[HBase] 服务端RPC机制及代码梳理
Posted ios123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[HBase] 服务端RPC机制及代码梳理相关的知识,希望对你有一定的参考价值。
基于版本:CDH5.4.2
上述版本较老,但是目前生产上是使用这个版本,所以以此为例。
1. 概要
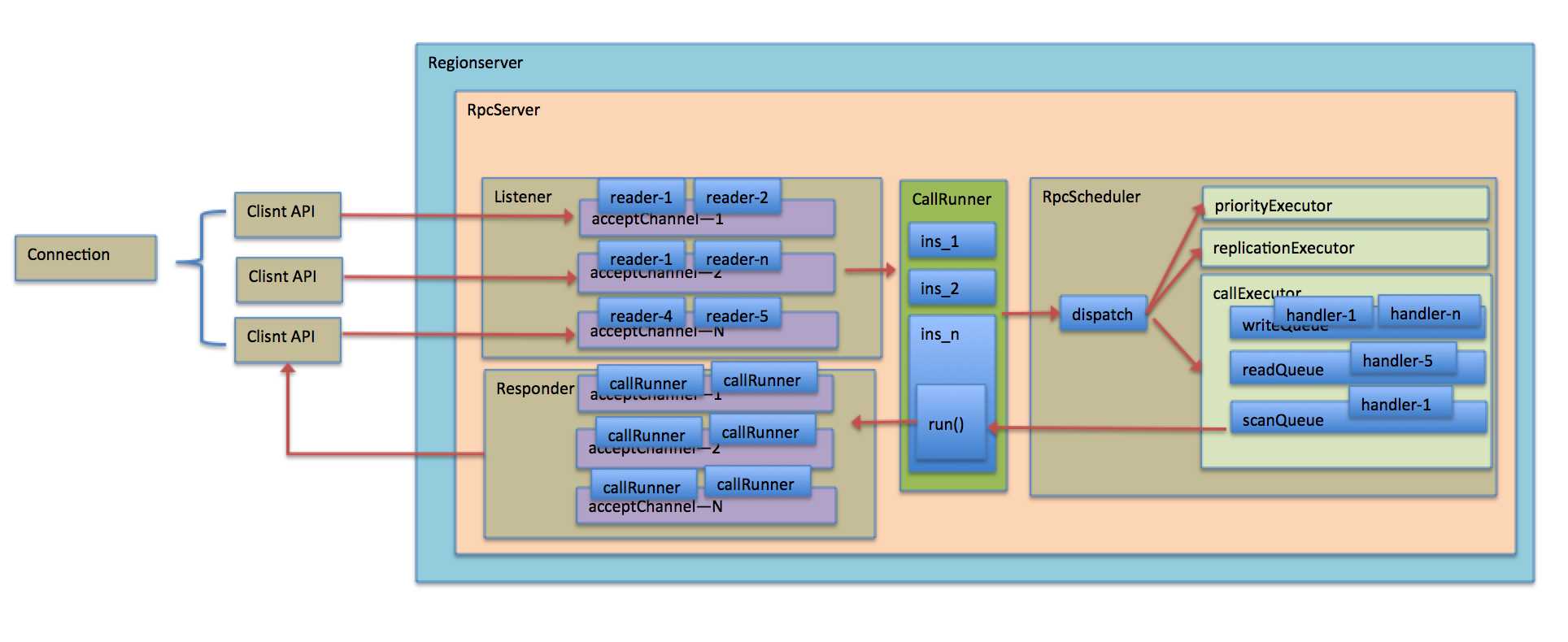
说明:
-
客户端API发送的请求将会被RPCServer的Listener线程监听到。
-
Listener线程将分配Reader给到此Channel用户后续请求的相应。
-
Reader线程将请求包装成CallRunner实例,并将通过RpcScheduler线程根据请求属性分类dispatch到不同的Executor线程。
-
Executor线程将会保存这个CallRunner实例到队列。
-
每一个Executor队列都被绑定了指定个数的Handler线程进行消费,消费很简单,即拿出队列的CallRunner实例,执行器run()方法。
-
run()方法将会组装response到Responder线程中。
-
Responder线程将会不断地将不同Channel的结果返回到客户端。
2. 代码梳理
总体来说服务端RPC处理机制是一个生产者消费者模型。
2.1 组件初始化
-
RpcServer是在master或者regionserver启动时候进行初始化的,关键代码如下:
public HRegionServer(Configuration conf, CoordinatedStateManager csm)
throws IOException, InterruptedException {
this.fsOk = true;
this.conf = conf;
checkCodecs(this.conf);
.....
rpcServices.start();
.....
