_sinceFisrtVisit_pivot = all_eda_cal[all_eda_cal[‘reBuy‘]==1].pivot_table(index = ‘yearMonth‘, columns = ‘sinceFirstVisit.period‘, aggfunc = {‘sinceFirstVisit.period‘: ‘count‘}) firstBuy_sinceFisrtVisit_pivot.columns = [[‘120-240‘, ‘240-800‘, ‘30-60‘, ‘60-120‘, ‘within30‘]] reBuy_sinceFisrtVisit_pivot.columns = [[‘120-240‘, ‘240-800‘, ‘30-60‘, ‘60-120‘, ‘within30‘]] firstBuy_sinceFisrtVisit_pivot = firstBuy_sinceFisrtVisit_pivot[[‘within30‘, ‘30-60‘, ‘60-120‘, ‘120-240‘, ‘240-800‘]] reBuy_sinceFisrtVisit_pivot = reBuy_sinceFisrtVisit_pivot[[‘within30‘, ‘30-60‘, ‘60-120‘, ‘120-240‘, ‘240-800‘]] firstBuy_sinceFisrtVisit_pivot.tail(6)
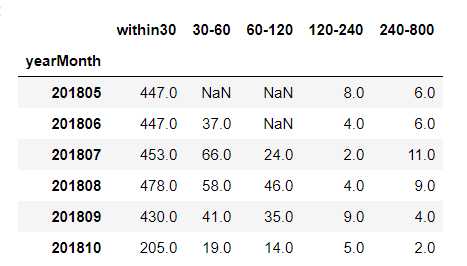
首次购买与首次浏览的时间间隔
plt.figure(figsize = (12, 10)) #yearmonth_buy_pivot.fillna(0, inplace = True) sns.heatmap(firstBuy_sinceFisrtVisit_pivot.drop(‘within30‘, axis = 1), annot = True, # 是否显示数值 fmt = ‘.0f‘, # 格式化字符串 linewidths = 0.1, # 格子边线宽度 center = 30, # 调色盘的色彩中心值,若没有指定,则以cmap为主 cmap = ‘Blues‘, # 设置调色盘 cbar = True, # 是否显示图例色带 #cbar_kws={"orientation": "horizontal"}, # 是否横向显示图例色带 #square = True, # 是否正方形显示图表 ) plt.title(‘首次购买与首次浏览的时间间隔‘)
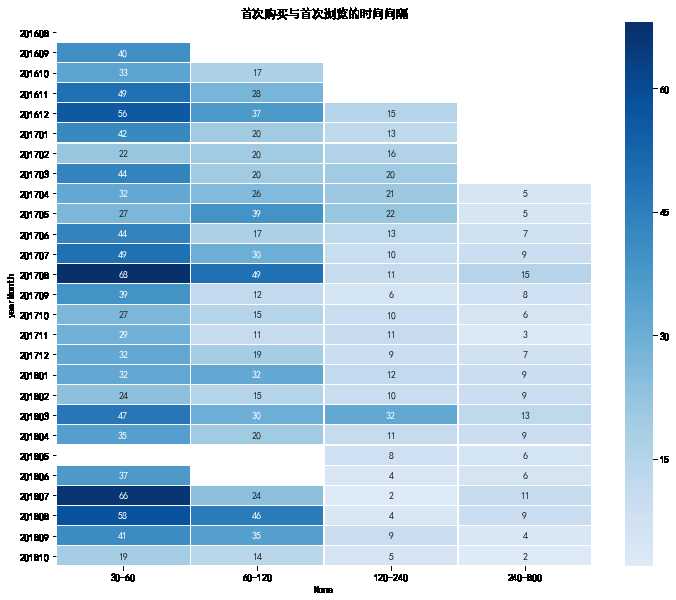
- 首次购买和首次浏览的间隔主要集中于30天之内,由于没有2018.10.16-2018.11.30日数据,无需关注
- 2018年5月处出先断层,属于严重的异常,可以得知竞赛数据并非GStore全部数据,训练集/测试集分别提取了一部分
- 间隔在60-240天之间每月大约30次左右(占比很低)
重复购买与首次浏览的时间间隔
plt.figure(figsize = (12, 10)) #yearmonth_buy_pivot.fillna(0, inplace = True) sns.heatmap(reBuy_sinceFisrtVisit_pivot, annot = True, # 是否显示数值 fmt = ‘.0f‘, # 格式化字符串 linewidths = 0.1, # 格子边线宽度 center = 35, # 调色盘的色彩中心值,若没有指定,则以cmap为主 cmap = ‘Blues‘, # 设置调色盘 cbar = True, # 是否显示图例色带 #cbar_kws={"orientation": "horizontal"}, # 是否横向显示图例色带 #square = True, # 是否正方形显示图表 ) plt.title(‘重复购买与首次浏览的时间间隔‘)
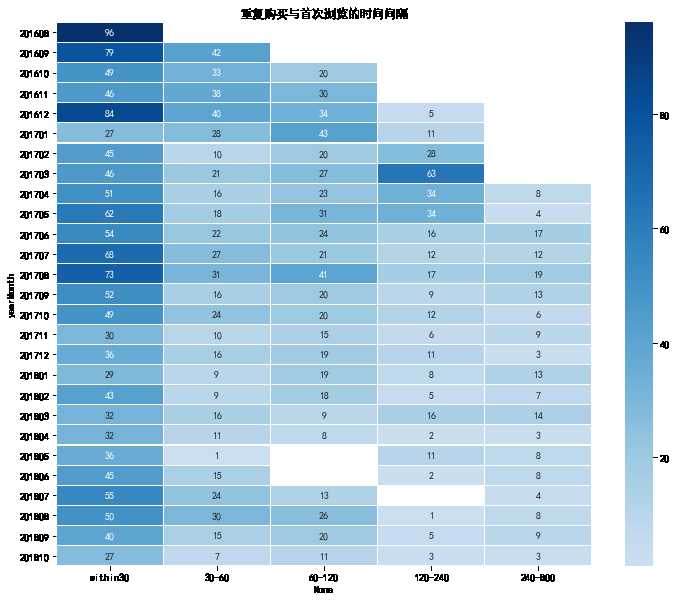
- 分析可知,预测期现有数据中重复购买的顾客数量大约在50-80
至此,我们已经对这个预测问题的基本情况有了一个初步的认识,这些数据可以为自己的交叉验证做出有效的补充。
以上是关于Kaggle: Google Analytics Customer Revenue Prediction EDA的主要内容,如果未能解决你的问题,请参考以下文章
javascript Javascript:Google Analytics Snipper + Google Analytics JS日志记录
如何从 Google-Analytics 迁移到 Firebase-Analytics?
html Google Analytics(分析) - 更多信息:https://developers.google.com/analytics/devguides/collection/analyt