}
-
/** Starts the service. Must be called before any calls will be handled. */
@Override
public synchronized void start() {
if (started) return;
......
responder.start();
listener.start();
scheduler.start();
started = true;
}
2.2 客户端API请求接收和包装
Listener通过NIO机制进行端口监听,客户端API连接服务端指定端口将会被监听。
-
Listener对于API请求的接收:
void doAccept(SelectionKey key) throws IOException, OutOfMemoryError {
Connection c;
ServerSocketChannel server = (ServerSocketChannel) key.channel();
?
SocketChannel channel;
while ((channel = server.accept()) != null) {
try {
......
// 当一个API请求过来时候将会打开一个Channel,Listener将会分配一个Reader注册。
// reader实例个数有限,采取顺序分配和复用,即一个reader可能为多个Channel服务。
Reader reader = getReader();
try {
reader.startAdd();
SelectionKey readKey = reader.registerChannel(channel);
// 同时也将保存这个Channel,用于后续的结果返回等
c = getConnection(channel, System.currentTimeMillis());
readKey.attach(c);
synchronized (connectionList) {
connectionList.add(numConnections, c);
numConnections++;
......
}
}
上述中Reader个数是有限的并且可以顺序复用的,个数可以通过如下参数进行设定,默认为10个。
this.readThreads = conf.getInt("hbase.ipc.server.read.threadpool.size", 10);
当生产能力不足时,可以考虑增加此配置值。
-
Reader读取请求并包装请求
当Reader实例被分配到一个Channel后,它将读取此通道过来的请求,并包装成CallRunner用于调度。
void doRead(SelectionKey key) throws InterruptedException {
......
try {
// 此时将调用connection的读取和处理方法
count = c.readAndProcess();
......
}
}public int readAndProcess() throws IOException, InterruptedException {
......
// 通过connectionPreambleRead标记为判断此链接是否为新连接,如果是新的那么需要读取
// 头部报文信息,用于判断当前链接属性,比如是当前采取的是哪种安全模式?
if (!connectionPreambleRead) {
count = readPreamble();
if (!connectionPreambleRead) {
return count;
}
......
?
count = channelRead(channel, data);
if (count >= 0 && data.remaining() == 0) { // count==0 if dataLength == 0
// 实际处理请求,里面也会根据链接的头报文读取时候判断出的两种模式进行不同的处理。
process();
}
?
return count;
}private void process() throws IOException, InterruptedException {
......
if (useSasl) {
// Kerberos安全模式
saslReadAndProcess(data.array());
} else {
// AuthMethod.SIMPLE模式
processOneRpc(data.array());
}
.......
}如下以AuthMethod.SIMPLE模式为例进行分析:
private void processOneRpc(byte[] buf) throws IOException, InterruptedException {
if (connectionHeaderRead) {
// 处理具体请求
processRequest(buf);
} else {
// 再次判断链接Header是否读取,未读取则取出头报文用以确定请求的服务和方法等。
processConnectionHeader(buf);
this.connectionHeaderRead = true;
if (!authorizeConnection()) {
throw new AccessDeniedException("Connection from " + this + " for service "
connectionHeader.getServiceName() + " is unauthorized for user: " + user);
}
}
}protected void processRequest(byte[] buf) throws IOException, InterruptedException {
long totalRequestSize = buf.length;
......
// 这里将会判断RpcServer做接收到的请求是否超过了maxQueueSize,注意这个值为
// RpcServer级别的变量
if ((totalRequestSize + callQueueSize.get()) > maxQueueSize) {
final Call callTooBig =
new Call(id, this.service, null, null, null, null, this,
responder, totalRequestSize, null);
ByteArrayOutputStream responseBuffer = new ByteArrayOutputStream();
setupResponse(responseBuffer, callTooBig, new CallQueueTooBigException(),
"Call queue is full on " + getListenerAddress() +
", is hbase.ipc.server.max.callqueue.size too small?");
responder.doRespond(callTooBig);
return;
}
......
Call call = new Call(id, this.service, md, header, param, cellScanner, this, responder,
totalRequestSize,
traceInfo);
// 此时请求段处理结束,将请求包装成CallRunner后发送到不同的Executer的队列中去。
scheduler.dispatch(new CallRunner(RpcServer.this, call, userProvider));
}注意这个值为 RpcServer级别的变量,默认值为1G,超过此阈值将会出现Call queue is full错误。
callQueueSize的大小会在请求接收的时候增加,在请求处理结束(调用完毕CallRunner的run方法后)减去相应值。
this.maxQueueSize =this.conf.getInt("hbase.ipc.server.max.callqueue.size",DEFAULT_MAX_CALLQUEUE_SIZE);
2.3 请求转发与调度
客户端请求在经过接收和包装为CallRunner后将会被具体的Scheduler进行dispatch,master和regionserver
调度器并不相同,这里以regionserver的调度器进行讲解。具体为:SimpleRpcScheduler。
public RSRpcServices(HRegionServer rs) throws IOException {
......
RpcSchedulerFactory rpcSchedulerFactory;
try {
Class<?> rpcSchedulerFactoryClass = rs.conf.getClass(
REGION_SERVER_RPC_SCHEDULER_FACTORY_CLASS,
SimpleRpcSchedulerFactory.class);
rpcSchedulerFactory = ((RpcSchedulerFactory) rpcSchedulerFactoryClass.newInstance());
-
请求转发
前面已经提到请求包装完CallRunner后由具体的RpcScheduler实现类的dispacth方法进行转发。
具体代码为:
-
执行器介绍-队列初始化
在此调度器中共分为三个级别的调度执行器:
-
高优先请求级执行器
-
一般请求执行器
-
replication请求执行器
private final RpcExecutor callExecutor;
private final RpcExecutor priorityExecutor;
private final RpcExecutor replicationExecutor;
上述中callExecutor为最主要一般请求执行器,在当前版本中此执行器中可以将读取和写入初始化为不同比例的队列,并将handler也分成不同比例进行队列的绑定。即一个队列上面只有被绑定的handler具体处理权限。默认的不划分读写分离的场景下就只有一个队列,所有请求都进入其中,所有的handler也将去处理这个队列。
具体我们以读写分离队列为例进行代码分析:
float callQueuesHandlersFactor = conf.getFloat(CALL_QUEUE_HANDLER_FACTOR_CONF_KEY, 0);
int numCallQueues = Math.max(1, (int)Math.round(handlerCount * callQueuesHandlersFactor));
?
LOG.info("Using " + callQueueType + " as user call queue, count=" + numCallQueues);
?
if (numCallQueues > 1 && callqReadShare > 0) {
// multiple read/write queues
if (callQueueType.equals(CALL_QUEUE_TYPE_DEADLINE_CONF_VALUE)) {
CallPriorityComparator callPriority = new CallPriorityComparator(conf, this.priority);
// 实例化RW读取执行器,构造参数中的为读写比例,其中读取又分为一般读取和scan读取比例
// 后续将会调用重载的其他构造方法,最终将会计算出各个读取队列的个数和handler的比例数
callExecutor = new RWQueueRpcExecutor("RW.default", handlerCount, numCallQueues,
callqReadShare, callqScanShare, maxQueueLength, conf, abortable,
BoundedPriorityBlockingQueue.class, callPriority);
} else { -
如下为最终调用的重载构造方法:
public RWQueueRpcExecutor(final String name, int writeHandlers, int readHandlers,
int numWriteQueues, int numReadQueues, float scanShare,
final Class<? extends BlockingQueue> writeQueueClass, Object[] writeQueueInitArgs,
final Class<? extends BlockingQueue> readQueueClass, Object[] readQueueInitArgs) {
super(name, Math.max(writeHandlers, numWriteQueues) + Math.max(readHandlers, numReadQueues));
int numScanQueues = Math.max(0, (int)Math.floor(numReadQueues * scanShare));
int scanHandlers = Math.max(0, (int)Math.floor(readHandlers * scanShare));
if ((numReadQueues - numScanQueues) > 0) {
numReadQueues -= numScanQueues;
readHandlers -= scanHandlers;
} else {
numScanQueues = 0;
scanHandlers = 0;
}
// 确定各个主要队列参数
this.writeHandlersCount = Math.max(writeHandlers, numWriteQueues);
this.readHandlersCount = Math.max(readHandlers, numReadQueues);
this.scanHandlersCount = Math.max(scanHandlers, numScanQueues);
this.numWriteQueues = numWriteQueues;
this.numReadQueues = numReadQueues;
this.numScanQueues = numScanQueues;
this.writeBalancer = getBalancer(numWriteQueues);
this.readBalancer = getBalancer(numReadQueues);
this.scanBalancer = getBalancer(numScanQueues);
queues = new ArrayList<BlockingQueue<CallRunner>>(writeHandlersCount + readHandlersCount);
LOG.debug(name + " writeQueues=" + numWriteQueues + " writeHandlers=" + writeHandlersCount +
" readQueues=" + numReadQueues + " readHandlers=" + readHandlersCount +
((numScanQueues == 0) ? "" : " scanQueues=" + numScanQueues +
" scanHandlers=" + scanHandlersCount));
// 初始化队列列表,注意queues为有序列表,如下队列位置初始化后不会变动,在后续按照具体的请求
// 通过具体的getBalancer方法进行查找
for (int i = 0; i < numWriteQueues; ++i) {
queues.add((BlockingQueue<CallRunner>)
ReflectionUtils.newInstance(writeQueueClass, writeQueueInitArgs));
}
for (int i = 0;